
Lance 0.15.0 introduces several experimental features, marking major milestones on important projects in our library. It exposes the first public APIs for full-text search indices. It also provides opt-in support for two new encodings: better string compression using FSST and a packed struct encoding optimized for random access. These advancements move us another step closer to being the best format for AI data lakes.
This release wouldn't be possible without the hard work of our amazing contributors. While many of our major features are driven by full-time employees at LanceDB, we are excited to see some major features being pushed forward by community members. This release contains one such feature: FSST string compression. We extend our gratitude to everyone who has contributed to Lance thus far, and look forward to continuing to innovate together.
New inverted indices for full-text search
Initial full-text search support is now exposed in Lance’s API. These indices are called "inverted indices" in Lance.
You can pass the full_text_query parameter to the query APIs, such as dataset.to_table(). This only works for columns where an index is present. Trying to search a string column with no index will simply give an error right now. To create an inverted index, pass index_type="INVERTED" to Dataset.create_scalar_index(). For example, you can search a set of headlines like so:
import lance
import pyarrow as pa
headlines = [
"Scientists may have discovered 'dark oxygen' being created without photosynthesis",
"A hydrothermal explosion sends Yellowstone visitors running",
"Not a B movie: Sharks are ingesting cocaine in the ocean, scientists find",
"A study finds that dogs can smell your stress — and make decisions accordingly",
"Bats have a lot of secrets. These bat-loving scientists are investigating",
"Crows can count out loud like human toddlers — when they aren't cheating the test",
]
data = pa.table({"headline": headlines})
dataset = lance.write_dataset(data, "test_path")
# If you use without an index, will give error:
# "LanceError(IO): Column headline has no inverted index"
dataset.create_scalar_index("headline", index_type="INVERTED")
dataset.to_table(full_text_query="human")pyarrow.Table
headline: string
----
headline: [["Crows can count out loud like human toddlers — when they aren't cheating the test"]]Full text search already exists downstream in LanceDB Python. However, it’s implemented using Tantivy Python, so it doesn’t work for the Node or Rust bindings. Additionally, Tantivy’s indices are designed for local filesystems, so those indices don’t work on object storage like S3. By rewriting full-text search in our Lance Rust library, we’ll be able to remove both these limitations.
Thanks to LanceDB engineer Yang Cen for his work on this feature. You can follow progress on this feature in the Full-Text Search epic.
FSST string compression
Experimental support for string compression has been added. This uses the "FSST" encoding, developed by Peter Boncz, Thomas Neumann, and Viktor Leis (article), and used in modern systems like DuckDB (link). This makes string columns much smaller on disk but, unlike generic compression such as Snappy, it still allows random access. That is, you can access a single string value without having to decode an entire page of column data.
In many cases, FSST can achieve similar compression ratios to Snappy. As an example, we compressed 200,000 Wikipedia articles. FSST provided 39.4% smaller files in Lance, while Parquet with Snappy compression provided a 42.8% smaller file than in-memory uncompressed data.
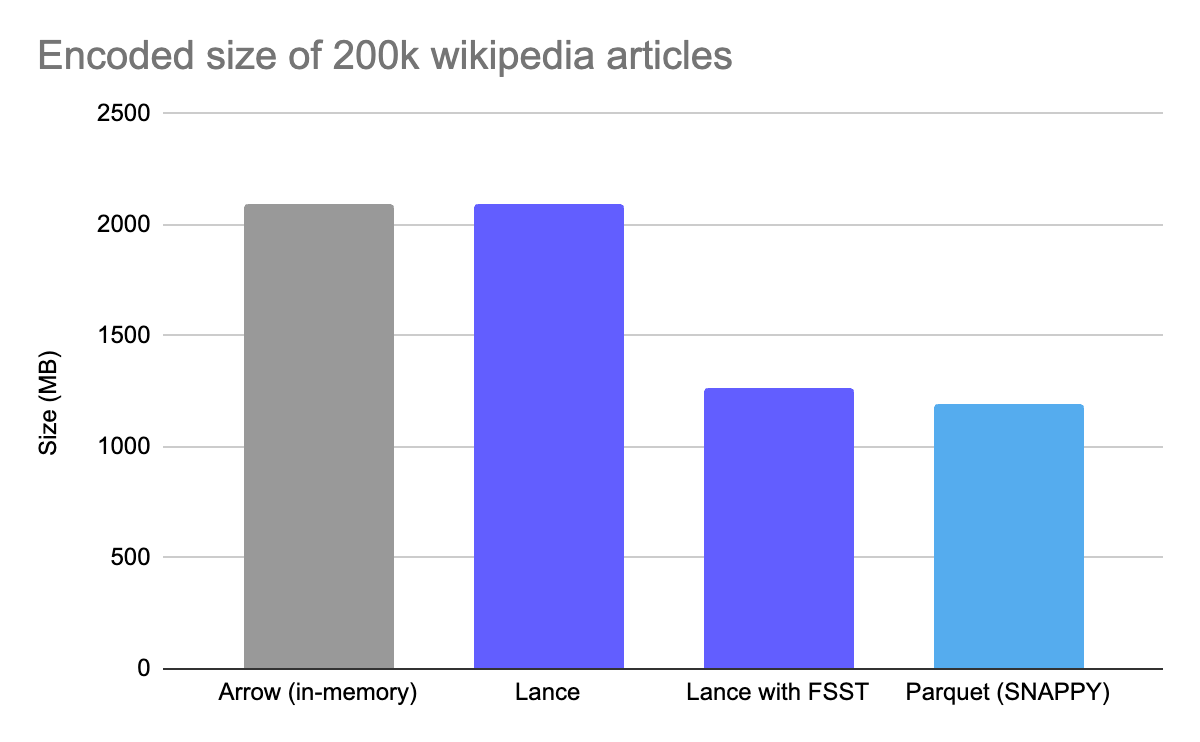
FSST in Lance is available for the Lance V2 format behind an environment variable. To try it out, set the LANCE_USE_FSST to true and pass the flag use_legacy_format=False when writing data. FSST compression will become available by default in a future version of Lance.
Our Rust implementation of FSST was developed by community member Jun Wang (broccoliSpicy on GitHub) and LanceDB engineer Weston Pace (PR). Big thanks to both of them. You can follow the progress of this feature in the FSST epic.
Packed struct encoding
In addition to better string compression, we also have released an experimental encoding for struct columns that makes them better for random access. Currently, if you read a row of a struct column, we must issue a separate IO call for each sub column. The packed struct encoding puts all the data for a single row together, so a full row can be retrieved in a single IO call. This makes random access much faster, including when retrieving rows for a vector search query.
import pyarrow.compute as pc
# 10 columns of random float data
inner_data = pa.table({
f'x{i}': pc.random(1000)
for i in range(10)
}).to_batches()[0]
struct_column = pa.StructArray.from_arrays(inner_data.columns, inner_data.schema.names)
schema = pa.schema([
pa.field('before', struct_column.type),
pa.field('packed', struct_column.type, metadata={b"packed": b"true"})
])
table = pa.table({
'before': struct_column,
'packed': struct_column
}, schema=schema)
dataset = lance.write_dataset(table, "test_packed_struct", use_legacy_format=False)
import random
indices = [random.randint(0, 1000) for _ in range(25)]
%timeit dataset.take([42, 35, 12, 11], columns=['before'])
%timeit dataset.take([42, 35, 12, 11], columns=['packed'])392 μs ± 17.5 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
220 μs ± 1.51 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)That's 40% faster access. This is testing on a local SSD with little throughput. When there is much higher load on the disk or using a higher latency system such as S3, the difference may be more dramatic.
Like the FSST encoding, this is also not turned on by default. To turn this on for a struct column, add the metadata {b"packed": b"true"} to the field in the schema.
This performance improvement has a tradeoff. Reading a single sub column of a struct will be slower with the packed encoding than with the standard "shredded" encoding. Therefore, consider how you will be querying your data before deciding to use packed structs. They aren't the best choice in all cases. For that reason, it will likely never be turned on by default.
Thanks to LanceDB engineer Raunak Shah for implementing this new encoding (PR).
Conclusion
These are the major changes in v0.15.0, but not the only ones. For a full list of changes, see our change log: https://github.com/lancedb/lance/releases/tag/v0.15.0
We continue to innovate on the Lance format, implementing additional index types and encodings. The combination of full-text search and FSST string compression will make Lance a great choice for search. Packed struct layouts will improve retrieval performance for many use cases as well. Together, we are building a more powerful and efficient data lake for the AI era. Your contributions and feedback are crucial as we move forward. We look forward to what we can build together.