AI agents are popping up everywhere, and they’re only going to become more common in the next few years. Think of them as a bunch of little digital assistants—agents—that keep an eye on things, make decisions, and get stuff done. It makes me wonder: how are we going to manage all these agents down the road? How do we trust them to handle decisions for us and let them run on their own?
These days, many frameworks are out there to help you with AI agents quickly. Honestly, it feels like a new “low-code” tool shows up every other day, promising to make building agents a breeze. They’re all over the place—simple drag-and-drop setups or text boxes where you plug in a few prompts and some data, and just like that, your agent’s ready to go.
Every AI agent has three main pieces at its core: the Model, the Tools, and the Reasoning Loop.
1. The Model: This is the Large Language Model (LLM) that drives the agent. It’s the brain behind it all, trained on piles of text to understand language and tackle tricky instructions. This is what lets the agent think and talk almost like a person.
2. The Tools: The agent uses specific skills to interact with the world and get things done. Whether it’s grabbing data, hitting up APIs, or working with other programs, the tools are what make the agent useful.
3. The Reasoning Loop: This is how the agent figures things out. It’s the process it uses to solve problems, pick the best path forward, and wrap up tasks.
In this post, I’m going to mix things up a little. Instead of leaning on a framework, I’ll walk you through building a fintech agent from scratch using Python. This one’s going to help with decisions about loans and insurance.
What's the deal here?
So how does this fintech agent work? Well, picture yourself running a FinTech company. Customers come at you with stuff like, “Can I borrow $10K for a new kitchen? I’m 26 years old,” or “I crashed my car—will you cover it?” Haha, I’d probably shut that insurance claim down real quick.
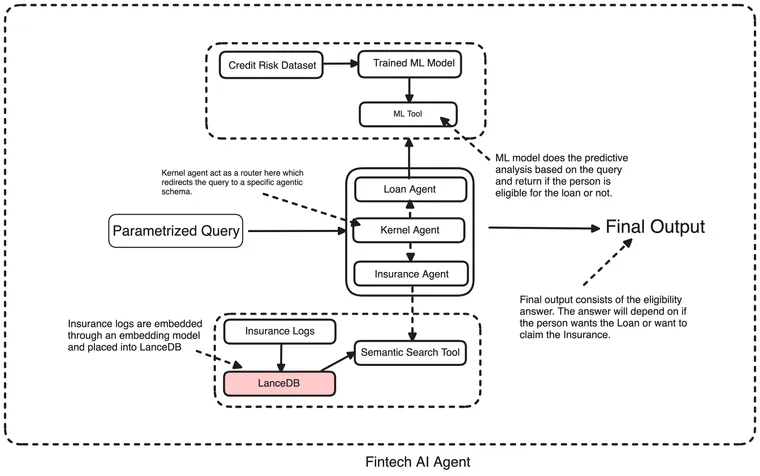
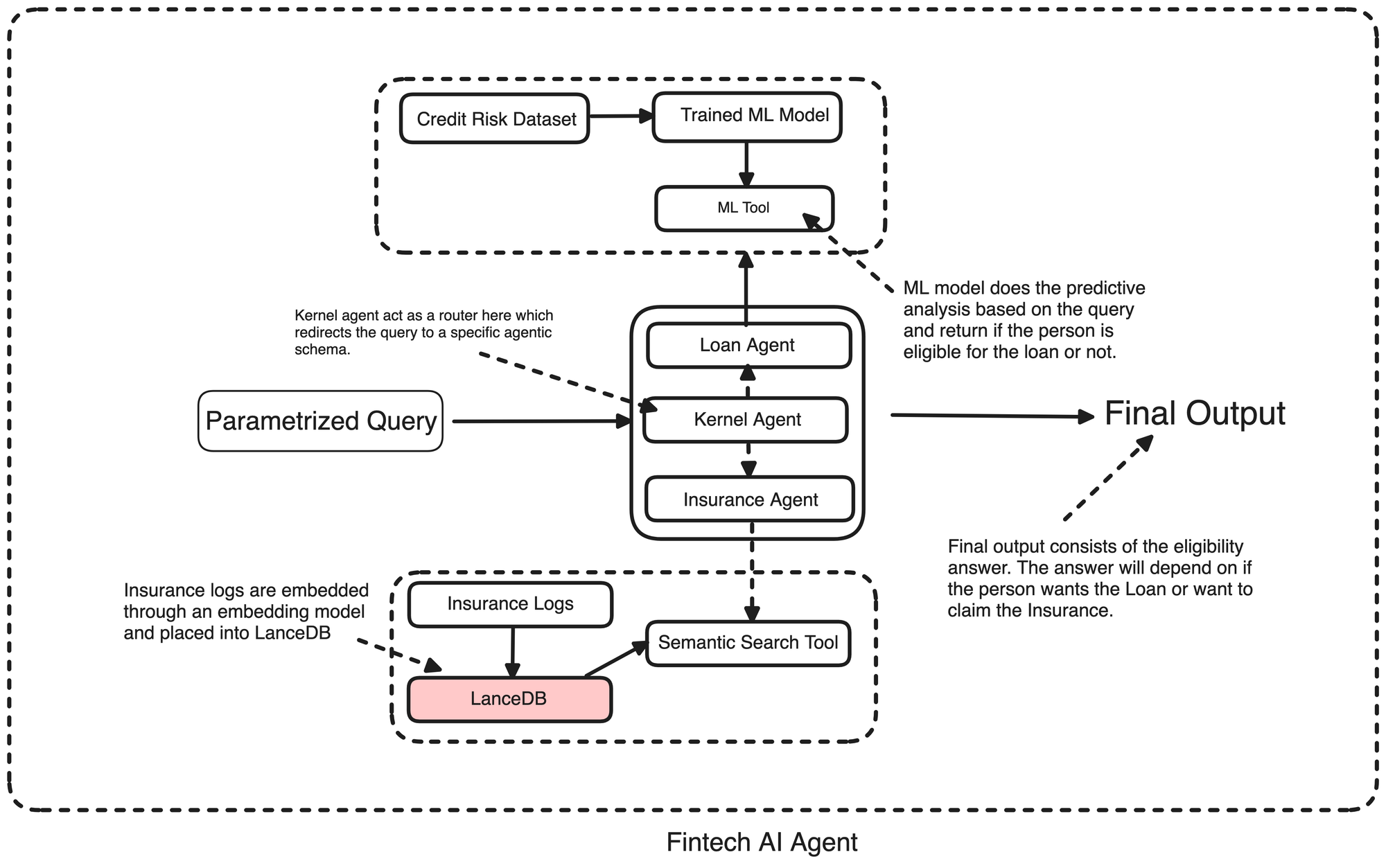
The point is, that we need a system that’s fast, sharp, and reliable when it comes to deciding on loan requests and insurance claims. So, what I did is this: instead of one lone agent handling everything, I split it into three—Loan, Insurance, and a Kernel agent.
1. Loan Agent: Takes a query, figures out what they want (like “home improvement”), and uses an ML model to predict if they’re good for the loan based on age, income, and the amount.
2. Insurance Agent: Reads a claim, checks it against past cases, and decides if it’s worth paying out—kind of like a semantic search over a claims database.
3. Kernel Agent: The brains that tie it all together, sending queries to the right place.
Now the question always comes of why raw Python? Well, the most viable reason is flexibility. I’m just putting together a proof of concept here, and companies can easily tweak it to fit their own data and needs—no black-box framework nonsense. The Credit Risk Dataset and synthetic claims are just placeholders; real firms would swap in their own loan histories and claim records.
Big picture!
Ok so what we’ve got is a Kernel Agent directing traffic, a Loan Agent predicting eligibility with machine learning, and an Insurance Agent checking claims against a vector database.
I’m using the Credit Risk Dataset as a demo for loans. In reality, companies could use something like a CIBIL score to see if someone’s eligible. But for this POC, I grabbed that dataset, trained a random forest model, and used it for predictive analysis. For the insurance agent, I built a synthetic pipeline to whip up a dataset of fake insurance queries. The target’s simple: if the claim gets approved based on the conversation, it’s a one. These are just placeholders to show how it works; companies can plug in their own data instead. Saying that, let's get started.
Step 1: Setting up the stage - Libraries and Setup
We start by grabbing our tools—libraries that handle data, models, and vectors
pip install pandas joblib pyarrow sentence-transformers lancedb mistralaiimport pandas as pd
import joblib
import pyarrow as pa
from sentence_transformers import SentenceTransformer
import lancedb
from mistralai import Mistral
import os
from abc import ABC, abstractmethod
from typing import Any
# Abstract Tool Class
class Tool(ABC):
@abstractmethod
def name(self) -> str:
pass
@abstractmethod
def description(self) -> str:
pass
@abstractmethod
def use(self, *args, **kwargs) -> Any:
pass
# Initialize Mistral and Embedder
api_key = os.environ.get("MISTRAL_API_KEY", "xxxxxxxxxxxxx")
if not api_key:
raise ValueError("Please set the MISTRAL_API_KEY environment variable.")
model = "mistral-large-latest"
client = Mistral(api_key=api_key)
hf_token = "hf_xxxxxxx"
embedder = SentenceTransformer('all-MiniLM-L6-v2', token=hf_token)
# Connect to LanceDB
db = lancedb.connect('./lancedb_data')For the quick demonstration, I am going to use mistral-large-latest a model from the Mistral for LLM tasks and the intent classification in the Loan queries. The Tool class is our way to keep the agents modular - every tool gets a clear job.
Step 2: Loan Agent - Predictive analysis with ML
As soon as a query comes in, the Loan Agent uses its ML tool to spin up the predictions. I am using the Credit Risk Dataset here.
Loading the Demo Data
loan_data = pd.read_csv('./credit_risk_dataset.csv')
loan_data.head() person_age person_income loan_amnt loan_intent loan_status
0 22 59000 35000 PERSONAL 1
1 21 9600 1000 EDUCATION 0Why Credit Risk Dataset? : It’s public, well-structured, and mimics real loan data with features like loan_status (0 = approved, 1 = rejected). For demo purposes, it’s spot-on. Companies would swap this for their own credit records—same columns, different rows, or maybe other relevant benchmarks that can be utilized for setting up the target in terms of the loan status.
Building the ML model
For the sake of the demonstration, I have used a Random Forest Classifier here. You can literally play around with different sets of these models, ensemble them, and get better in terms of accuracy and data processing.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import Pipeline
import joblib
features = ['person_age', 'person_income', 'loan_amnt', 'loan_intent']
target = 'loan_status'
loan_data = loan_data.dropna(subset=features + [target])
preprocessor = ColumnTransformer(
transformers=[('cat', OneHotEncoder(handle_unknown='ignore'), ['loan_intent'])],
remainder='passthrough'
)
X = loan_data[features]
y = loan_data[target]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', RandomForestClassifier(random_state=42))
])
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
print(f"Model accuracy: {accuracy:.2f}") # 0.84
joblib.dump(model, 'loan_approval_model.pkl')- Why Random Forest? Well as we know, Random forest comes under the ensemble category, and it's robust in nature, handles mixed data (numbers and categories) well, and gives us probabilities—not just yes/no. For loans, that’s gold; banks love knowing the odds though.-
- How It Works: We preprocess
loan_intentinto numbers (e.g., "MEDICAL" becomes a categorical encoded number), split the data, train, and test. Got an 84% accuracy which is decent for a demo. Real data could boost or tweak that. - Swap It Out: As I said earlier, companies can use their own loan data here—same features, their numbers. Train it fresh, and it’s tailored to them.
Completing the Integration for the Loan Agent
Now comes the agent itself:
class PredictiveMLTool:
def __init__(self):
self.model = joblib.load('loan_approval_model.pkl')
def use(self, intent, age, income, loan_amount):
input_data = pd.DataFrame(
[[age, income, loan_amount, intent]],
columns=['person_age', 'person_income', 'loan_amnt', 'loan_intent']
)
prob_approved = self.model.predict_proba(input_data)[0][0]
print(f"Probability for the loan approval is: {prob_approved}")
return "Eligible" if prob_approved > 0.5 else "Not Eligible"
class LoanAgent:
def __init__(self):
self.tools = [PredictiveMLTool()]
self.llm = llm
def process(self, query, params):
intent = self.extract_intent(query)
age = params.get('age')
income = params.get('income')
loan_amount = params.get('loan_amount')
return self.tools[0].use(intent, age, income, loan_amount)
def extract_intent(self, query):
valid_intents = ['DEBTCONSOLIDATION', 'EDUCATION', 'HOMEIMPROVEMENT', 'MEDICAL', 'PERSONAL', 'VENTURE']
prompt = f"Given the query: '{query}', classify the intent into one of: {', '.join(valid_intents)}. Respond with only the intent in uppercase (e.g., 'HOMEIMPROVEMENT'). If unsure, respond with 'PERSONAL'."
response = self.llm(prompt)[0]['generated_text'].strip().upper()
return response if response in valid_intents else 'PERSONAL'- Why ML Here? It’s predictive, which means it takes raw data and spits out a decision. LLM handles intent because it’s quick and decent for text, though companies might use something beefier or their own intent rules. I let the LLM decide what's the intent here.- How It Fits: Query → Intent (e.g., "school fees" → EDUCATION) → ML prediction. It's as simple as the tool’s the muscle, and the agent’s the coordinator.
If the companies need a different logic to get the target status in terms if the loan can be provided to an individual or not, as I said earlier, they can easily replace the predictive ml modeling with another set of benchmarks or maybe thresholding some different set of metrics to figure out if that person is made for the loan or not.
To make things more smoother, let's introduce our Kernel Agent which will be used for redirecting the queries to the Loan and the Insurance agent based on the query type.
class KernelAgent:
def __init__(self, loan_agent):
self.loan_agent = loan_agent
def process_query(self, query, params):
return self.loan_agent.process(query, params)Well, this is good, but let's not forget we now need to work on our Insurance agent.
Step 3: Insurance Agent - Vector Search with LanceDB
Before diving in, I want to walk you through my thought process for creating the Insurance Agent. Picture this: you walk into an insurance company, sit down with someone, and start explaining why you need to file a claim—why it’s legit and why you deserve it. That conversation is key because it’s the starting point for deciding whether the claim gets processed or not.
I tried hunting down a dataset with those kinds of conversations and clear yes or no labels for claims, but I came up empty. So, to keep things moving, I built a simple synthetic dataset pipeline. It generates a fake dataset with text queries on one side and a target on the other—showing if the person filing the claim is eligible or not.
Now, let’s talk about where the VectorDB comes in. Here’s the plan: we’ll embed those insurance claim queries first. Then, when a new claim pops up, we’ll pull the k-most similar queries from the database, look at their average eligibility scores, and use that to decide if the new query deserves a legitimate claim or not. With that in mind, let’s start by generating some synthetic claims for the automotive industry. This is just a quick demo—companies can swap in real conversations instead, and you can tweak the pipeline a bit to handle actual data.
import random
import csv
from mistralai import Mistral
api_key = "xxxxxxxxxxxxxxx"
model = "mistral-large-latest"
client = Mistral(api_key=api_key)
base_prompt = "Generate a detailed query for an auto insurance claim..."
def generate_query(denied=False):
prompt = base_prompt
if denied:
prompt += " Include a reason the claim might be denied (e.g., drunk driving, uninsured vehicle)."
response = client.chat.complete(model=model, messages=[{"role": "user", "content": prompt}], max_tokens=200)
return response.choices[0].message.content.strip()
def assign_target(query):
rejection_keywords = ["drunk", "influence", "racing", "uninsured"]
return 0 if any(kw in query.lower() for kw in rejection_keywords) else 1
dataset = []
for i in range(100):
denied = random.random() < 0.4
query = generate_query(denied)
target = assign_target(query) if not denied else 0
dataset.append({"query": query, "target": target})
with open("auto_insurance_claims.csv", "w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=["query", "target"])
writer.writeheader()
writer.writerows(dataset)To make it a bit more realistic, I have included some of the rejection keywords like drunk, influence racing and the uninsured which is readily used to make the dataset better in terms of the realistic cases where the claims are not processed. Running this will generate a CSV with the relevant data.
Now comes the LanceDB setup...
import pyarrow as pa
df = pd.read_csv('auto_insurance_claims.csv')
embeddings = embedder.encode(df['query'].tolist())
embeddings_list = [embedding.tolist() for embedding in embeddings]
schema = pa.schema([
pa.field("embedding", pa.list_(pa.float32(), list_size=384)),
pa.field("target", pa.int32()),
pa.field("query", pa.string())
])
table = db.create_table("insurance_queries", schema=schema)
df_lance = pd.DataFrame({"embedding": embeddings_list, "target": df['target'], "query": df['query']})
table.add(df_lance)As I said earlier, companies could load their real claim logs here instead. Now comes the main part, we are going to integrate the semantic tooling capability into our Insurance agent.
# Insurance Agent Tools
class SemanticSearchTool(Tool):
def __init__(self, table):
self.table = table
self.embedder = embedder
def name(self):
return "Semantic Search Tool"
def description(self):
return "Performs semantic search in LanceDB to assess claim approval based on similar past claims."
def use(self, query, k=5):
new_embedding = self.embedder.encode([query])[0].tolist()
results = self.table.search(new_embedding).limit(k).to_pandas()
approval_rate = results['target'].mean()
similar_queries = results['query'].tolist()
decision = "Approved" if approval_rate > 0.5 else "Not Approved"
print(f"Approval rate among similar claims: {approval_rate*100:.1f}%")
return {"decision": decision, "similar_queries": similar_queries}
# Insurance Agent
class InsuranceAgent:
def __init__(self, table):
self.tools = [SemanticSearchTool(table)]
def process(self, query):
return self.tools[0].use(query)This is it, let's integrate our Insurance agent within our Kernel agent along with the Loan Agent.
Step 4: Completion of Kernel Agent
# Kernel Agent
class KernelAgent:
def __init__(self, loan_agent, insurance_agent):
self.loan_agent = loan_agent
self.insurance_agent = insurance_agent
self.client = client
self.model = model
def classify_query(self, query):
prompt = f"""
Given the query: '{query}', classify it as 'loan' or 'insurance'.
Respond with only 'loan' or 'insurance'.
If unsure, respond with 'unknown'.
"""
response = self.client.chat.complete(
model=self.model,
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=10
)
print(f"Query type : {response.choices[0].message.content.strip().lower()}")
return response.choices[0].message.content.strip().lower()
def process_query(self, query, params=None):
query_type = self.classify_query(query)
if query_type == 'loan':
if not params:
return "Error: Loan query requires parameters (age, income, loan_amount)."
return self.loan_agent.process(query, params)
elif query_type == 'insurance':
return self.insurance_agent.process(query)
else:
return "Error: Unable to classify query as 'loan' or 'insurance'."Now all you need to do is toss in a query—could be anything about loans or insurance. It’ll hit the Kernel Agent first, and based on what the query’s about, it’ll get handed off to either the Loan Agent or the Insurance Agent. From there, they’ll handle the rest of the decisions.
# Test Cases
test_cases = [
{
"query": "I had a bad accident yesterday, but i think i was a bit drunk, need some insurance",
"params": None
},
]
# Run Tests
print("Testing Integrated System with Mistral:")
print("-" * 50)
for case in test_cases:
query = case["query"]
params = case.get("params")
result = kernel_agent.process_query(query, params)
print(f"Query: '{query}'")
if params:
print(f"Params: {params}")
if isinstance(result, dict):
print(f"Decision: {result['decision']}")
print("Similar Queries:")
for q in result['similar_queries']:
print(f"- {q}")
else:
print(f"Result: {result}")
print("-" * 50)Think about the potential here: fintech companies can plug in their own tools and data to process loans and insurance claims. Picture how much manual work insurance folks put in, checking every little thing to figure out if a claim’s legit or not—or the same deal with loans, deciding if someone qualifies. This could cut out so much of that hassle.
Refer to this notebook for complete code implementation

Star 🌟 LanceDB recipes to keep yourself updated -
