
This is a follow up to the following report that deals with improving retrievers by training and fine-tuning reranker models
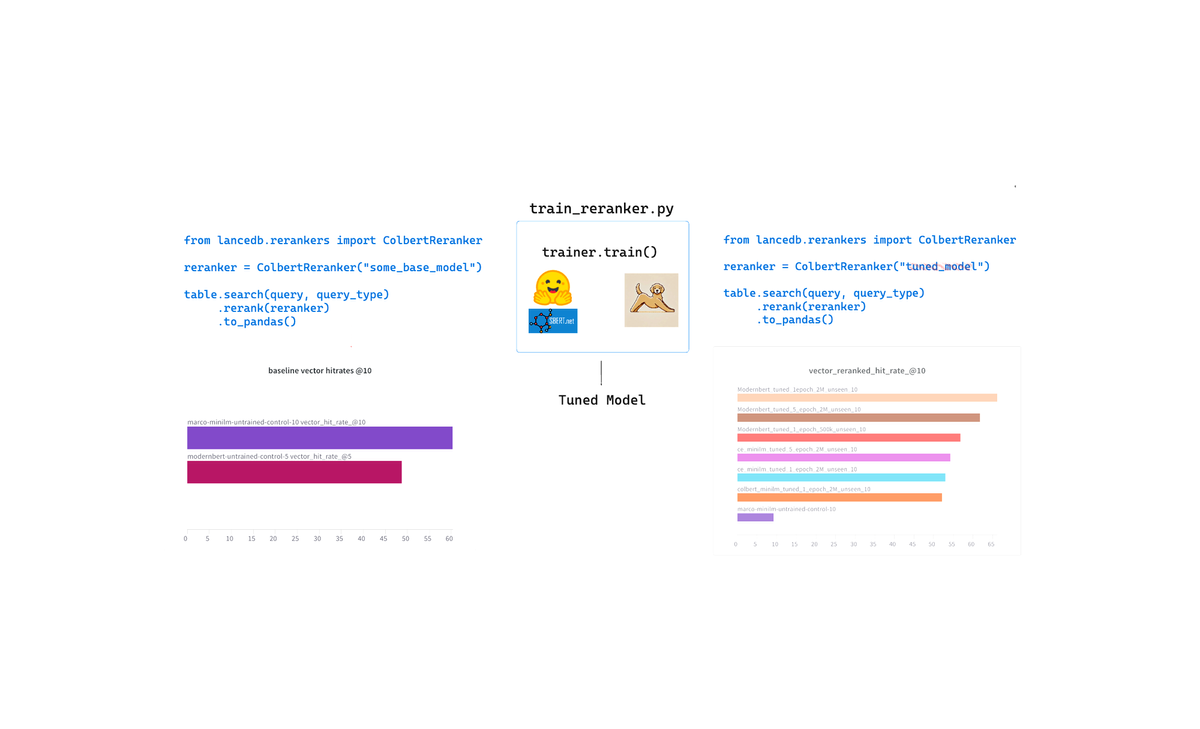
In this report, we try to answer questions like - If/when should you fine-tune embedding models, and what are the qualities of a good fine-tuning dataset
We'll deal with embedding part of the retrieval pipeline, which means any changes or updates will require re-ingestion of the data, unlike reranking.

Tuning embedding models
For this report, the sentence-transformers Python library used to fine-tune embedding models, the same as the previous reranking report.
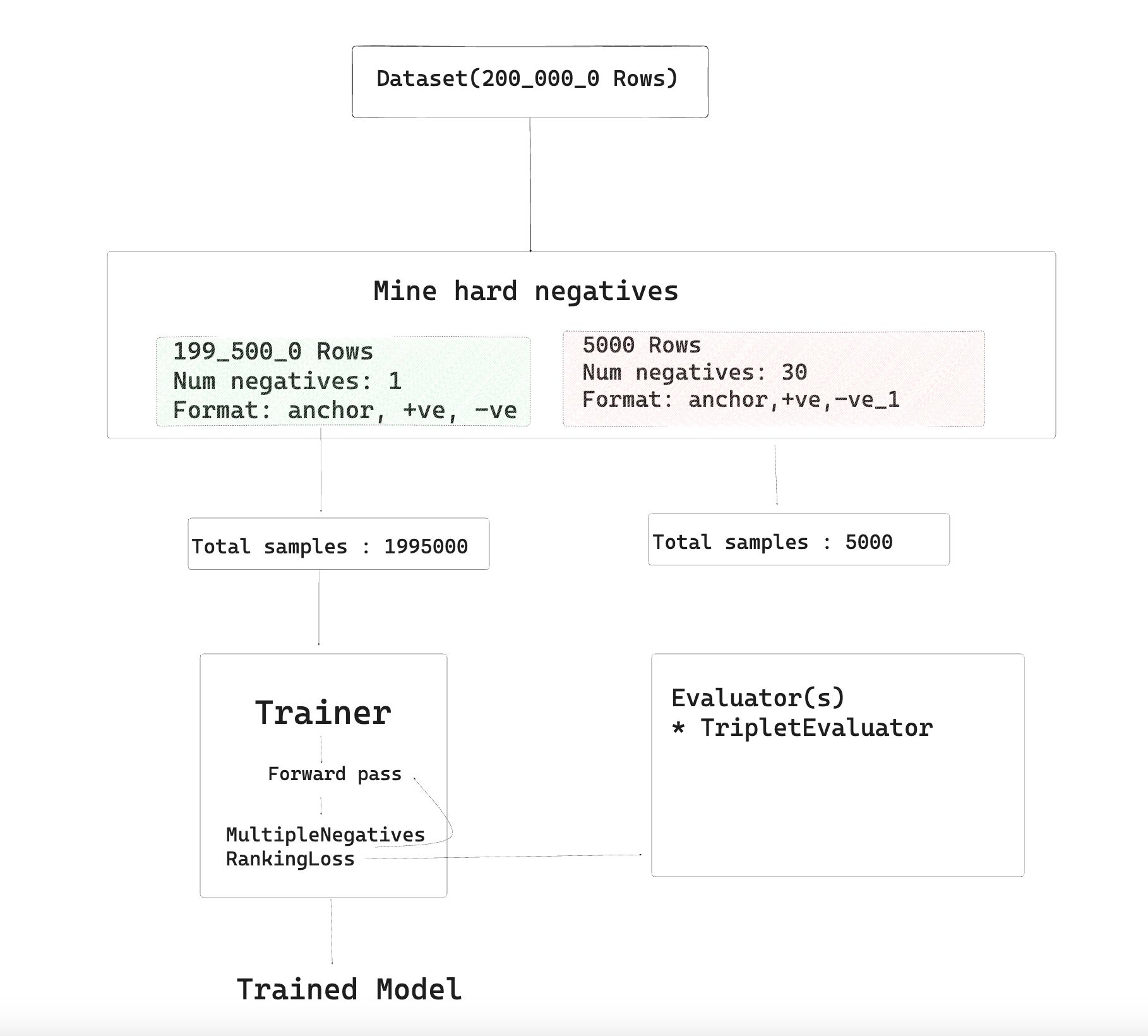
You can refer to the guide to fine-tuning and training embedding models using sentence-transformers here. In brief, the training process happens in the following steps:
- Choose a dataset. We're using GooQA dataset's
questionandcontextcolumns - Mine hard negatives to transform it into a similarity dataset of triplets formats (anchor, positive, negative)
- Repeat the same process for evaluation set
- Choose a loss function for your dataset format. Here we'll use
MultipleNegativesLoss - Choose a suitable evaluator based on your dataset format. Here we'll use
TripletEvaluator - Finally, run the training loop for the desired iterations/epochs.
Base model - The base model used is all-MiniLM-L6-v2 as it was the model used for embedding generation in the Rerankers report as well.
Fine-tuning Results
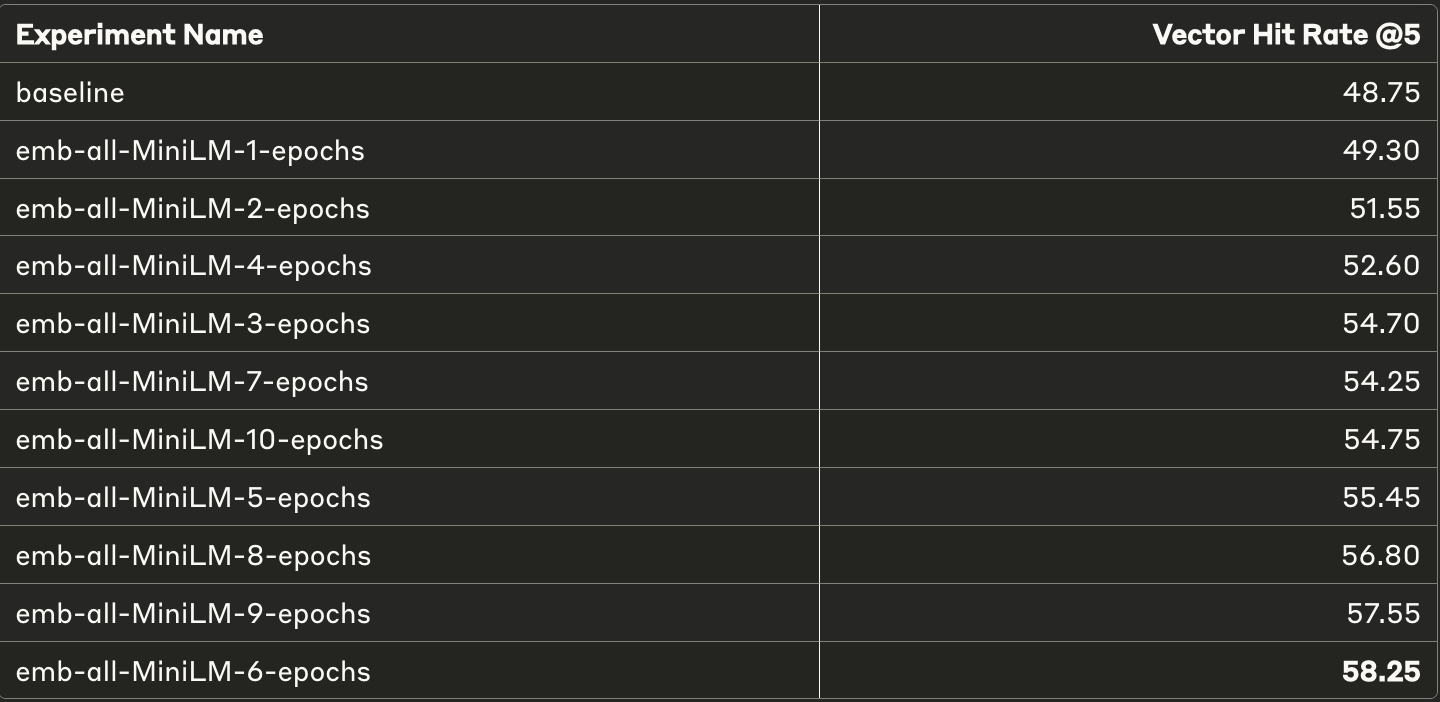
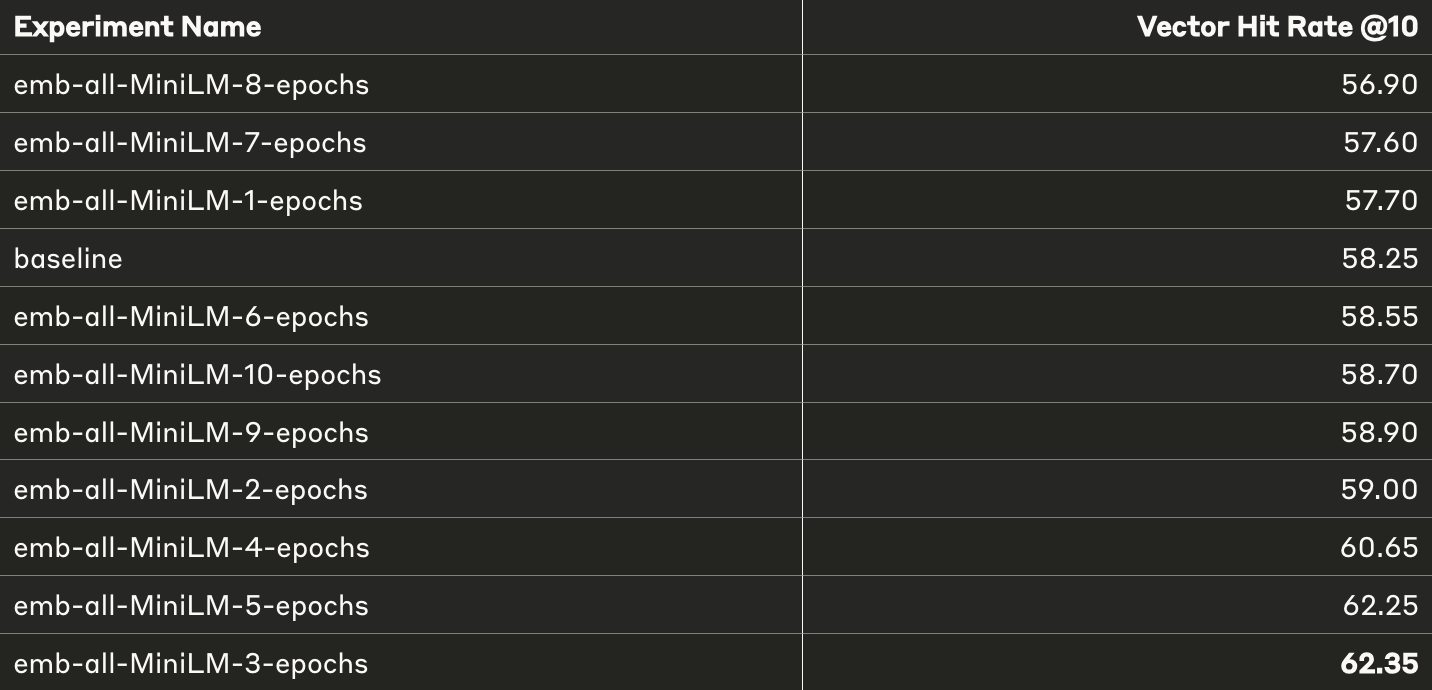
Here are the results of fine-tuning the model as described in the previous section.
Hit rate @5
Hit rate @10

- Overall, we see improvements of roughly 10% across both top 5 and top 10
- The main thing to notice here is that each fine-tuned model performs significantly better than the baseline
- Increasing the number of iterations generally tends to improve the results further, which is expected.
- Towards the end, where the model is trained for larger epochs (10), it starts to show some signs of unstable training or overfitting, which, again, is expected.
Should you always fine-tune embedding models?
The most important question at this point is if we can generalize these results, i.e, should you always fine-tune your embedding models if you can?
Fine-tuning is like training. The only difference is that when training a model, you start with random or close-to-random weights that output gibberish. When fine-tuning, you start with a model already trained on some different dataset or combination of datasets.
Let's look at another example.
Experiment setup
- Model - all-MiniLM-L6-v2 ( same as before)
- Dataset - SQuAD. The dataset has ~90K rows. For this experiment, I used 45K rows for the training set and 5K for the evaluation set. The format and loss functions used were the same as the ones used in GooQA dataset fine-tuning.
- In contrast to previous experiment, the dataset is much smaller (2M rows vs 45K rows)
Ideal scenario for fine-tuning
Another thing to note about the dataset is that both of these datasets are general QA datasets, i.e., they're not specialized domain-specific query-context pairs. SQuAD is a popular dataset that most embedding models use as a part of their larger training set.
Here's the visualization of the training dataset and fine-tuning dataset.
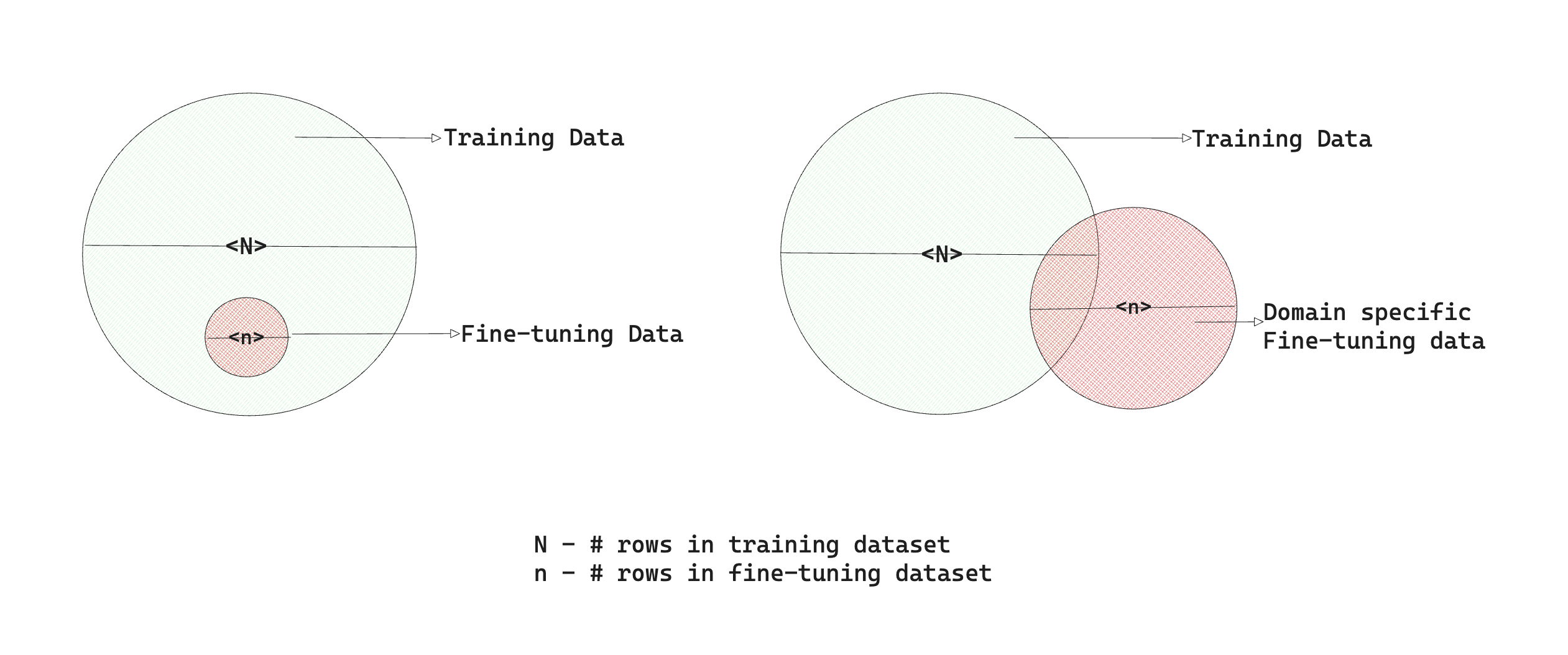
An educated guess would be to associate fine-tuning on
- SQuAD dataset as the left representation.
- In this case, you're fine-tuning the model on the subset of data it has already seen without adding any new information.
- This can result in unstable training, overfitting, catastrophic forgetting or just some sudden performance degradation depending on the training process
- It is generally not recommended to fine-tune in such scenarios. Evaluation might initially show good results due to overfitting.
- A large domain-specific dataset as the right representation.
- You can think of legal docs or financial reports/filings, etc., as a large domain-specific corpus that might have a small intersection with the larger general training data.
- It is recommended to fine-tune models on such datasets as it allows the model to adapt to a new domain, specializing in answering those questions with better context or more confidence.
- GooQA dataset as somewhere between the left and the right representation.
- GooQA is much larger than SQuAD, yet it is a general QA dataset without any domain specifications.
- Training on this dataset should be much more stable than SQuAD, and you can fine-tune on such datasets if you expect future user queries to be limited to the same distribution. In the real world, the chance of this happening is quite low.
SQuAD fine-tuning results
Here's what happens if you fine-tune on a dataset that's similar to the representation on the left
hit rate @5

Hit rate @ 10
The results seem aligned with our analysis in the previous section:
- The delta in improvement is much smaller.
- The model starts to overfit much faster. In fact, in most cases with a high number of epochs, the results get worse. In the case of hit-rate@10, only 3 models perform better than the baseline.
Let's run another experiment that fine-tunes a much larger model on this dataset, to confirm our hypothesis. Here's the top@5 and top@10 hit-rates on both All-miniLM-L6-v2 and bge-1.5-en-base with all results sorted for easier comparison

The results in both experiments seem aligned. Both models overfit at higher epochs, and training is pretty unstable.
What about augmentation and synthetic data generation?
LLMs have lately been used to generate synthetic questions and answers from a given passage/context to fine-tune embedding models. Can't we just use those techniques to augment the dataset in this scenario?
There are 2 major things to keep in mind before attempting synthetic data generation.
- Augmentation improves the dataset by creating slightly different versions of existing data points. It doesn't necessarily add a lot of new context to your dataset distribution. For example, when training vision models, data augmentation takes an image and randomly crops parts of it or rotates it by certain angles to create new samples. It basically prevents the model from overfitting to a specific angle, position, etc. It doesn't really add any new information about a new class object. So, the rule of thumb to follow in data augmentation is: Bad data, on augmentation, will most likely result in bad or worse augmented data.
- LLMs hallucinate. When generating synthetic datasets (questions from context) from existing dataset, it has been found that a large portion of generated questions can be hallucinations or simply of bad quality questions. In fact, there are many tools that are used to filter out hallucinations from the synthetic data generation process.
So although you can experiment with synthetic data generation, and it also is a very powerful tool to augment good quality datasets, it is not a magical solution if you don't have a decent base dataset.

Fine-tuned embedder + reranker?
Now coming back to the GooQA dataset experiment results. We saw significant improvement in the results even though the dataset was pretty general, which isn't the best case for fine-tuning. But can we do better? Let's revisit our experiment results from the previous report that dealt with training and fine-tuning reranker models. Here's the best result that we got after fine-tuning an existing reranker.
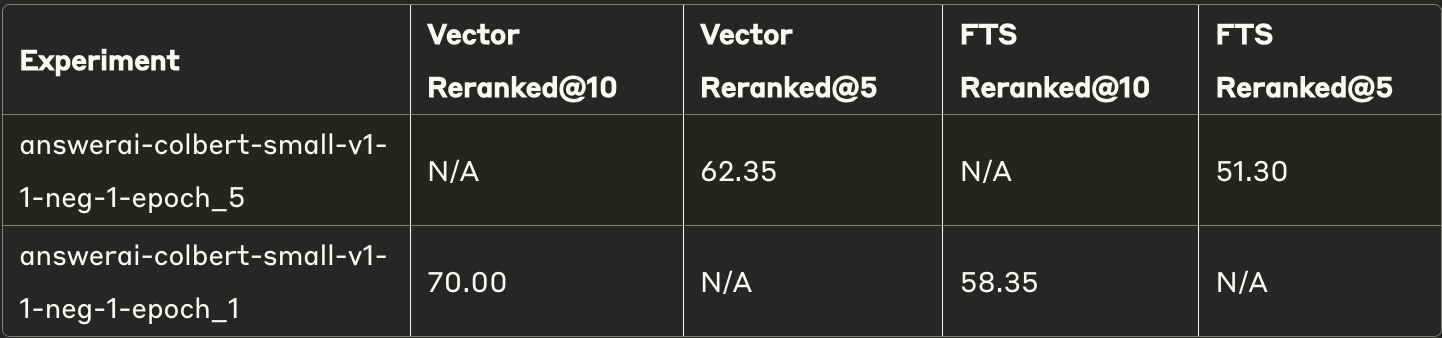
The best results were 70% @top10 and 62.35% @top5 respectively
You can read the entire report here for more details on reranking process and tradeoffs:
Can we improve the results further by combining our fine-tuned embedding models with the best rerankers @top 5 and top 10? Here are the results (FTS column is irrelevant as FTS doesn't involve embedding models)
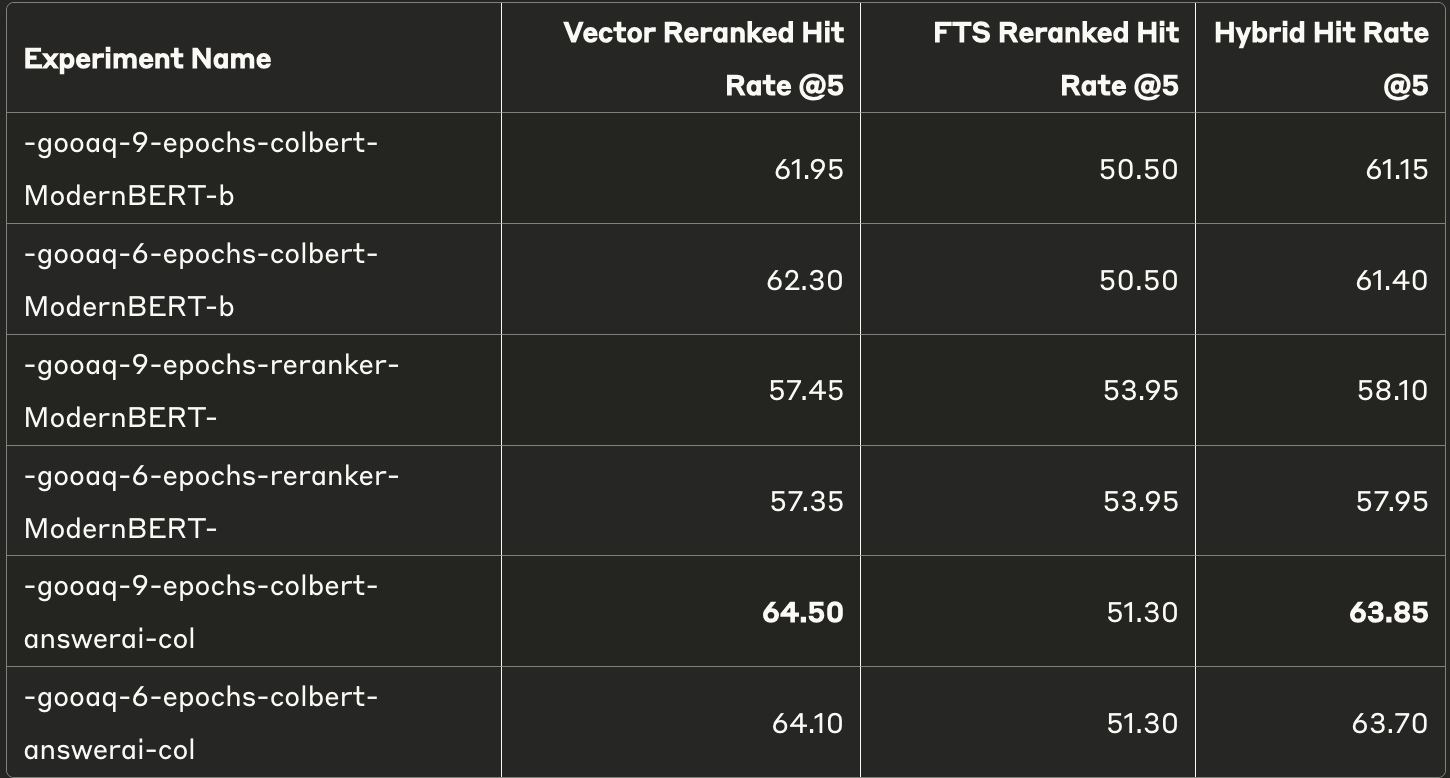
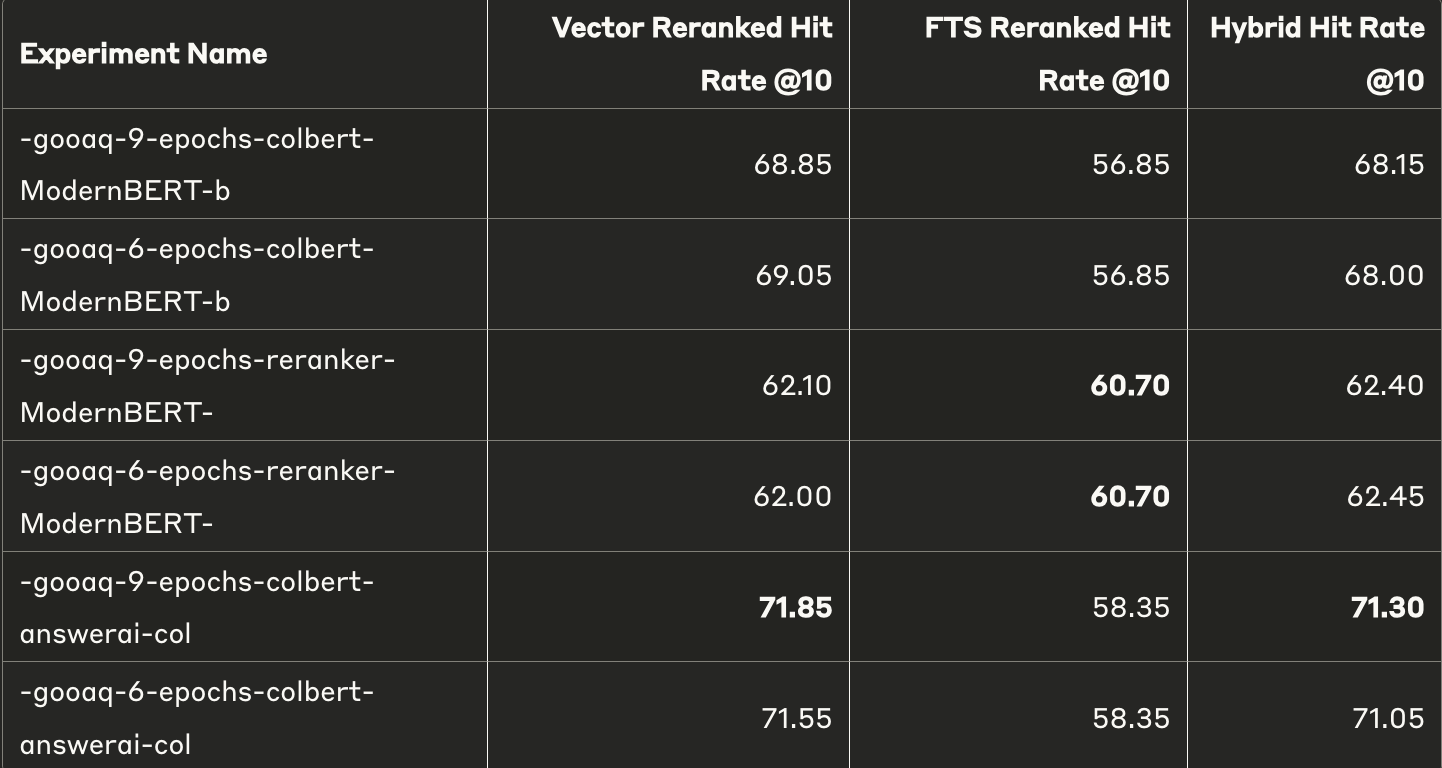
On combining fine-tuning with reranking, we get new best results:

Top 5 - 62.34 -> 64.50
Top 10 - 70.00 -> 71.85
Using embedding functions with LanceDB
LanceDB has integrations with all popular embedding model providers. With the embedding API, you can simply define the embedding model of your choice when initializing the table, and it'll automatically take care of generating embeddings for both source and queries. Here's an example
import lancedb
from lancedb.embeddings import get_registry
from lancedb.pydantic import LanceModel, Vector
model = get_registry().get("sentence-transformers").create() # use default ST model
# define schema with embedding API
class Schema(LanceModel):
text: str = model.SourceField() # All entries of sourcefield are vectorized
vector: Vector(model.ndims()) = model.VectorField
db = lancedb.connect("~/lancedb")
table = db.create_table(schema=Schema, name="tbl")
table.add(
[
{"text": "some random text"},
{"text": "some random text again"}
]
) # Source field automatically gets converted to their vector embeddings
table.search("search text")
# You can directly pass string as it'll be
# converted to embeddings as we've initialized
# the schema with embedding APIUsing a custom fine-tuned embeddings is as simple as passing the model name when initializing model from embedding registry
tuned_model = get_registry().get("sentence-transformers").create(
name="path/to/tuned_model")Reproducibility
All code to reproduce the above experiments are available here
All trained models used in this experiment are available of HF hub