
Traditional LLMs provide answers based on a fixed knowledge database on which they are trained. This limits their ability to respond with current or specific information. While methods like Retrieval-Augmented Generation (RAG) try to solve this by combining LLMs with external data retrieval, they need additional help to handle queries of different complexities effectively.
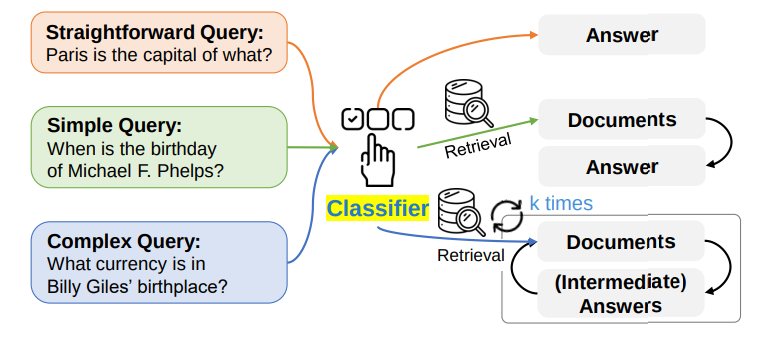
Adaptive RAG presents a method that chooses the best strategy for answering questions, from a direct LLM response to single or multiple retrieval steps. This selection is based on the query’s complexity, as determined by a classifier. The 3 strategies for answering are:
- Direct LLM Response: For simple questions, it uses the LLM’s own stored knowledge to provide quick and direct answers without seeking external information.
- Single-Step Retrieval: For moderately complex questions, it retrieves information from a single external source, ensuring the answer is both swift and well-informed.
- Multi-Step Retrieval: For highly complex questions, it consults multiple sources, piecing together a detailed and comprehensive answer.
Why is Adaptive-RAG effective?
The flexibility of Adaptive-RAG ensures that each query is handled efficiently, using the most appropriate resources. This saves computational resources and improves user experience by delivering precise and timely answers.
Moreover, the ability of Adaptive-RAG to adapt based on the complexity of the question means it can provide more current, specific, and reliable information. This adaptability significantly reduces the chances of outdated or generic answers.
Accuracy Enhancement
The accuracy of Adaptive-RAG is unparalleled, thanks to its ability to discern and adapt to the complexity of each query. By dynamically aligning the retrieval strategy with the query’s needs, Adaptive-RAG ensures that responses are not only relevant but also incorporate the most up-to-date information available. This adaptiveness significantly reduces the likelihood of outdated or overly generic answers, setting a new standard for accuracy automated question-answering.
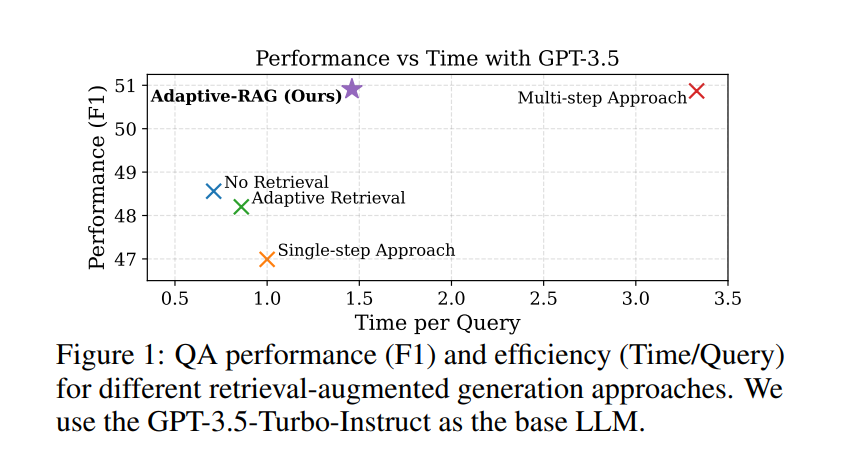
The image below shows the comparison of different RAG approaches & adaptive rag is in terms of speed & performance
Let's create RAG app based on the discussed strategy.
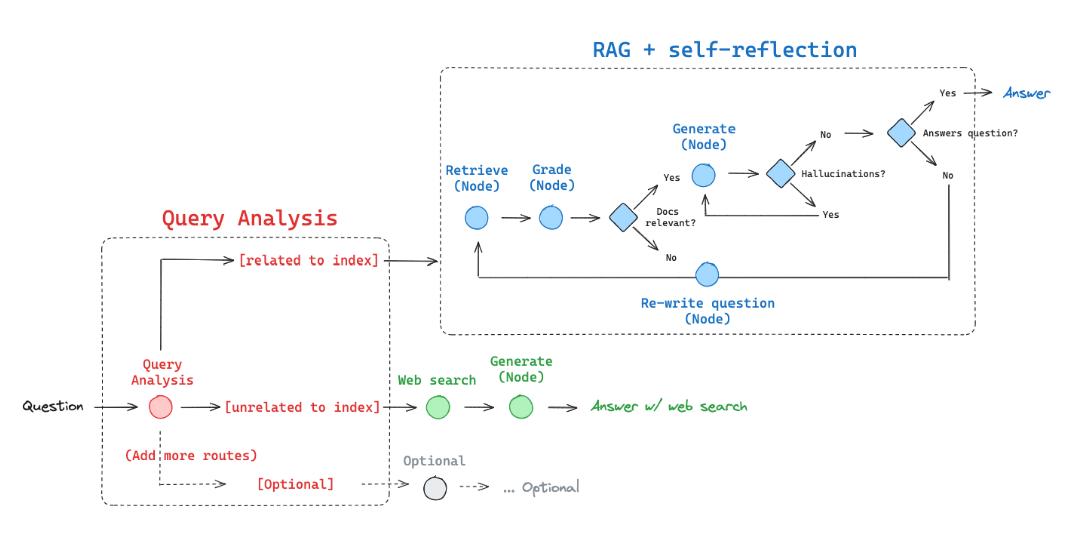
Our RAG application is structured to route user queries to the most relevant data source, depending on the nature of the query. Here’s how we’ve set it up:
- Web Search: This route is selected for questions related to recent events, utilizing the Tavily Search API for real-time information retrieval.
- Self-Corrective RAG: For more specialized queries that pertain to our indexed data, we use a self-corrective mechanism that leverages our own curated knowledge base.
implementation Details:
- Indexing Documents: We begin by indexing documents using LanceDB, a vector database within the LangChain suite. This setup allows us to quickly retrieve relevant documents based on the user’s query.
- Routing: The core of our application involves routing each user query to the most appropriate data source — either our web search interface or the internal vector database.
- Retrieval Grader: We then employ a retrieval grader that evaluates whether the documents retrieved are relevant to the query, providing a binary “yes” or “no” score.
- Generation: For generating responses, we pass the prompt, language model (LLM), and retrieval data from the vector database to construct a coherent and contextually appropriate output.
- Hallucination Grader: To ensure the authenticity of the information provided, a hallucination grader assesses whether the generated answer is factually grounded, again offering a binary score.
- Answer Grader: Additionally, an answer grader evaluates whether the response adequately addresses the user’s question.
- Question Rewriter: This component enhances query effectiveness by rewriting the input question into a format optimized for retrieval from the vectorstore.
- Graph Representation using langgraph : Lastly, we use LangGraph to visually map out the flow and connections within our application, defining nodes and constructing a graph that represents the entire process.
For those interested in the inner workings of our adaptive response generation system, please refer to our Vector Recipe repository, which contains detailed code examples. Below, I will discuss a few examples illustrating how the Adaptive rag working
Example 1: General Knowledge Query
Query: “Who is the prime minister of India?”
This example demonstrates how the system processes a general knowledge question related to web-based information.
# Run
inputs = {"question": "Who is prime minister of india?"}
for output in app.stream(inputs):
for key, value in output.items():
# Node//
pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint("\n---\n")
# Final generation
pprint(value["generation"])output:
—ROUTE QUESTION---
---ROUTE QUESTION TO WEB SEARCH---
---WEB SEARCH---
"Node 'web_search':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
'---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---'
"Node 'generate':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'\n---\n'
('Narendra Modi is the Prime Minister of India. He has been in office since '
'2014 and was reelected for a second term in 2019.')
In this scenario, the system successfully finds the answer through a web search node, as shown:
- Routing Question: Direct the query to the appropriate node.
- Web Search: Fetch relevant information.
- Check for Accuracy: Ensure the information is accurate and not based on false data (hallucinations).
- Final Decision: Confirm the information answers the query correctly.
- Result: “Narendra Modi is the Prime Minister of India. He has been in office since 2014 and was reelected for a second term in 2019.”
example 2:
from pprint import pprint
# Run
inputs = {"question": "What is generative agents ?"}
for output in app.stream(inputs):
for key, value in output.items():
# Node//
pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint("\n---\n")
# Final generation
pprint(value["generation"])Output:
—ROUTE QUESTION---
---ROUTE QUESTION TO RAG---
---RETRIEVE---
TAKING DICSNEW BRO...>>>>>>>>
"Node 'retrieve':"
'\n---\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
"Node 'grade_documents':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'\n---\n'
('Generative agents are virtual characters controlled by LLM-powered agents '
'that simulate human behavior in interactive applications. These agents '
'combine LLM with memory, planning, and reflection mechanisms to interact '
'with each other based on past experiences. The design includes a memory '
'stream, retrieval model, reflection mechanism, and planning & reacting '
"components to inform the agent's behavior.")
The system routes the question to the RAG (Retrieval-Augmented Generation) system and retrieves relevant documents to generate an accurate response.
- Routing and Retrieval: Identify and fetch relevant data.
- Document Relevance Check: Assess each document’s relevance to the query.
- Response Generation: Create an answer based on the most relevant documents.
- Accuracy Check: Confirm the generation is grounded in factual documents.
- Result: “Generative agents are virtual characters controlled by LLM-powered agents that simulate human behavior in interactive applications. These agents combine LLM with memory, planning, and reflection mechanisms to interact with each other based on past experiences. The design includes a memory stream, retrieval model, reflection mechanism, and planning & reacting components to inform the agent’s behavior.”
Due to the complexity of the code, I have attached a link to a Google Colaboratory notebook where you can explore and execute the code yourself.


Conclusion
In this blog, we've explored the capabilities of Adaptive-RAG for question-answering tasks, illustrating its remarkable efficiency and precision. Through detailed examples, we demonstrated how Adaptive-RAG dynamically adjusts its approach based on the complexity of the query, ensuring optimal use of computational resources while delivering precise and timely answers.
The flexibility and accuracy of Adaptive-RAG set a new standard in automated response generation, offering more reliable and up-to-date information. This adaptability makes it an invaluable tool for handling a wide range of queries, from simple factual questions to complex informational needs.
Checkout vector-recipes for other examples and insights into the practical applications of GenAI.