
I’ve been building data tooling for ML/AI for almost two decades, beginning with being one of the original contributors to pandas. My cofounder Lei Xu and I have both spent years bridging the world of databases with the world of models and predictions. One constant throughout my career has been the fact that data has always been crucial for the quality of ML/AI models and applications. This is still true for AI today.
The Problem With AI Data
But some things are different. In production, data isn’t just manually typed in - it’s now being generated at thousands of tokens per second. It’s not uncommon for even a small startup to encounter billions of embeddings, trillions of tokens, and petabytes of images or videos. Scale sneaks up on you and is even bigger than before.
AI data and workloads are also different. From embeddings to images and videos, AI data is bigger and more complex than traditional tabular data. From search and retrieval, to fine-tuning and pre-training, workloads are also more diverse than traditional OLAP.
Existing data formats and systems are ill-equipped to deal with these new challenges. AI teams must deal with slow performance, greater complexity, and much higher costs. It means that your most expensive hires are spending way too much time dealing with low level data details. And it also leads to significantly longer time-to-market for AI products.
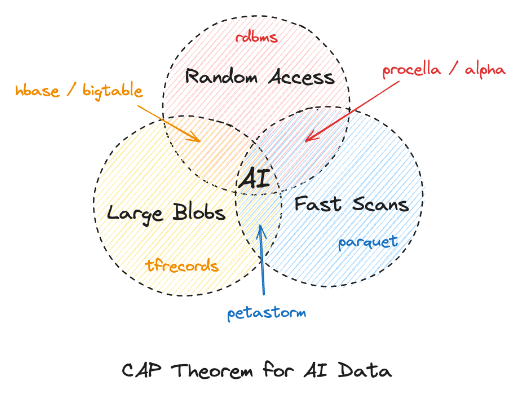
A Better Foundation
AI teams deserve a better solution for managing their data. We have to be able to imagine a better Pareto frontier. To do that we’re refreshing the foundation for data, which was laid out for large tabular datasets a decade ago.
We designed Lance format as a new open source columnar standard optimized for multimodal data. For many AI workloads, Lance delivers up to several orders of magnitude faster performance than traditional formats like parquet. It also comes with an indexing subsystem that delivers blazing speed for vector search and filter pushdowns.
Around this core, we’re building LanceDB, the database for multimodal AI. LanceDB is able to deliver unparalleled scalability for semantic search using an order of magnitude less infrastructure than vector databases. It supports interactive data exploration on petabyte-scale AI data. And it drastically reduces the cost of managing multimodal datasets for training and fine tuning. By delivering all of these in a single package, LanceDB helps AI teams scale better, train faster, and get to production way easier than ever before.
A Thank You to the Community
Open source has been a passion throughout my career and I’m humbled that Lance and LanceDB are now being used by so many. As of this post, I count just shy of one million downloads per month across our various supported languages.
I’m also honored to be working with companies at the forefront of multimodal generative AI like Midjourney and Character.ai, and leading tech companies like Hex and Airtable building compelling AI applications. I'm grateful for the trust they've placed in us. You can check out our website for more information on why they, and many others, are choosing LanceDB.
The Right Partners Make All the Difference
An ambitious vision cannot be realized without the right partners. Today we’re thrilled to announce LanceDB’s Seed round led by CRV, bringing our company’s total funding to $11 million. CRV’s track record of working with early stage founders and deep understanding of AI infrastructure made it a no brainer.
We’re also grateful for YCombinator, Swift Ventures, Essence Ventures, and many other great investors, as well as amazing advisors like Wes McKinney, who believe in us and share our vision for the future. With this new round of capital we’ll be able to grow the team and better serve our customers as well as the broader open-source community for AI.
We’re Just Getting Started
We all have five senses and AI is already following suit. These new models and applications require managing multimodal data at unprecedented scale and complexity. Dealing with these new challenges requires a new foundation.
The LanceDB team comprises major contributors of Arrow, Delta, Polars, HDFS, pandas, and many other important open source projects. If you’ve worked with data in the past decade, chances are you’ve used the tools we’ve built in the past. We strongly believe the new foundation for AI data must be open source, so that the future of AI can be open.

We’d love to hear from you. If you’re building AI in production and want a better way to manage your data, drop us a line in the LanceDB Discord or send us an email at contact@lancedb.com.