
Last week, OpenAI announced its latest LLM, GPT-4o, which follows GPT-4 Turbo. In this blog, we benchmark GPT4-o using a new benchmarking toolkit called "Needle in a Needlestack".
What is OpenAI’s GPT-4o?
GPT-4o (“o” for “omni”) is a step towards much more natural human-computer interaction—it accepts as input any combination of text, audio, image, and video any combination of text, audio, and image outputs. It can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, similar to human response time(opens in a new window) in a conversation.

Check out the OpenAI Spring Update for details about GPT-4o.
Benchmarking
In this blog, we benchmark GPT-4o using the NIAN (Needle in a Needlestack) benchmark.
Needle in a Needlestack is a new benchmark to measure how well LLMs pay attention to information within their context window. NAIN creates a prompt with thousands of limericks(short, humorous verses that are usually nonsensical and consist of five lines rhyming AABBA.) and asks a question about a specific limerick at a particular position.
NIAN evaluates the answers to its questions, which is a challenging task for large language models (LLMs). To ensure accuracy, NIAN employs five different LLMs to assess the responses, determining pass or fail by majority vote. The evaluation process is improved using single or few-shot training techniques.
NIAN includes a tool called answers that identifies every unique answer generated by the LLMs and classifies them with "pass" or "fail" tags based on the majority vote. For variety, I used GPT-3.5, GPT-4, Haiku, and Mistral 7B to generate answers. After examining the responses, I used a few that passed as examples for the evaluators when similar questions previously resulted in failed answers that should have passed.
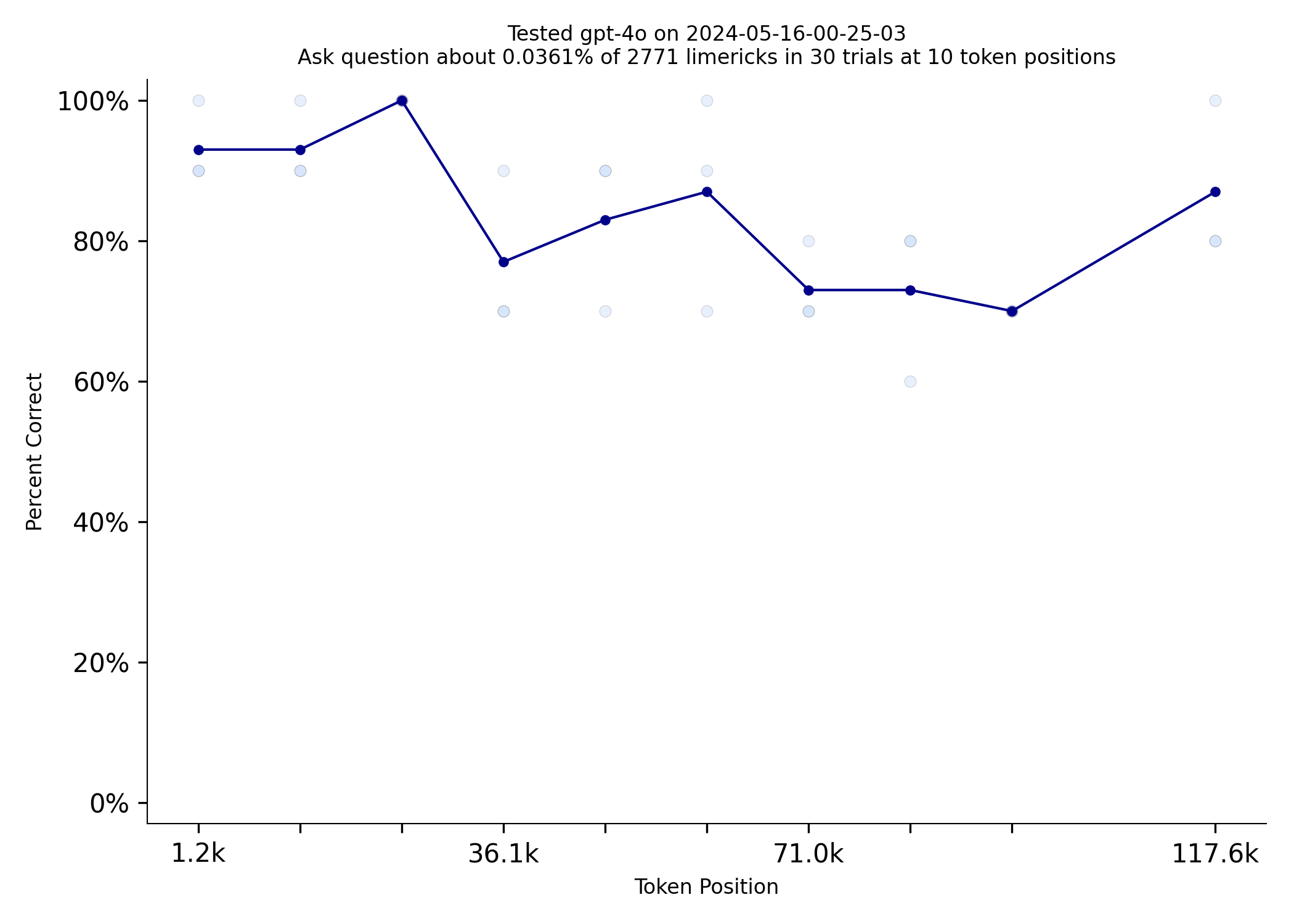
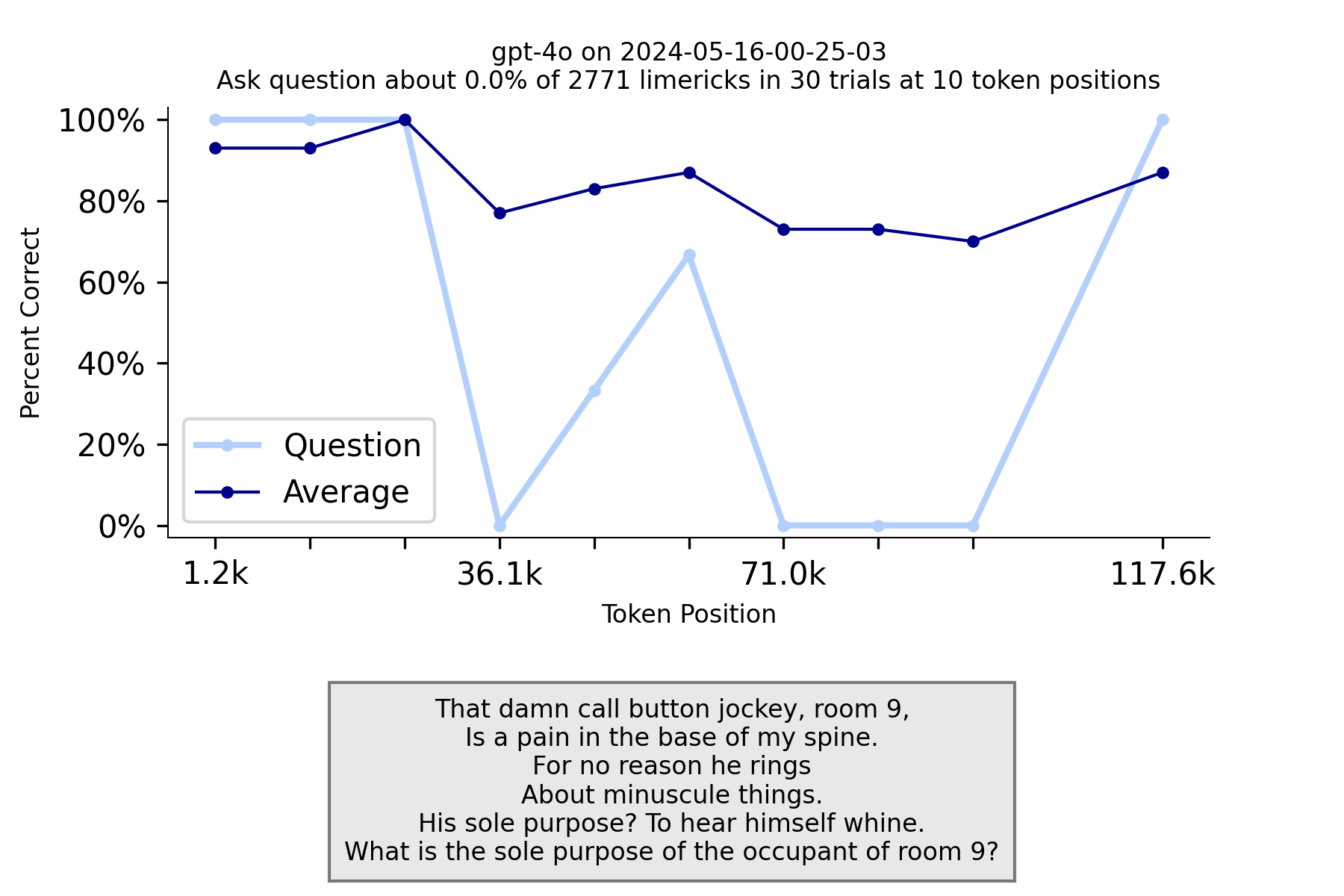
GPT-4o has made a breakthrough and did quite well on this benchmark.
Comparing it with the GPT-4 Turbo benchmark reveals a clear difference in performance between the two models.
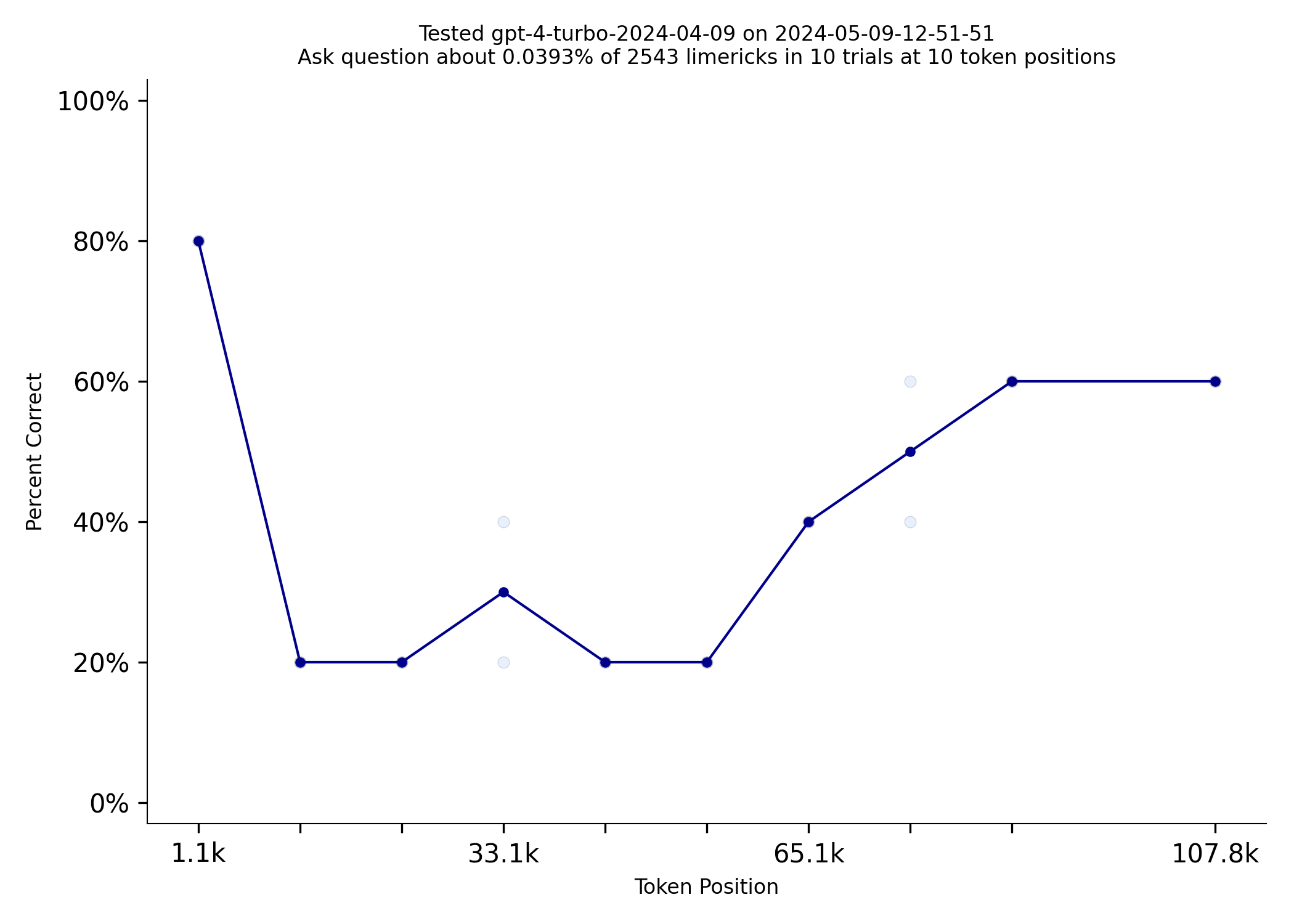
Everyone is curious about when OpenAI will explain the improvements that made GPT-4o much better than GPT-4 Turbo.
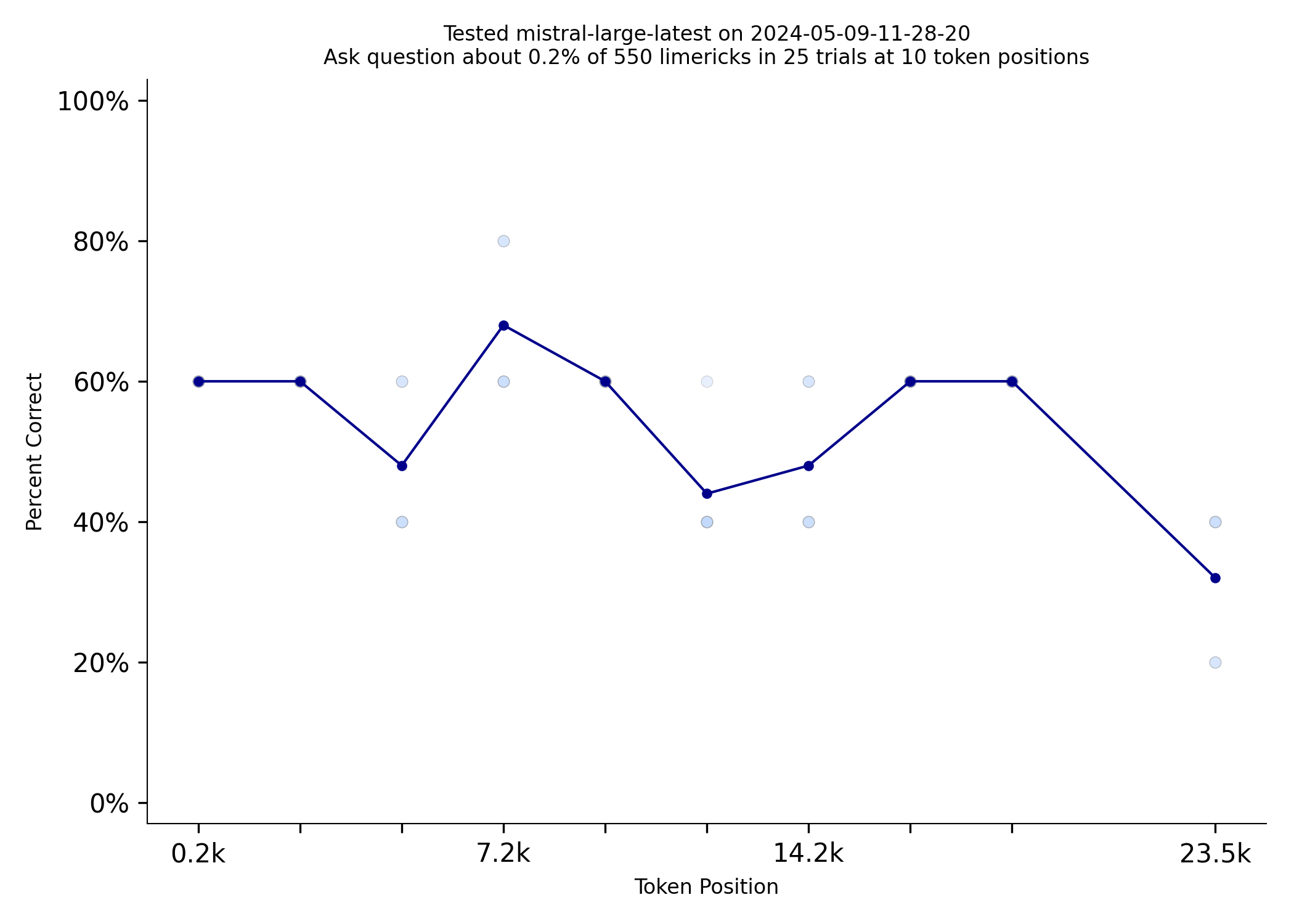
GPT-4o performs better than other LLMs, including Mistral-large, GPT-4-turbo, and Claude-3-sonnet on this benchmark.
NIAN gives very different results depending on the question, so it's important to ask at least five questions. To be sure NIAN isn't just testing how well the LLMs can answer a single question, the vet tool asks various models the same question full_questions.json five times. Any question that doesn't get a perfect score is removed.
Conclusion
OpenAI made significant advancements that resulted in GPT-4o being notably superior to GPT-4 Turbo. To guarantee the precision of GPT-4o, NIAN uses five different large language models (LLMs) to evaluate the responses, deciding whether they pass or fail through a majority vote. The evaluation method is enhanced by using single or few-shot training techniques.
Check out the blog on Benchmarking the OpenAI Embedding Model.