
What this looks like:
Quick recap
I recommend reading Part1 before you read Part 2.
Part 1 - https://blog.lancedb.com/rag-codebase-1/
In the previous post, I covered building a question-answering system for codebases, explaining why GPT-4 can't inherently answer code questions and the limitations of in-context learning. I explored semantic code search with embeddings and the importance of proper codebase chunking. I then detailed syntax-level chunking with abstract syntax trees (ASTs) using tree-sitter, demonstrating how to extract methods, classes, constructors, and cross-codebase references.
What to expect in Part 2
Key topics covered in this part:
- Final step for codebase indexing - adding LLM based comments
- Considerations for choosing embeddings and vector databases
- Techniques to improve retrieval (HyDE, BM25, re-ranking)
- Choosing re-rankers; In-depth explanation of re-ranking (bi-encoding vs. cross-encoders)
If you have ever worked with embeddings, you will know that embedding search is not as effective and one needs to follow some additional steps in the retrieval pipeline like HyDE, hybrid vector-search and re-ranking.
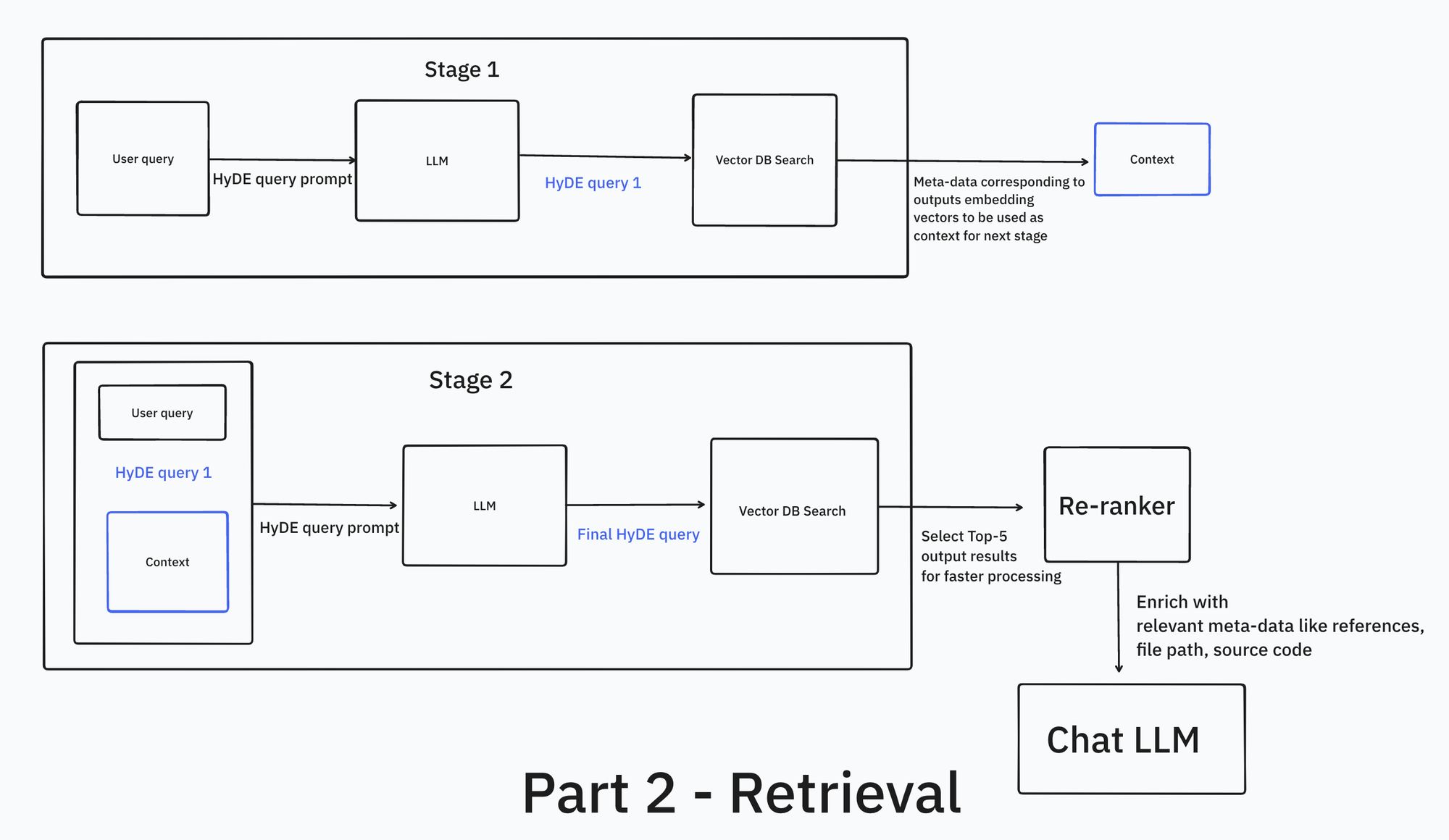
In next few sections, we discuss methods to improve our overall search and the relevant implementation details. Refer to the diagram (CodeQA's retrieval pipeline) for an overview of the building blocks involved.
Adding LLM comments
This is part of codebase indexing too but it felt more in line with part 2.
Implementing LLM comments for methods (optional)
Update: I decided to do away with LLM comments in the current version of codeQA because it slows down the indexing process. The relevant file
llm_comments.py is still there on repo.
Since our queries will be in natural language, I decided to integrate a natural language component by adding 2-3 line documentation for each method. This creates an annotated codebase, with each LLM-generated comment providing a concise overview. These annotations enhance keyword and semantic search, allowing for more efficient searches based on both ‘what the code does’ and ‘what the code is.’
I found a cool blogpost which validated my thoughts later on. I quote them below.
Three LLM tricks that boosted embeddings search accuracy by 37% — Cosine
Meta-characteristic search
One of the core things we wanted to have is for people to be able to search for characteristics of their code which weren't directly described in their code, for example a user might want to search for all generic recursive functions, which would be very difficult if not impossible to search for through conventional string matching/regex and likely wouldn't perform at all well through a simple embedding implementation. This could also be applied to non-code spaces too; a user may want to ask a question of an embedded corpus of Charles Dickens asking find all cases where Oliver Twist is self-reflective which would not really be possible with a basic embedding implementation.
Our solution with Buildt was: For each element/snippet we embed a textual description of the code to get all of the meta characteristics, and we get those characteristics from a fine-tuned LLM. By embedding the textual description of the code alongside the code itself, it allows you to search both against raw code as well as the characteristics of the code, which is why we say you can "search for what your code does, rather than what your code is". This approach works extremely well and without it questions regarding functionality rarely return accurate results. This approach could easily be ported to prose or any other textual form which could be very exciting for large knowledge bases.
There are pitfalls to this approach: it obviously causes a huge amount of extra cost relative to merely embedding the initial corpus, and increases latency when performing the embedding process - so it may not be useful in all cases, but for us it is a worthwhile trade-off as it produces a magical searching experience.
Next section - let's look into embeddings and vectorDB.
Embedding and vectorDB
I use OpenAI's text-embedding-3-large by default as they are very good plus everyone has OpenAI API keys so it's good for demoing. I have also added option for using jina-embeddings-v3 which are better than text-embedding-3-large in benchmarks.
Re: OpenAI embeddings - they are cheap plus have a sequence length of 8191 tokens. Rank 35 on MTEB, multi-lingual and easily accessible via API. Sequence length is important btw because it allows the embedding model to capture long length dependencies and more context.
Things to consider for embeddings
Benchmarks
You can checkout the MTEB leaderboard for embedding ranking with scores. Look at the scores, sequence length, the languages that are supported. Locally available models need your compute so look at size for open source models.
Latency
API-based embeddings can be slower than local ones simply because of network round-trips added latency. So if you want speed and you have the compute, it may be better to use local embeddings.
Cost
If you want free or just experimentation, go open source sentence-transformers . bge-en-v1.5 or nomic-embed-v1 is all you need. Otherwise most closed source embeddings are cheap only.
Use-case
They should serve for your use-case. Research accordingly on Hugging Face or website documentation or their research paper. If you are embedding code, the embeddings you use should have had code in pre-training data.
You can use fine-tuned embeddings to significantly improve your scores. LlamaIndex has a high-level API to fine-tune all Hugging Face embeddings. Jina recently announced a fine-tuning API though I haven't tried it out.
Privacy
Privacy for data is a major concern for several people and companies. For my project, I prioritized performance and chose OpenAI, not considering privacy concerns
I quote a Sourcegraph blogpost here.
While embeddings worked for retrieving context, they had some drawbacks for our purposes. Embeddings require all of your code to be represented in the vector space and to do this, we need to send source code to an OpenAI API for embedding. Then, those vectors need to be stored, maintained, and updated. This isn’t ideal for three reasons:
- Your code has to be sent to a 3rd party (OpenAI) for processing, and not everyone wants their code to be relayed in this way.
- The process of creating embeddings and keeping them up-to-date introduces complexity that Sourcegraph admins have to manage.
- As the size of a codebase increases, so does the respective vector database, and searching vector databases for codebases with >100,000 repositories is complex and resource-intensive. This complexity was limiting our ability to build our new multi-repository context feature.
As an aside, for a deeper understanding of codebase indexing methodologies, I recommend reviewing this blog post. Their approach parallels my implementation but operates at a significantly larger scale. They have developed an AI coding assistant named Cody. It is worth noting that they have since moved away from using embeddings in their architecture.
I recommend reading the blogpost How Cody understands your codebase
VectorDB
I use LanceDB because it’s fast, easy to use - you can just pip install and import, no API key required. They support integration for almost all embeddings (available on Hugging Face) and most major players like OpenAI, Jina etc. There's easy support for integration for rerankers, algorithms, embeddings, third-party libraries for RAG etc.
Things to consider for VDB
- Support for all the integrations you need - e.g LLMs, different companies,
- Recall and Latency
- Cost
- Familiarity/Ease of use
- Open source / closed source
Implementation details
Code for embedding the codebase and making the tables can be found in create_tables.py . I maintain two separate tables - one for methods and other for classes and miscellaneous items like README files. Keeping things separate allows me to query separate metadatas plus separate vector searches; get the closest class, get the closest methods.
If you see the implementation, you will notice I don’t generate embeddings manually. That part is handled by LanceDB itself. I just add my chunks and LanceDB handles all the batch embedding generation with retry logic in the background.
Retrieval
Once we have the tables ready, we can give queries to vectorDB and it will output the most similar documents using brute force search (cosine similarity/dot product). These results are going to be relevant but not as accurate as you think. Embedding search feels like magic until it does not. In my experience with some other projects, the results are relevant but often noisy plus the ordering can be wrong often. I attach a twitter thread below to show some shortcomings.
Relevant Twitter discourse to show some shortcomings.
Improving embedding search
BM25
The first thing to do - is usually combine semantic search with a keyword based search like BM25. I used this in semantweet search. These are supported out of box already by many vectorDBs. In semantweet search, I had used LanceDB which supported hybrid search (semantic search + bm25) out of box, I just had to write some additional code to create a full-text based index using tantivy. Some benchmarks from lancedb site to demonstrate how different methods can impact results.
Recall is how many of the relevant documents are we retrieving / number of documents. It's used to measure search performance.
Filtering using meta-data
Another effective approach to enhance semantic search is to use metadata filtering. If your data contains attributes like dates, keywords, or metrics, you can use SQL to pre-filter the results before performing semantic search. This two-step process can significantly improve search quality and performance. It's important to note that embeddings exist as independent points in latent space, so this pre-filtering step helps narrow down the relevant search space.
Reranking
Using re-rankers after the vector search is an easy way to improve results significantly. In short, re-rankers do a cross-attention between query tokens and embedding search result tokens.
Let’s try to understand how they work on a high level. In CodeQA v2, I use answerdotai/answerai-colbert-small-v1 as it is the best performing local re-ranker model based on benchmarks with performance close to Cohere Re-ranker 3 (which I used in CodeQA v1).
Cross-encoding (re-ranking) vs bi-encoding (embeddings based search)
Embeddings are obtained from models like GPT-3 → decoder-only transformer
or BERT (encoder-only transformer, BERT base is 12 encoders stacked together).
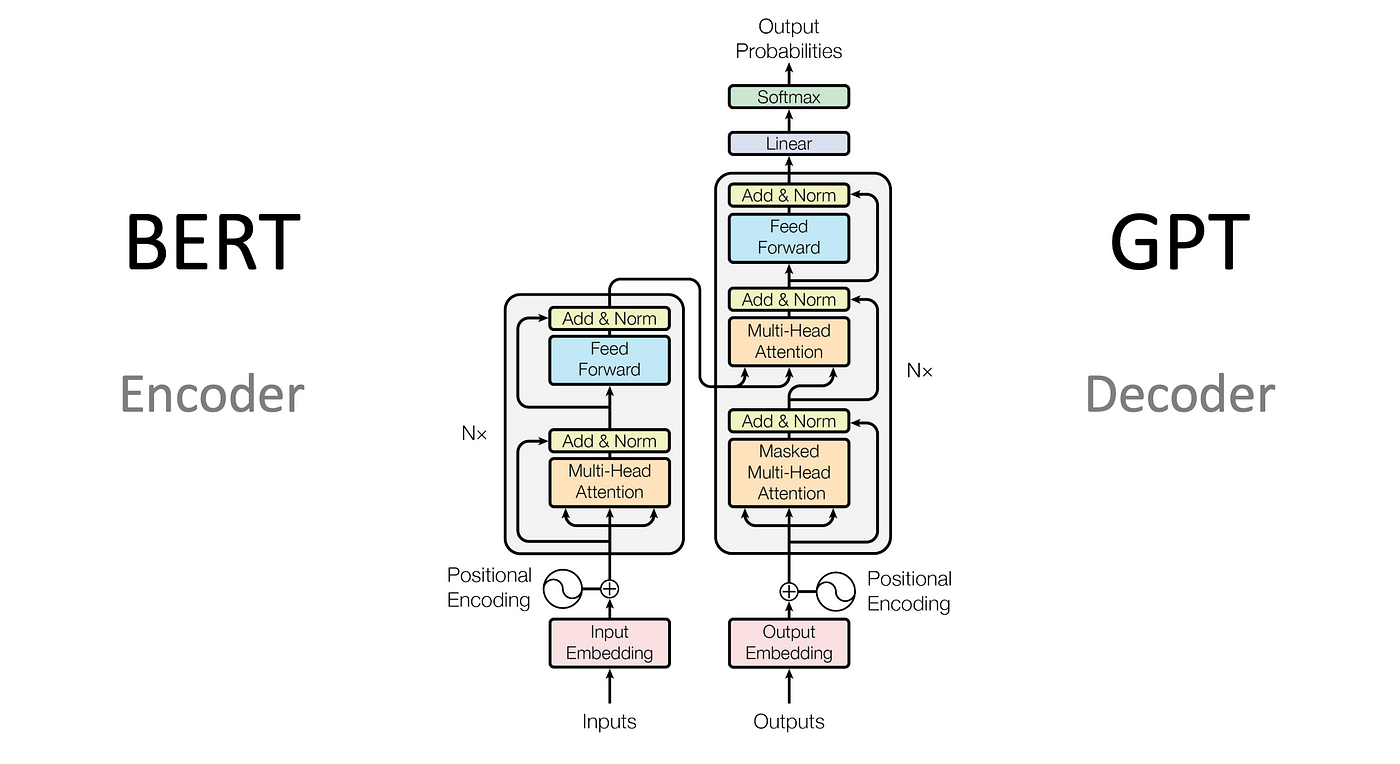
Both GPT-3 / BERT type of models can be made to operate in two styles → cross-encoder and bi-encoder. They have to be trained (or fine-tuned) for the same. I will not go into the training details here.
from sentence_transformers import SentenceTransformer, CrossEncoder
# Load the embedding model
embedding_model = SentenceTransformer("all-MiniLM-L6-v2") # biencoder
# Load the cross-encoder model
cross_model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-12-v2") # cross-encoder
A cross encoder concats the query with each document and computes relevance scores.
<query><doc1>
<query><doc2>
Each pair of concatenated query+doc is passed through the pre-trained model (like BERT) going through several layers of attention and mlps. The self-attention mechanism helps to capture the interaction between the query and the doc (all tokens of query interact with document)
We get the output from a hidden layer (usually the last one) to get contextualised embeddings. These embeddings are pooled to obtain a fixed size representation. These are then passed through a linear layer and then softmax/sigmoid to obtain logits → relevance scores → [0.5, 0.6, 0.8, 0.1, …]
Let’s say we have D documents and Q queries. To calculate relevance score for 1 query, we will have D (query+doc) passes. through the model. For Q queries, we will have D * Q passes since ****each concat of D and Q is unique.
A bi-encoder approach (or the embeddings search approach) encoding documents and queries separately, and calculates the dot product. Let’s say you have D docs and Q queries.
Precompute D embeddings. We can reuse the embedding instead of calculating again. Now for each query, compute dot product of D and Q. Dot product can be considered an O(1) operation.
compute cost of encoding D docs → D
compute cost of encoding Q queries → Q
compute cost then becomes D + Q
Now this is much faster than cross-encoding approach.
Since every token in query interacts with the documents) and assigns a relevance score of query vs. each document, the cross-encoder is more accurate than bi-encoders but they are slow since individual processing of each pair is required (each Q+D combination is unique so cannot precompute embeddings)
Thus, we can stick to a bi-encoder approach (generating embeddings, encode query, encode docs and store in vector db, the calculate similarity) for fast retrieval. Then, we can use rerankers (cross-encoders) to get topK results for improving the results.
Reranking demonstration
In the below example, note that How many people live in New Delhi? No idea. has the most lexical similarity so cos similarity / bi-encoder approach will say it’s most relevant.
from sentence_transformers import SentenceTransformer, CrossEncoder
import numpy as np
# Load the bi-encoder model
embedding_model = SentenceTransformer("all-MiniLM-L6-v2")
# Load the cross-encoder model
cross_model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-12-v2")
# Function to calculate cosine similarity
def cosine_similarity(v1, v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
query = "How many people live in New Delhi?"
documents = [
"New Delhi has a population of 33,807,000 registered inhabitants in an area of 42.7 square kilometers.",
"In 2020, the population of India's capital city surpassed 33,807,000.",
"How many people live in New Delhi? No idea.",
"I visited New Delhi last year; it seemed overcrowded. Lots of people.",
"New Delhi, the capital of India, is known for its cultural landmarks."
]
# Encode the query and documents using bi-encoder
query_embedding = embedding_model.encode(query)
document_embeddings = embedding_model.encode(documents)
# Calculate cosine similarities
scores = [cosine_similarity(query_embedding, doc_embedding) for doc_embedding in document_embeddings]
# Print initial retrieval scores
print("Initial Retrieval Scores (Bi-Encoder):")
for i, score in enumerate(scores):
print(f"Doc{i+1}: {score:.2f}")
# Combine the query with each document for the cross-encoder
cross_inputs = [[query, doc] for doc in documents]
# Get relevance scores for each document using cross-encoder
cross_scores = cross_model.predict(cross_inputs)
# Print reranked scores
print("\nReranked Scores (Cross-Encoder):")
for i, score in enumerate(cross_scores):
print(f"Doc{i+1}: {score:.2f}")
Outputs:
❯ python demo.py
Initial Retrieval Scores (Bi-Encoder):
Doc1: 0.77
Doc2: 0.58
Doc3: 0.97
Doc4: 0.75
Doc5: 0.54
Reranked Scores (Cross-Encoder):
Doc1: 9.91
Doc2: 3.74
Doc3: 5.64
Doc4: 1.67
Doc5: -2.20
Outputs after better formatting to demonstrate the effectiveness of cross-encoder.
Initial Retrieval Scores (Bi-Encoder)
| Document | Sentence | Score |
|---|---|---|
| Doc1 | New Delhi has a population of 33,807,000 registered inhabitants in an area of 42.7 square kilometers. | 0.77 |
| Doc2 | In 2020, the population of India's capital city surpassed 33,807,000. | 0.58 |
| Doc3 | How many people live in New Delhi? No idea. | 0.97 |
| Doc4 | I visited New Delhi last year; it seemed overcrowded. Lots of people. | 0.75 |
| Doc5 | New Delhi, the capital of India, is known for its cultural landmarks. | 0.54 |
The answer to our question was Doc1 but due to lexical similarity, doc3 is has highest score. Now cosine similarity is kinda dumb so we can’t help it.
Reranked Scores (Cross-Encoder)
| Document | Sentence | Score |
|---|---|---|
| Doc1 | New Delhi has a population of 33,807,000 registered inhabitants in an area of 42.7 square kilometers. | 9.91 |
| Doc2 | In 2020, the population of India's capital city surpassed 33,807,000. | 3.74 |
| Doc3 | How many people live in New Delhi? No idea. | 5.64 |
| Doc4 | I visited New Delhi last year; it seemed overcrowded. Lots of people. | 1.67 |
| Doc5 | New Delhi, the capital of India, is known for its cultural landmarks. | -2.20 |
Reference:
HyDE (hypothetical document embeddings)
The user’s query is most likely going to be in English and less of code. But our embeddings are mostly made up of code. Now if you think about the latent space, code would be nearer to code than english (natural language) being nearer to code. This is the idea of HyDE paper.
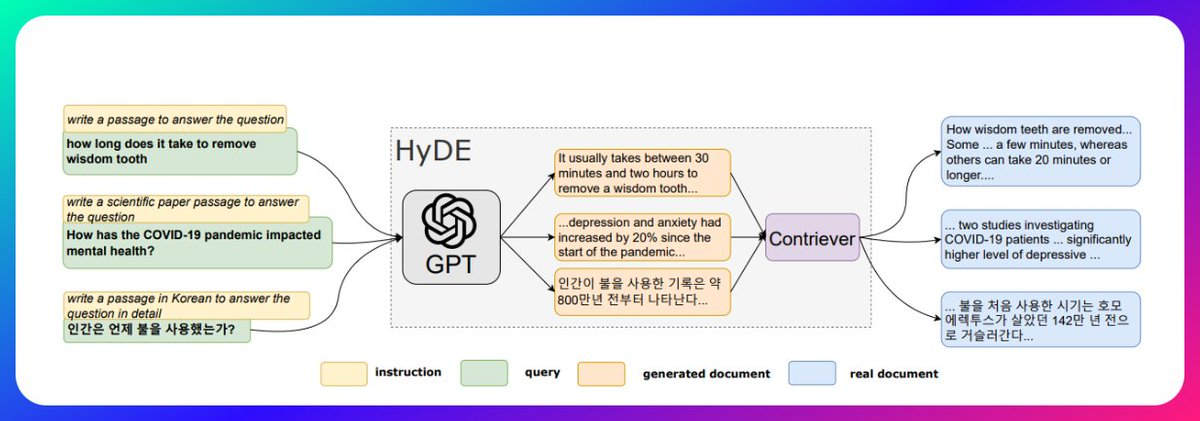
You ask an LLM to generate a hypothetical answer to your query and then you use this (hallucinated) query for embedding search. The intuition is the that embedding of hypothetical query is going to be closer in latent/embedding space than your actual natural language query. It's funny how you are using a hallucinated answer to get better results.
Implementation details
Code used in this section is mainly from app.py and prompts.py
Using gpt-4o-mini for both HyDE queries as it's cheap, fast and decent with code-understanding.
Here's how HyDE query looks like:
# app.py
def openai_hyde(query):
chat_completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": HYDE_SYSTEM_PROMPT
},
{
"role": "user",
"content": f"Help predict the answer to the query: {query}",
}
]
)
return chat_completion.choices[0].message.content
# prompts.py
HYDE_SYSTEM_PROMPT = '''You are an expert software engineer. Your task is to predict code that answers the given query.
Instructions:
1. Analyze the query carefully.
2. Think through the solution step-by-step.
3. Generate concise, idiomatic code that addresses the query.
4. Include specific method names, class names, and key concepts in your response.
5. If applicable, suggest modern libraries or best practices for the given task.
6. You may guess the language based on the context provided.
Output format:
- Provide only the improved query or predicted code snippet.
- Do not include any explanatory text outside the code.
- Ensure the response is directly usable for further processing or execution.'''
The hallucinated query is used to perform an initial embedding search, retrieving the top 5 results from our tables. These results serve as context for a second HyDE query. In the first query, the programming language was not known but with the help of fetched context, the language is most likely known now.
Second HyDE query is more context aware and expands the query with relevant code-specific details.
# app.py
def openai_hyde_v2(query, temp_context, hyde_query):
chat_completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": HYDE_V2_SYSTEM_PROMPT.format(query=query, temp_context=temp_context)
},
{
"role": "user",
"content": f"Predict the answer to the query: {hyde_query}",
}
]
)
return chat_completion.choices[0].message.content
# prompts.py
HYDE_V2_SYSTEM_PROMPT = '''You are an expert software engineer. Your task is to enhance the original query: {query} using the provided context: {temp_context}.
Instructions:
1. Analyze the query and context thoroughly.
2. Expand the query with relevant code-specific details:
- For code-related queries: Include precise method names, class names, and key concepts.
- For general queries: Reference important files like README.md or configuration files.
- For method-specific queries: Predict potential implementation details and suggest modern, relevant libraries.
3. Incorporate keywords from the context that are most pertinent to answering the query.
4. Add any crucial terminology or best practices that might be relevant.
5. Ensure the enhanced query remains focused and concise while being more descriptive and targeted.
6. You may guess the language based on the context provided.
Output format: Provide only the enhanced query. Do not include any explanatory text or additional commentary.'''
By leveraging the LLM's understanding of both code and natural language, it generates an expanded, more contextually-aware query that incorporates relevant code terminology and natural language descriptions. This two-step process helps bridge the semantic gap between the user's natural language query and the codebase's technical content.
A vector search is performed using the second query and topK results are re-ranked using answerdotai/answerai-colbert-small-v1 and then relevant meta-data is fetched.
Note that references are fetched from meta data and combined with code to be feeded as context for the LLM.
# app.py, from the function def generate_context(query, rerank=False)
hyde_query = openai_hyde(query)
method_docs = method_table.search(hyde_query).limit(5).to_pandas()
class_docs = class_table.search(hyde_query).limit(5).to_pandas()
temp_context = '\n'.join(method_docs['code'] + '\n'.join(class_docs['source_code']) )
hyde_query_v2 = openai_hyde_v2(query, temp_context)
logging.info("-query_v2-")
logging.info(hyde_query_v2)
method_search = method_table.search(hyde_query_v2)
class_search = class_table.search(hyde_query_v2)
if rerank: # if reranking is selected by user from the UI
method_search = method_search.rerank(reranker)
class_search = class_search.rerank(reranker)
method_docs = method_search.limit(5).to_list()
class_docs = class_search.limit(5).to_list()
top_3_methods = method_docs[:3]
methods_combined = "\n\n".join(f"File: {doc['file_path']}\nCode:\n{doc['code']}" for doc in top_3_methods)
top_3_classes = class_docs[:3]
classes_combined = "\n\n".join(f"File: {doc['file_path']}\nClass Info:\n{doc['source_code']} References: \n{doc['references']} \n END OF ROW {i}" for i, doc in enumerate(top_3_classes))
All the above context is plugged into an LLM which chats with the user. I use gpt-4o for this as we need a strong LLM for figuring out the context and best chatting UX (available with OpenAI key otherwise Claude 3.5 Sonnet).
We have completed the Retrieval Augmented Generation here. If the user mentions @codebase, then only embeddings are retrieved otherwise existing context is used. If the LLM
is not confident about the context, it will tell the user to mention @codebase (because of the system prompt)
# app.py, from the function def home()
rerank = True if rerank in [True, 'true', 'True', '1'] else False
if '@codebase' in query:
query = query.replace('@codebase', '').strip()
context = generate_context(query, rerank)
app.logger.info("Generated context for query with @codebase.")
app.redis_client.set(f"user:{user_id}:chat_context", context)
else:
context = app.redis_client.get(f"user:{user_id}:chat_context")
if context is None:
context = ""
else:
context = context.decode()
# Now, apply reranking during the chat response if needed
response = openai_chat(query, context[:12000]) # Adjust as needed
This completes the walkthrough.
Possible improvements
Latency
There are a lot of improvements possible especially in the latency department. Currently, queries with @codebase and no re-ranking take about 10-20 seconds and with re-ranking enabled are in 20-30 second range (which is slow). To my defense, Cursor also hovers around the 15-20 second mark usually.
-
Easiest way to cut latency is to use an LLM like Llama3.1 70B from a high throughput inference provider like Groq or Cerebras. This should cut latency by atleast 10 seconds (speed up the HyDE calls by gpt4o-mini).
-
Try out using local embeddings to tackle network latency
-
Our latency bottleneck are the HyDE queries. Is it possible to reduce them to one or totally eliminate? Maybe a combination of Bm25 based keyword search on the repository map can help reduce atleast 1 HyDE query.
Accuracy
Low hanging fruit is
- Try better embeddings or use fine-tuned embeddings
- Implement evals and optimize accuracy with help of feedback loop
Conclusion
Throughout this two-part series, we've explored the intricacies of building an effective code question-answering system. In Part 1, we laid the foundation by discussing the importance of proper codebase chunking and semantic code search. In Part 2, we delved deeper into advanced techniques to enhance retrieval quality:
- We explored how LLM-generated comments can bridge the gap between code and natural language queries
- We discussed the critical considerations for choosing embeddings and vector databases
- We examined various techniques to improve retrieval accuracy, including:
- Hybrid search combining semantic and keyword-based approaches
- The power of cross-encoders for reranking results
- Using HyDE to bridge the semantic gap between natural language queries and code
I hope this series has provided valuable insights into building practical code QA systems. The complete implementation is available on GitHub, and I encourage you to experiment with these techniques in your own projects.
Thank you for reading!
References
Links as they appear in the post
- TODO: Add link to Part 1
- Three LLM tricks that boosted embeddings search accuracy by 37% — Cosine
- MTEB leaderboard
- JinaAI's fine-tuning API announcement
- How Cody understands your codebase
- Cody on GitHub
- LanceDB
- FAISS by Meta
- create_tables.py on GitHub
- Twitter thread on embedding search shortcomings
- Semantweet search on GitHub
- BM25 benchmarks on LanceDB site
- Cohere reranker v3
- ColBERT and late interaction
- HyDE paper
- Ragas documentation