
In recent years the concept of a table format has really taken off, with explosive growth in technologies like Iceberg, Delta, and Hudi. With so many great options, one question I hear a lot is variations of "why can't Lance use an existing format like ...?"
In this blog post I will describe the Lance table format and hopefully answer that question. The very short TL;DR: existing table formats don't handle our customer's workflows. Basic operations require too much data copy, are too slow, or cannot be parallelized.
What is a table format?
A table format is probably more accurately thought of as a protocol. It describes how the basic table operations (adding rows, deleting rows, etc.) happen. In other words, it tells us how data files change, what metadata we need to record, what extra structures (e.g. deletion files) are needed, and so on. In the interest of brevity I'm not going to fully describe every operation in the Lance table format in this article. A more complete description can be found in our docs. If you are familiar with Iceberg or Delta, then Lance is not very different. In the following sections I'll focus on what is different.
Modern Workloads
When I talk about "modern workloads" I'm generally talking about large ML workloads that are developing, training, or using various models. These workloads are not limited to LLMs (there are many types of models) and they can be very diverse. However, we have noticed a few commonalities.
The Curse of Wide Data
As data science gets more sophisticated, scientists are bringing their work to bear on larger and larger data types. Text is moving from "simple labels" to things like complex prose, websites, and source code. Multi-modal data such as audio, images, and video are being introduced. Even numerical data can get large when we consider items like tensors, vector embeddings, etc.
As I've worked with wide data I've come to an interesting observation that I am going to start referring to as the curse of wide data (because that's a fun sounding name). If some of your data is wide then most of your data is wide. One of our team cats has agreed to assist with a demonstration:

If cats are not convincing then we can try a simple example. If you take the TPC-H line items table (the kind of thing all your favorite databases are optimized against) and add a single 3KiB vector embedding column then that table will go from 16 columns to 17 columns...and will go from 0% wide data to 99% wide data.
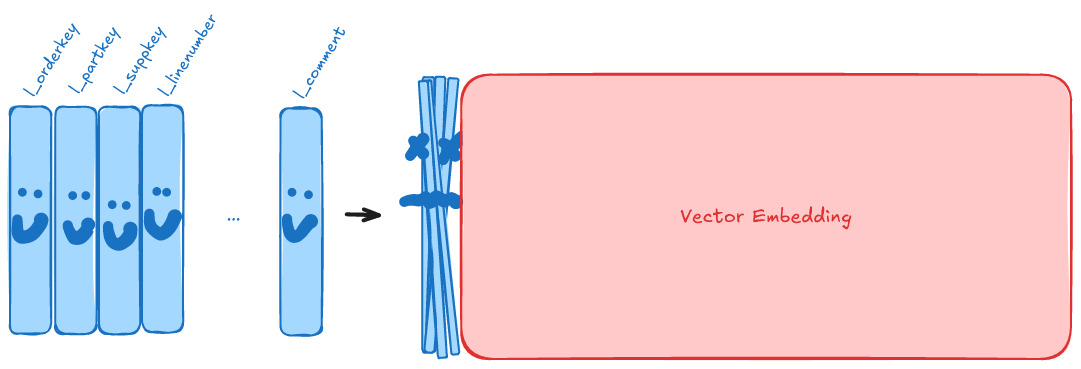
Tables Grow Horizontally and Vertically
Your internal model of a database table is probably something that grows mostly longer with time. For example, we have a sales table that gains new rows each time a sale is made at some company. Or maybe we are recording user clicks on some website. Or perhaps our table gains a new row every time a new post about table formats is made.
Once you put data scientists into the mix, something strange starts to happen. The table starts to grow horizontally, often growing outward from a single column. For example, let's consider a research project that starts by scraping Wikipedia and creating one fat column "article text" which contains the Wikipedia markup. Then the data scientists get to work. They add a new column, "sentiment analysis", that measures if the article has a positive or negative tone. Then they add "political bias". Then they go and scrape some more data and add an "edit count" column. This process repeats and repeats until, in some frightening cases, we can have hundreds or thousands of columns!
This process of adding columns repeats again and again as scientists discover new interesting things about the underlying data and make more and more sophisticated observations. Some researchers are now even starting to worry about datasets with tens of thousands of columns (although we find most users are more in the hundreds-to-thousands scenario).
Data is Messy
This is not a novel observation but it bears repeating. This has many different faces and implications. Cleanup operations (editing, deleting, etc.) are important. Data needs to be searchable so users can understand what they have. Data is often scraped or taken directly from other sources and foreign keys are super common (I can't remember the last customer that didn't have some kind of UUID column). Existing data often needs deduplicated. New data needs to be deduplicated on entry (I sometimes wonder if users are even aware it's possible to add data without using merge). Users need to do a lot of exploration of the data.
Modern Problems (and some modern solutions)
I'll now explain the problems we encountered with existing table formats. For each problem I'll explain how we've solved it in Lance and I'll also make an attempt at explaining some of the alternate solutions we've seen out there. Let's start with perhaps the most common reason users have given for switching to Lance.
Data Evolution > Schema Evolution
Table formats offer "zero copy schema evolution". This means you can add columns to your table after you've already added data to your table. This is great but there is one problem and it's in the fine print.

That's right, new columns can only be populated going forwards. All existing rows will either be NULL or will be given a default value. This makes perfect sense in the classic "data grows vertically" scenario. If our sales team started rewarding "loyalty bucks" with each purchase then the new "loyalty bucks" column doesn't make sense for all past transactions and we can set it to zero.

However, this is NOT what we want when our table is growing horizontally. The entire reason we added a new column is because we've calculated some new feature value for all of our rows! So, how do we add this new column in a classic table format? It's simple, we copy all of our data.

Well, that's ok...a data copy isn't that expensive. Unless...

Well, that's ok...how many new columns are we really going to be adding...

Ok, maybe this is a problem we actually need to solve...
Lance Table Feature One: Two-dimensional Storage
So how does Lance solve this? With more complexity magic. Lance has a two-dimensional storage layout. Rows are divided (vertically) into fragments. Fragments are divided (horizontally) into data files. Each data file in a fragment has the same number of rows and provides one or more columns of data. This is different from traditional table formats which only have one dimension.
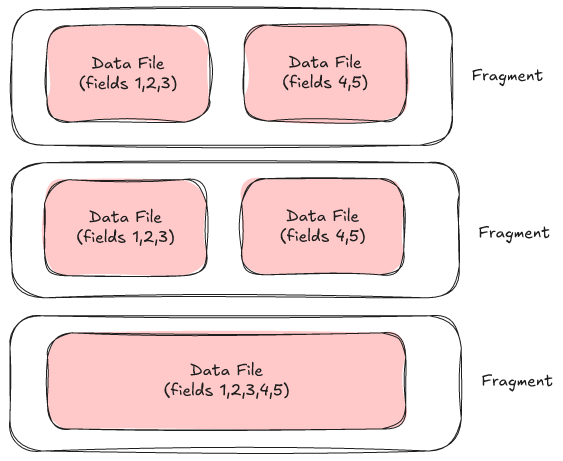
Initially, as we write new rows, we create one data file per fragment. When we add a new column, instead of rewriting the fragment, we add a new data file to the fragment. In fact, we can use this trick to do a lot of cool things, like splitting a fragment when we update it, but we'll save the advanced tricks for a future blog post. For now, let's focus on our horizontally growing table.
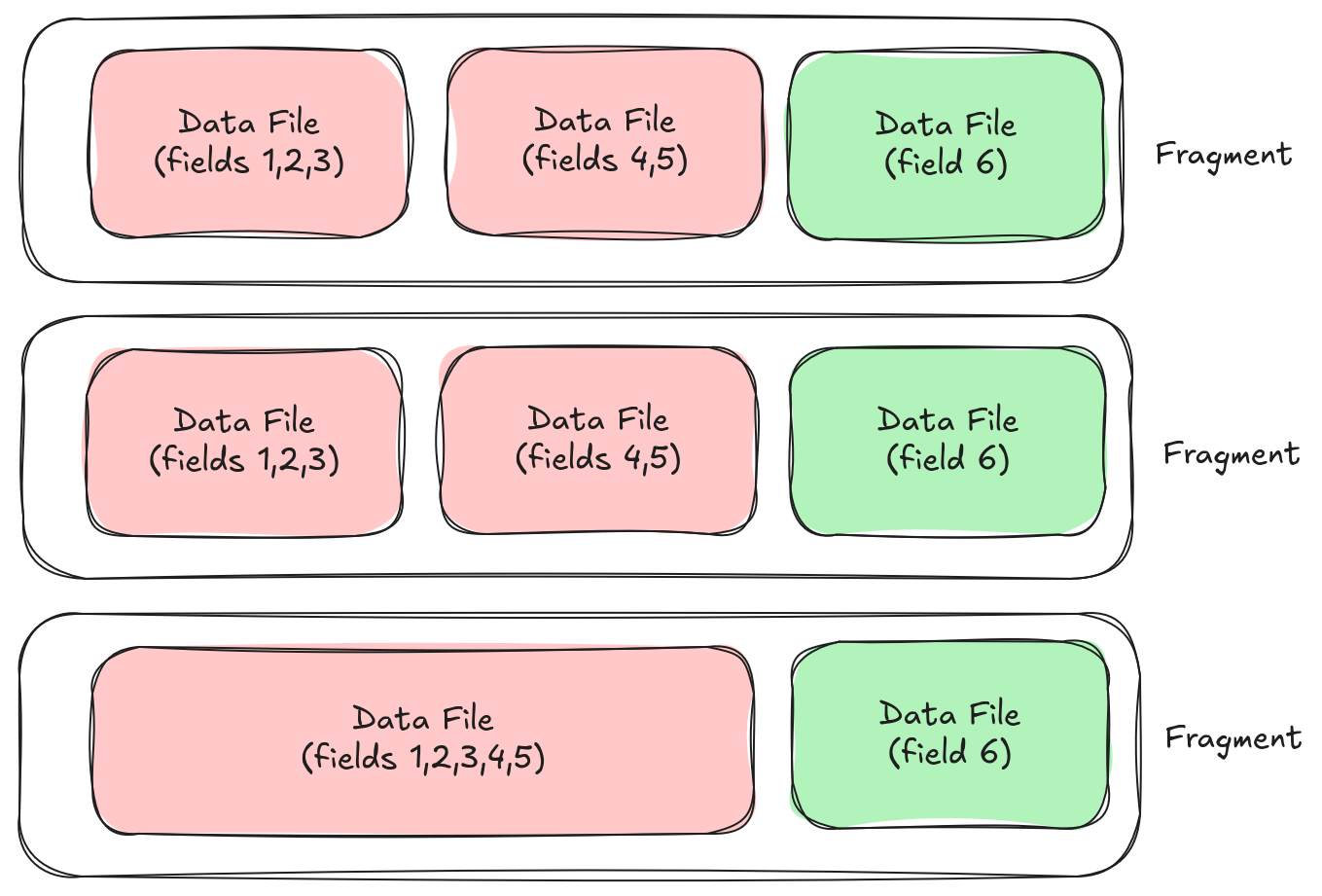
Every time users add a new column, we write a new data file for each fragment. We don't need to rewrite any data (keep in mind that the "fragments" are not files, just lists in the manifest, so we can modify those). At some point, as we start to get hundreds or thousands of files per fragment, we may want to merge some of these together, which will require a rewrite (tbh, I haven't experienced this need yet but I'm playing devil's advocate). However, that rewrite can be done strategically. The large columns (remember: 90%+ of our data) can be left alone and we only need to combine and rewrite the smaller columns.
Rebuttal: Why not Two Tables?
There is another way this problem can be solved, which is perhaps more classic, but also more limiting. The two-table approach, perhaps also called the "url-only-in-db" approach, splits the large data and the small data into two different tables, joined with a foreign key of some kind. A specialized storage engine (like Lance) can be used for the large data, while traditional table formats can be used for the small data.
There is nothing particularly wrong here but we find that it ends up being more work than the two-dimensional storage approach described above. You need to come up with some kind of mechanism for keeping the two tables in sync through all the various table format operations. In fact, what you end up doing, is creating a new table format.
It also quickly becomes difficult to know when a column is "for the big table" and when a column is "for the little table". For example, you might want to put your vector embeddings in the large table with your images so you can avoid rewriting those when you add new features. However, vector embeddings are actually something that are regularly replaced (when a new model comes long) or added and removed (to support different search models). You probably want to make sure you're not rewriting your images every time you change your embedding model. This means you either need a third table, your "big data table" needs to utilize two-dimensional storage, or you give up and put the embeddings back in the small table.
"Search" is Everywhere
We got our start building vector search and so it's no surprise we handle that case quite well. What did surprise us was that search started to pop up everywhere. You just need to know the trick: no one ever ever calls it search. Let's explore some sample things people did ask for,
- These feature columns are based on an external dataset that changes all the time so every day I need to pull down the changes. But that's ok, the batch of updates has a foreign key column and so I can use that to update all those rows with new values.
- My data has a tags column where we've classified the data into a few different thousand tags. Each row has one or more tags. When we test our model we often test just one or two tags. It's just a small chunk of the data so it shouldn't take long to load.
- We want to test our model on pictures of cats. The data isn't labeled in this way but there's a "caption" column. Just give us all the images that have cat or kitten or feline or whatever in the caption column.
Lance Table Feature Two: Indices & Random Access
The humble index has been synonymous with databases since...forever. However, as OLAP processing moved into columnar storage (and into the cloud) a strange thing happened. It turned out that sequential access of columnar data was so fast, and random access to column data was so slow, that indices were no longer required. Even if you could identify exactly what bits of data you wanted, there was little benefit from reducing the total amount of I/O.

LanceDB (the company, not the table format) has changed this equation in a number of different ways. The Lance file format minimizes the number of IOPs and amount of data that needs read. We've also embraced the fact that many of our users are either running locally or have some kind of filesystem caching layer. In fact, a page cache is a big part of our enterprise architecture. As a result, the access patterns have swapped, and the forgotten index has once become essential.

Fortunately, while Lance obviously has vector indices, we also have a variety of indices for non-vector data. We use these indices internally, when available, to speed up a number of table format tasks. Let's look at the examples above.
Indices on foreign key columns make it super fast to find matching rows and apply updates. Classically, this kind of task would be done with a hash join on the foreign key column. If we have a btree index on the foreign key column we can skip this step entirely. In fact, we can do key-deduplicating writes without any I/O into the old data. This makes things faster even if you don't have any kind of caching layer.
In the tags filtering example we run into a general expectation our users have. "It's just a small chunk of the data so it shouldn't take long to load". Unfortunately, string filtering, and string loading, can be surprisingly expensive. Let's say we have one billion rows, a "tags" column might easily be 50-80GB, and performing billions of string comparison operations can be pretty time consuming. However, if there's an index (in this case a label_list index), then we can quickly start returning results and the entire query will likely be much faster, especially if the data is in-cache.
In the last, example, involving captions, we encounter a surprising relationship. Nearest neighbor search, in threshold mode, can turn "search indices" (like vector indices or full text indices) into a tool that can be used for filtering. We wanted to find all relevant images (cat or kitten or feline). This is exactly the kind of problem that full text search is good at solving. You can either discover a threshold that gives you the correct results or simply pull back a large number of results in FTS order and find the point the results are no longer relevant.

Existing table formats will often tackle these problems with clustering (a.k.a primary indices). They've even come up with some pretty cool innovations here like liquid clustering and z-order clustering which make it easier to handle multiple columns. However, these approaches are often limited in the number of scenarios they can address, there are only so many columns that you can use as primary indices. They also would rely on rewrites for new columns. Even if you were to add two-dimensional storage, you would need a rewrite if you wanted your new column to participate in a primary index.
I think there is a lot of good in primary indices. They have better I/O patterns (don't require random access) since the data is ordered and they are much smaller than secondary indices. We need to get better primary index support into Lance at some point. Still, the data rewriting problem is significant, and it has prevented us from being to take advantage of primary indices in many situations.
The Well Rounded Implementation
The final issue we encountered is that most table libraries we tried had focused most their time and effort on the query problem. This makes a lot of sense. OLAP is big and complicated. Distributed query engines are cool and fun. Unfortunately, we end up with a bit of an unbalanced implementation.
At LanceDB, we've discovered that working with big data means that everything is hard. Importing initial data needs to be done in parallel and distributed because even small numbers of rows can mean tons of data. Adding a new column might need to be a task that runs in parallel because we're using a complex model to calculate our features and it can be expensive to calculate even a single row's value. Calculating an index needs to be something we can partition across multiple workers. The list goes on.
Basically, the way I like to think of it, is that we need the same API as a regular database (insert, create index, alter column, etc.) but every single thing needs to be capable of running in parallel, and ready to handle big data (don't get us started on batch sizes and RAM consumption 😅).
To be fair, I don't think we've got the perfect user friendly API for many of these things. Also, these are primarily library concerns, as most formats can support these operations in parallel. However, these are challenges we are taking on head first, and we've heard multiple times from users that we seem to be getting it right so far.
What's Next
First, we still have work to do to make sure that we're doing all the things I've described above in the best way possible. We wanted to start writing about this to share the challenges and solutions we've encountered as we hope it will help the design and expansion of existing table formats.
We also want to increase our integration support. Pushing customers to use a single table format is perhaps idealistic. We recently noticed some interest in potentially adding the Lance file format to Iceberg and this kind of integration is very exciting. We're also excited by the many unified front-ends to table formats that have arisen. The not-exactly-official "pyarrow datasets protocol" has allowed us to integrate with tools like DuckDB and Polars. Datafusion gives us the "table provider" trait and we're seeing more and more things that can consume that. Flight SQL gives as a unified "SQL frontend". Tools like XTable could even provide metadata-level compatibility.
Work on catalogs is starting to ramp up and provide unified APIs for database management and we're following these moves closely. We'd also like to continue our work developing new kinds of indices. All of our indices are just plain Arrow data (in Lance files) and could be useful elsewhere too. Through the arrow-verse, and the idea of composable data systems, we are finding that users are able to use the right tool for the right job without hard-locking into dependencies.
If you're interested in adding an integration to Lance or learning more about our table format, hop on over to our Discord or Github and we'd be happy to talk to you!
Special Thanks
Special thanks to the pets from LanceDB who would like to mention that these photos were perhaps not taken from the most flattering angles.
