This is a LanceDB community blog post written by "Vipul Maheshwari".
This article provides a comprehensive guide on creating a movie recommendation system by using vector similarity search and multi-label genre classification.

Here's what we'll cover:
- Data ingestion and preprocessing techniques for movie metadata
- Training a Doc2Vec model for Embeddings
- Training a Neural network for genre classification task
- Using Doc2Vec, LanceDB and the trained classifier get the relevant recommendations
Let's get started!
Why use embeddings for recommendation systems?
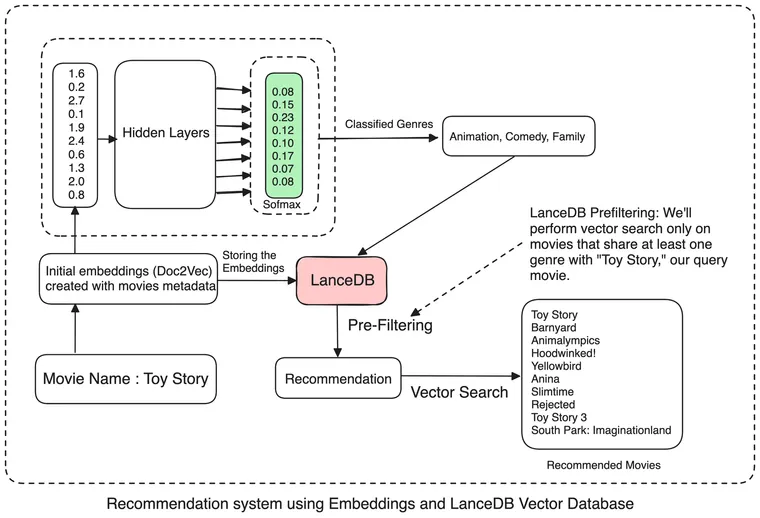
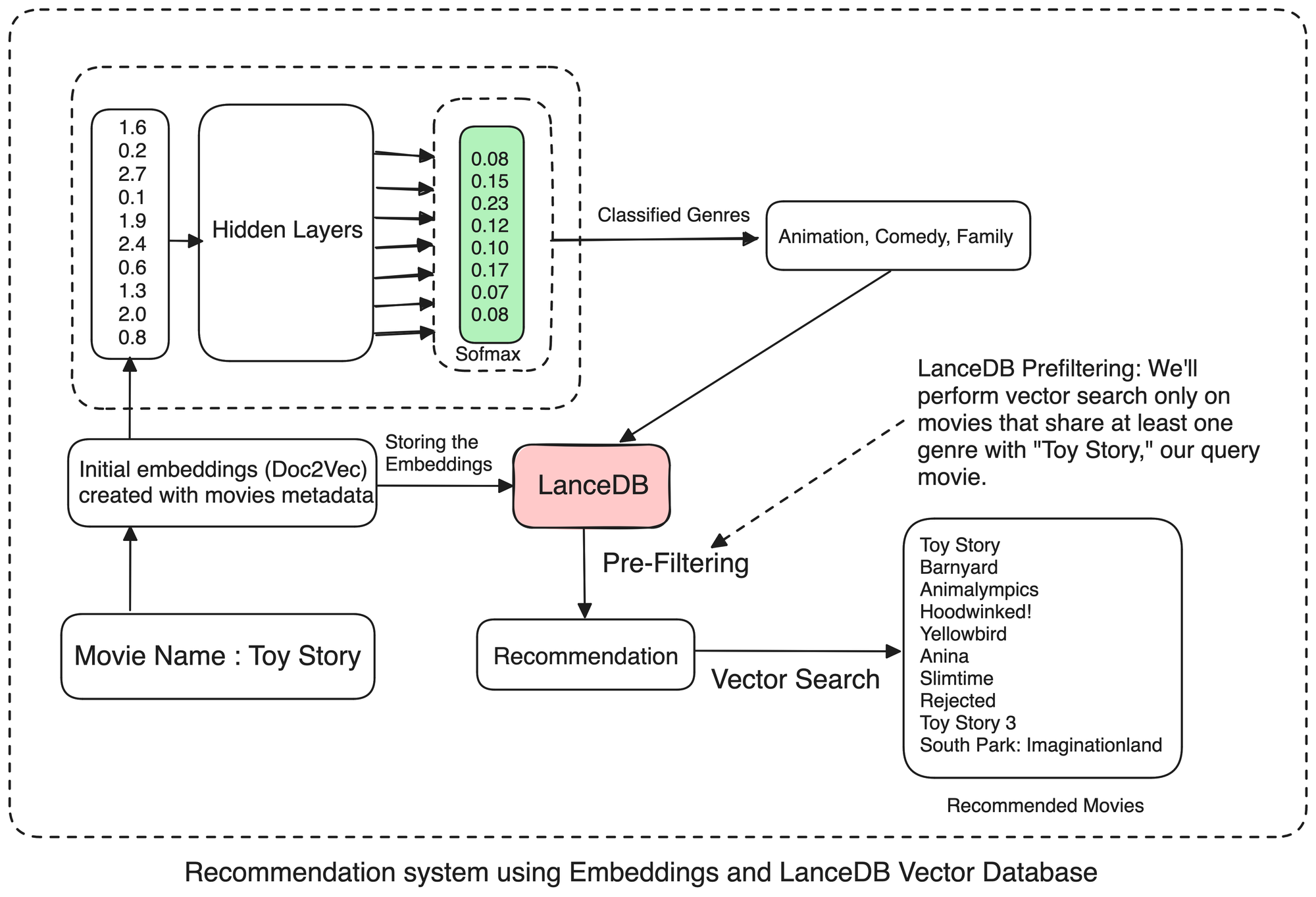
Scrolling through streaming platforms can be frustrating when the movie suggestions don't match our interests. Building recommendation systems is a complex task, as there isn't one metric that can measure the quality of recommendations. To improve this, we can combine embeddings and VectorDB for better recommendations.
These embeddings serve dual purposes: they can either be directly used as input to a classification model for genre classification or stored in a VectorDB for retrieval purposes. By storing embeddings in a VectorDB, efficient retrieval and query search for recommendations become possible at a later stage.
This architecture offers a holistic understanding of the underlying processes involved.
Data Ingestion and preprocessing techniques for movie metadata
Our initial task involves gathering and organizing information about movies. This includes gathering extensive details such as the movie's type, plot summary, genres, audience ratings, and more.
Fortunately, we have access to a robust dataset on Kaggle containing information from various sources for approximately 45,000 movies. To follow along, please download the data from Kaggle and place it inside your working directory.
If you require additional data, you can supplement the dataset by extracting information from platforms like Rotten Tomatoes, IMDb, or even box-office records.
Our next step is to extract the core details from this dataset and generate a universal summary for each movie. Initially, I'll combine the movie's title, genres, and overviews into a single textual string. Then, this text will be tagged to create TaggedDocument instances, which will be utilized to train the Doc2Vec model later on.
Before moving forward, let's install the relevant libraries to make our life easier.
!pip install torch scikit-learn lancedb nltk gensim lancedb scipy==1.12 kaggle pandas numpyNext, we'll proceed with the ingestion and preprocessing of the data. To simplify the process, we'll work with chunks of 1000 movies at a time. For clarity, we'll only include movie indices with non-null values for genres, accurate titles, and complete overviews. This approach ensures that we're working with high-quality, relevant data for our analysis.
import torch
import pandas as pd
import numpy as np
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
from nltk.tokenize import word_tokenize
from tqdm import tqdm
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
from nltk.tokenize import word_tokenize
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.model_selection import train_test_split
from tqdm import tqdm
import nltk
nltk.download('punkt')
# Read data from CSV file
movie_data = pd.read_csv('movies_metadata.csv', low_memory=False)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def preprocess_data(movie_data_chunk):
tagged_docs = []
valid_indices = []
movie_info = []
# Wrap your loop with tqdm
for i, row in tqdm(movie_data_chunk.iterrows(), total=len(movie_data_chunk)):
try:
# Constructing movie text
movies_text = ''
genres = ', '.join([genre['name'] for genre in eval(row['genres'])])
movies_text += "Overview: " + row['overview'] + '\n'
movies_text += "Genres: " + genres + '\n'
movies_text += "Title: " + row['title'] + '\n'
tagged_docs.append(TaggedDocument(words=word_tokenize(movies_text.lower()), tags=[str(i)]))
valid_indices.append(i)
movie_info.append((row['title'], genres))
except Exception as e:
continue
return tagged_docs, valid_indices, movie_infoGenerating embeddings using Doc2Vec
Next, we'll utilize the Doc2Vec model to generate embeddings for each movie based on the preprocessed text. We'll allow the Doc2Vec model to train for several epochs to capture the essence of the various movies and their metadata in the multidimensional latent space. This process will help us represent each movie in a way that captures its unique characteristics and context.
def train_doc2vec_model(tagged_data, num_epochs=20):
# Initialize Doc2Vec model
doc2vec_model = Doc2Vec(vector_size=100, min_count=2, epochs=num_epochs)
doc2vec_model.build_vocab(tqdm(tagged_data, desc="Building Vocabulary"))
for epoch in range(num_epochs):
doc2vec_model.train(tqdm(tagged_data, desc=f"Epoch {epoch+1}"), total_examples=doc2vec_model.corpus_count, epochs=doc2vec_model.epochs)
return doc2vec_model
# Preprocess data and extract genres for the first 1000 movies
chunk_size = 1000
tagged_data = []
valid_indices = []
movie_info = []
for chunk_start in range(0, len(movie_data), chunk_size):
movie_data_chunk = movie_data.iloc[chunk_start:chunk_start+chunk_size]
chunk_tagged_data, chunk_valid_indices, chunk_movie_info = preprocess_data(movie_data_chunk)
tagged_data.extend(chunk_tagged_data)
valid_indices.extend(chunk_valid_indices)
movie_info.extend(chunk_movie_info)
doc2vec_model = train_doc2vec_model(tagged_data)The train_doc2vec_model function trains a Doc2Vec model on the tagged movie data, producing 100-dimensional embeddings for each movie. These embeddings act as input features for the neural network.
With our current training setup, we are sure that movies with identical genres and similar kinds of overviews will be positioned closer to each other in the latent space, reflecting their thematic and content similarities.
Extracting the unique genre labels
Next, our focus shifts to compiling the names of relevant movies along with their genres. Now won
To illustrate this, Let's consider a movie with three genres: 'Drama', 'Comedy', and 'Horror'. Using the MultiLabelBinarizer, we'll represent these genres with lists of 0s and 1s. If a movie belongs to a particular genre, it will be assigned a 1; if it doesn't, it will receive a 0. Now each row in our dataset will indicate which genres are associated with a specific movie. This approach simplifies the genre representation for easier analysis.
Let's take the movie "Top Gun Maverick" as a reference. We'll associate its genres using binary encoding. Suppose this movie is categorized only under 'drama', not 'comedy' or 'horror'. When we apply the MultiLabelBinarizer, the representation would be: Drama: 1, Comedy: 0, Horror: 0. This signifies that "Top Gun Maverick" is classified as a drama but not as a comedy or horror. We'll replicate this process for all the movies in our dataset to identify the unique genre labels present in our data.
Training a Neural Network for genre classification task
We'll define a neural network consisting of four linear layers with ReLU activations. The final layer utilizes softmax activation to generate probability scores for various genres. If your objective is primarily classification within the genre spectrum, where you input a movie description to determine its relevant genres, you can establish a threshold value for the multi-label softmax output. This allows you to select the top 'n' genres with the highest probabilities.
Here's the neural network class, hyperparameter settings, and the corresponding training loop for training our model.
# Extract genre labels for the valid indices
genres_list = []
for i in valid_indices:
row = movie_data.loc[i]
genres = [genre['name'] for genre in eval(row['genres'])]
genres_list.append(genres)
mlb = MultiLabelBinarizer()
genre_labels = mlb.fit_transform(genres_list)
embeddings = []
for i in valid_indices:
embeddings.append(doc2vec_model.dv[str(i)])
X_train, X_test, y_train, y_test = train_test_split(embeddings, genre_labels, test_size=0.2, random_state=42)
X_train_np = np.array(X_train, dtype=np.float32)
y_train_np = np.array(y_train, dtype=np.float32)
X_test_np = np.array(X_test, dtype=np.float32)
y_test_np = np.array(y_test, dtype=np.float32)
X_train_tensor = torch.tensor(X_train_np)
y_train_tensor = torch.tensor(y_train_np)
X_test_tensor = torch.tensor(X_test_np)
y_test_tensor = torch.tensor(y_test_np)
class GenreClassifier(nn.Module):
def __init__(self, input_size, output_size):
super(GenreClassifier, self).__init__()
self.fc1 = nn.Linear(input_size, 512)
self.bn1 = nn.BatchNorm1d(512)
self.fc2 = nn.Linear(512, 256)
self.bn2 = nn.BatchNorm1d(256)
self.fc3 = nn.Linear(256, 128)
self.bn3 = nn.BatchNorm1d(128)
self.fc4 = nn.Linear(128, output_size)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=0.2) # Adjust the dropout rate as needed
def forward(self, x):
x = self.fc1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc3(x)
x = self.bn3(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc4(x)
return x
# Move model to the selected device
model = GenreClassifier(input_size=100, output_size=len(mlb.classes_)).to(device)
# Define loss function and optimizer
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Training loop
epochs = 50
batch_size = 64
train_dataset = TensorDataset(X_train_tensor.to(device), y_train_tensor.to(device))
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device) # Move data to device
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(train_loader.dataset)
print(f'Epoch [{epoch + 1}/{epochs}], Loss: {epoch_loss:.4f}')That's it! We've successfully trained a neural network for our genre classification task. Let's test how our model is performing on the genre classification task.
from sklearn.metrics import f1_score
model.eval()
with torch.no_grad():
X_test_tensor, y_test_tensor = X_test_tensor.to(device), y_test_tensor.to(device) # Move test data to device
outputs = model(X_test_tensor)
test_loss = criterion(outputs, y_test_tensor)
print(f'Test Loss: {test_loss.item():.4f}')
thresholds = [0.1] * len(mlb.classes_)
thresholds_tensor = torch.tensor(thresholds, device=device).unsqueeze(0)
# Convert the outputs to binary predictions using varying thresholds
predicted_labels = (outputs > thresholds_tensor).cpu().numpy()
# Convert binary predictions and actual labels to multi-label format
predicted_multilabels = mlb.inverse_transform(predicted_labels)
actual_multilabels = mlb.inverse_transform(y_test_np)
# Print the Predicted and Actual Labels for each movie
for i, (predicted, actual) in enumerate(zip(predicted_multilabels, actual_multilabels)):
print(f'Movie {i+1}:')
print(f' Predicted Labels: {predicted}')
print(f' Actual Labels: {actual}')
# Compute F1-score
f1 = f1_score(y_test_np, predicted_labels, average='micro')
print(f'F1-score: {f1:.4f}')
# Saving the trained model
torch.save(model.state_dict(), 'trained_model.pth')A movie recommendation system
To build a movie recommendation system, we'll allow users to input a movie name, and based on that, we'll return relevant recommendations. We'll save our Doc2Vec embeddings in a vector database to achieve this. When a user inputs a query in the form of a new movie, we'll first locate its embeddings in our vector database. Once we have this, we'll find the 'n' number of movies whose embeddings are similar to our query movie. We can assess the similarity using various search algorithms like cosine similarity or finding the least Euclidean distance.
We'll organize the data and the embeddings into a CSV file.
import lancedb
import numpy as np
import pandas as pd
data = []
for i in valid_indices:
embedding = doc2vec_model.dv[str(i)]
title, genres = movie_info[valid_indices.index(i)]
data.append({"title": title, "genres": genres, "vector": embedding.tolist()})
db = lancedb.connect(".db")
tbl = db.create_table("doc2vec_embeddings", data, mode="Overwrite")
db["doc2vec_embeddings"].head()Essentially, we establish a connection to LanceDB, set up our table, and add our movie data to it.
Each row in the table represents a single movie, with columns containing data like the title, genres, overview, and embeddings. For each movie title, we check if it exists in our dataset. If it does, we perform a cosine similarity search on all other movies and return the top 10 most relevant titles. This columnar format makes it easy to store and retrieve information for various tasks involving embeddings.
Using Doc2Vec Embeddings to get the relevant recommendations.
Our recommendation engine combines a neural network-based genre prediction model with a vector similarity search to provide relevant movie recommendations.
For a given query movie, first, we use our trained neural network to predict its genres. Based on these predicted genres, we filter our movie database to include only those movies that share at least one genre with the query movie, achieved by constructing an appropriate SQL filter.
We then perform a vector similarity search on this filtered subset to retrieve the most similar movies based on their vector representations. This approach ensures that the recommended movies are not only similar in terms of their vector characteristics but also share genre preferences with the query movie, resulting in more relevant and personalized recommendations.
# Function to get genres for a single movie query
def get_genres_for_query(model, query_embedding, mlb, thresholds, device):
model.eval()
with torch.no_grad():
query_tensor = torch.tensor(query_embedding, dtype=torch.float32).unsqueeze(0).to(device)
outputs = model(query_tensor)
thresholds = [0.001] * len(mlb.classes_)
thresold_tensor = torch.tensor(thresholds, device=device).unsqueeze(0)
predicted_labels = (outputs >= thresold_tensor).cpu().numpy()
predicted_multilabels = mlb.inverse_transform(predicted_labels)
return predicted_multilabels
def movie_genre_prediction(movie_title):
movie_index = movie_data.index[movie_data['title'] == movie_title].tolist()[0]
query_embedding = doc2vec_model.dv[str(movie_index)]
predicted_genres = get_genres_for_query(model, query_embedding, mlb, [0.1] * len(mlb.classes_), device=device)
return predicted_genres
And now, after all the groundwork, we've arrived at the final piece of the puzzle. Let's generate some relevant recommendations using embeddings and LanceDB.
def get_recommendations(title):
pd_data = pd.DataFrame(data)
title_vector = pd_data[pd_data["title"] == title]["vector"].values[0]
predicted_genres = movie_genre_prediction(title)
genres_movie = predicted_genres[0] # Assuming predicted_genres is available
genre_conditions = [f"genres LIKE '%{genre}%'" for genre in genres_movie]
where_clause = " OR ".join(genre_conditions)
result = (
tbl.search(title_vector)
.metric("cosine")
.limit(10)
.where(where_clause)
.to_pandas()
)
return result[["title"]]get_recommendations("Toy Story")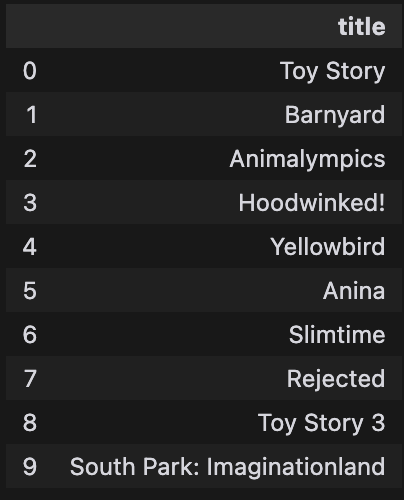
Some of the recommended movies are remarkably close matches. For example, when looking at "Toy Story," which falls under "animation" and "family" movies, our recommendation system can find other movies in these genres.
Conclusion
In this blog, we've crafted a movie recommendation system that delivers highly relevant and personalized movie suggestions by combining neural network-based genre prediction with vector similarity search.
Follow through Google Colab for complete code

