The API used to read files has evolved over time, from simple "full table" reads to batch reads and eventually to iterative "record batch readers". These more sophisticated APIs add additional power and flexibility. Lance takes this a step further to return a "stream of read tasks". This originates from our decision to separate scheduling from decode and enables operator fusion. The decode work can be fused into later steps in a query pipeline. In this article, I briefly recap the different APIs, talk about Lance's approach, and then show some results explaining the benefits.
Full Table Reads
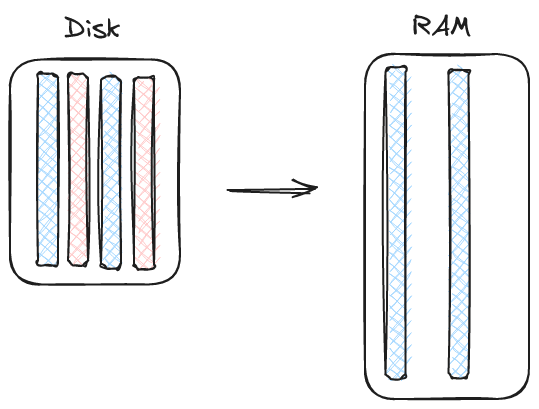
To kick off our history of read APIs we can start with the most basic API, a full table read. Its main power is simplicity. Given a file, create a table. This can be a large contiguous table like what you would get from pandas read_parquet or an internally chunked table like what you get from pyarrow's parquet.read_table. The pros and cons are pretty straightforward.
Pros:
✅ Simplicity
Cons:
❌ Only works if the entire file fits in memory
❌ No fusion of decode and query
The downside here is very limiting. We generally expect that files will be larger than memory. Even if the file isn't (maybe we partitioned a huge dataset into many small files) we still probably want to stream through our data so our reader doesn't require an embarrassing amount of RAM. If we try and make the files even smaller then the per-file overhead is too great. This approach is not suitable for large scale search tasks. We also don't get any fusion, we'll talk about that later.
Read Batch
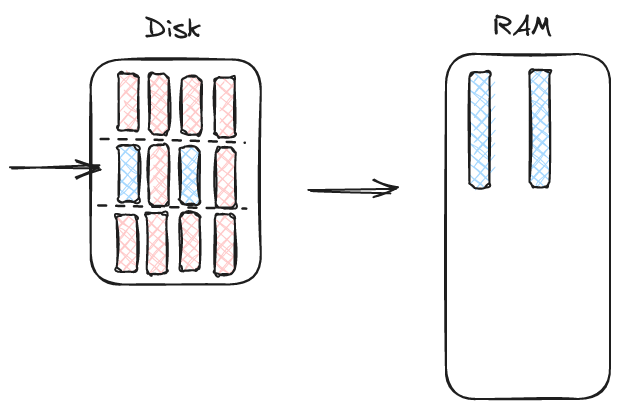
The next API is also pretty simple. We take in a file and a "batch number" and return a batch of data.
Pros:
✅ Simplicity
🟡 Better control over memory
Cons:
🟡 Requires agreed upon definition of a batch
🟡 Often requires the user get involved in parallelism
❌ No fusion of decode and query
This API is pretty popular in Parquet which has a row group concept and thus a natural concept of "batches". A good example is pyarrow's ParquetFile.read_row_group. Unfortunately, it requires the writer to decide what resolution the reader will use for reading the file. Also, batches encourage per-batch parallelism which is something we wanted to explicitly avoid in LanceDB (explained in an earlier post). For example, we get things like this advice from DuckDb:
DuckDB works best on Parquet files with row groups of 100K-1M rows each. The reason for this is that DuckDB can only parallelize over row groups – so if a Parquet file has a single giant row group it can only be processed by a single thread.
In addition, we force the user to decide how many groups to read at once. This often forces the user to make inconvenient decisions based on I/O parallelism. For example, if I'm reading a single column I probably want to read many groups at once. If I'm reading many columns then I don't. This is a complexity that users would rather not deal with.
Record Batch Reader
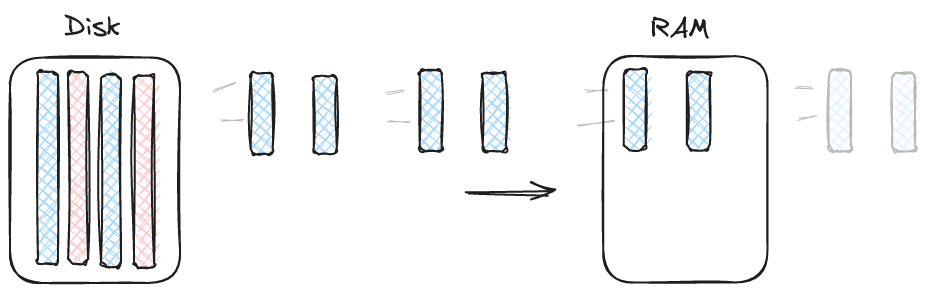
Finally we reach the modern "record batch reader". This API returns an iterator of batches (synchronous or asynchronous).
Pros:
✅ Moves I/O parallelism into the reader
✅ Flexible batch sizes
✅ Low memory requirements
Cons:
🟡 Slightly more complex
❌ No fusion of decode and query
This API is powerful and it should be no surprise it is popular in modern open source file readers. We can see an example in pyarrow dataset's to_batches or parquet-rs' ParquetRecordBatchReader. The batch size is now very flexible. If a user wants small batches then a reader can deliver them. This is even true in formats like Parquet that use row groups because the reader can iterate over data pages without requiring a full read of the row group (provided the row group is large enough. Very small row groups can still sabotage this kind of approach). Note that only parquet-rs' implementation actually does this correctly. Pyarrow's implementation still largely relies on appropriately sized row groups (it iterates in smaller batches but still loads entire row groups into memory).
Perilous parallelism
Both of the examples I've provided have slightly different approaches to parallelism than Lance. This is not technically a fault of the API but it does motivate our decision for a different API and so I'll explain briefly.
Pyarrow's dataset reader achieves parallelism through "batch readahead".
In parquet-rs parallelism is provided by creating multiple record batch readers by splitting up the row groups. Both approaches have drawbacks.
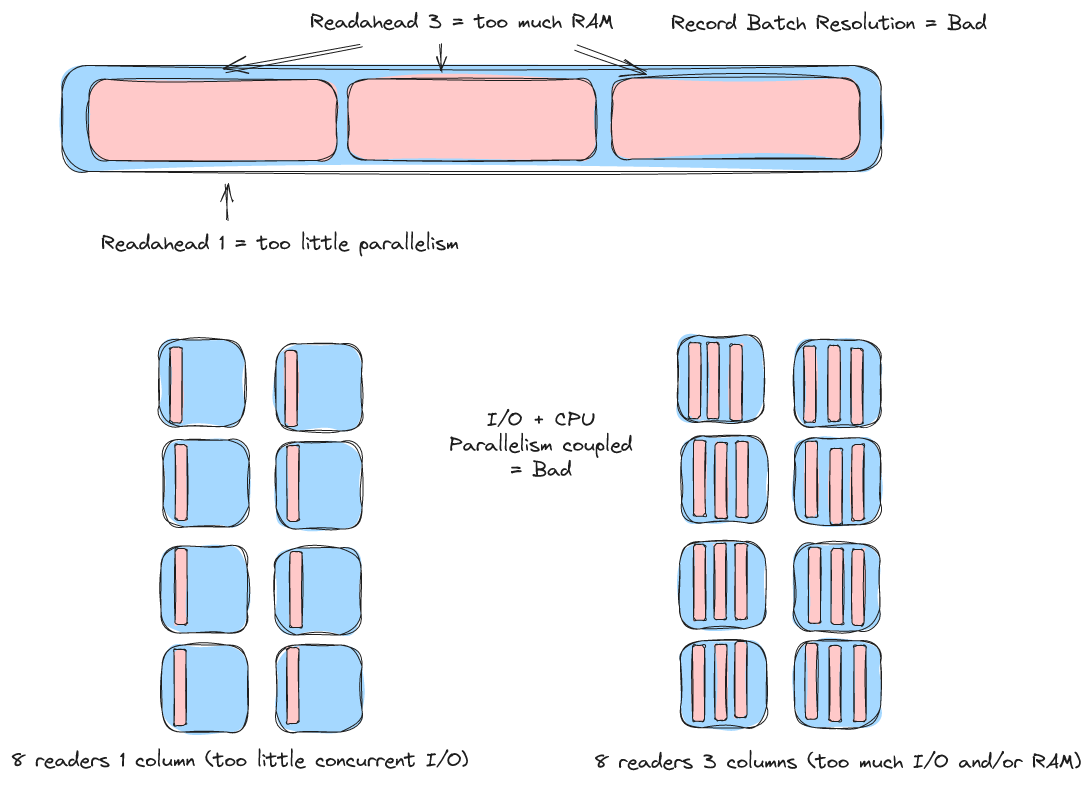
The multiple readers approach forces the user to make I/O parallelism decisions. The user must pick how many readers to create and this depends on the filesystem, the number of columns being read, the size of those columns, and is just plain tricky to calculate.
The pyarrow readahead approach avoids the multiple readers problem but is flawed because of the previously mentioned limitation that pyarrow still requires full record batch reads. Achieving sufficient parallelism is almost guaranteed to require too much memory or too small row groups (and expensive file rewrites are required to tweak this parameter).
Note again that these challenges are not a result of the API (record batch reader) but rather a limitation with other aspects of the implementations.
Can we do better?
If we implement an ideal record batch reader API, is this the best we can do? It turns out the answer is "no". To demonstrate this I hooked up the Lance file reader to the Apache Datafusion query engine (we use Datafusion extensively in Lance and are big fans). I then ran TPC-H query 6 which is simple but has a filter step that should at least introduce some compute work. I tested with TPC-H scale factor 10 and I tested the case where the data was hot in the kernel page cache to avoid being I/O bound (which is not always realistic but important for today and I'll leave the rest of that discussion for a future blog post). I tested with both a record batch reader and with what Lance calls a "read task reader". Note, I am testing the Lance format in both cases.
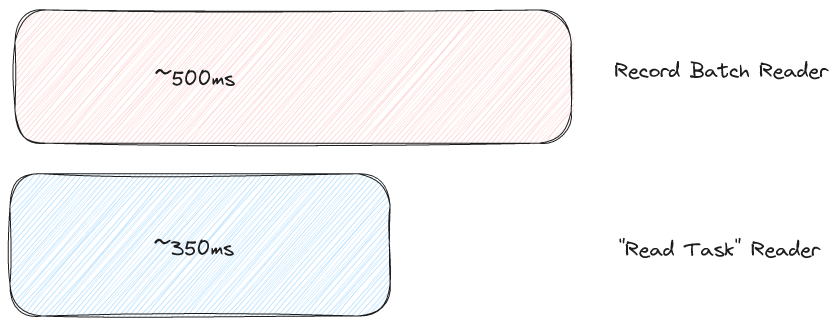
What's going on?
To help illustrate the difference I used the Intel vTune profiler to profile the slower approach:

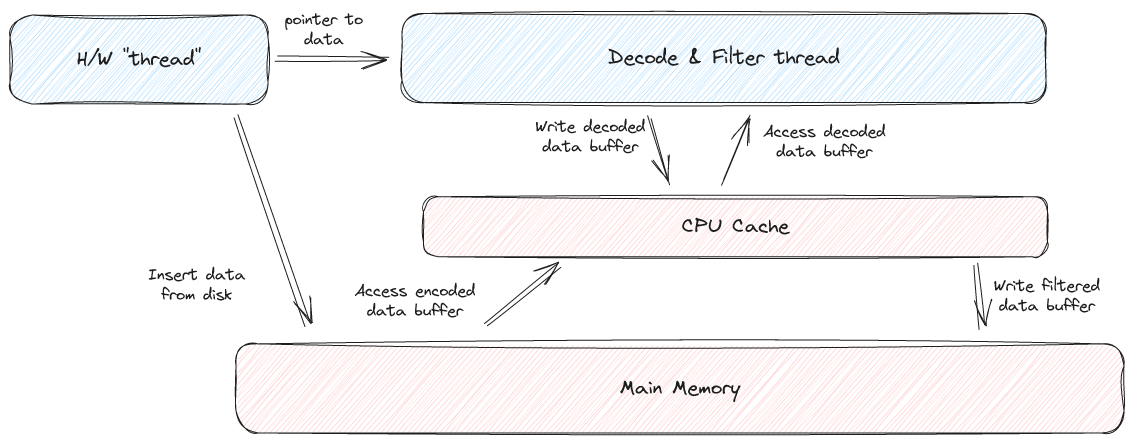
100% "memory bound" might not be something that developers are used to seeing 😄. It's certainly not something I ever encountered before working on query engines. However, memory latency / bandwidth, and it's companion "cache utilization", are real issues in query engine design. To understand what is going on here we have to really break down the scanning process.
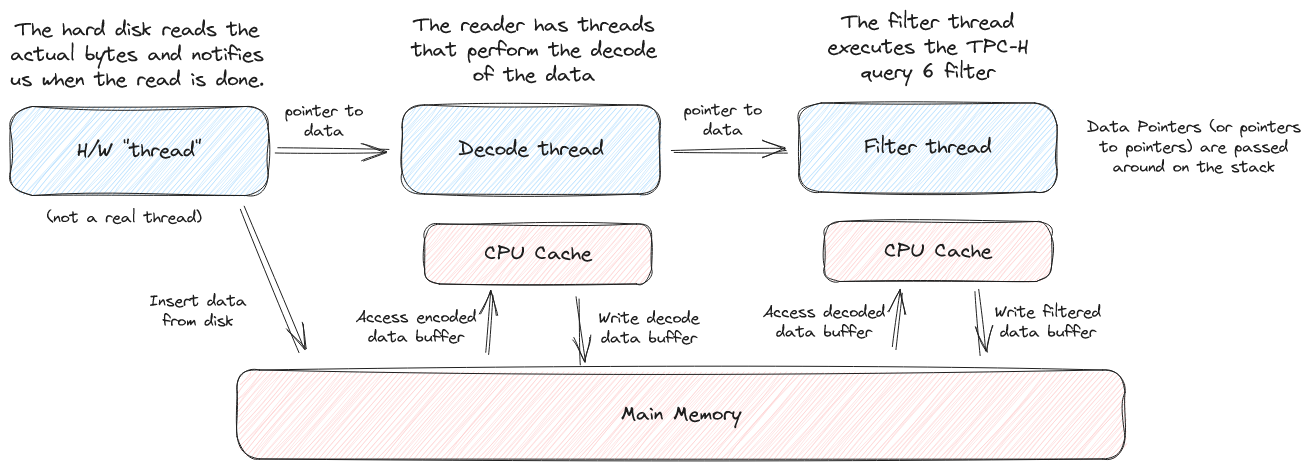
Both the decode thread and the filter thread are accessing main memory. The decode thread pulls data out of main memory, places it in the CPU cache / registers, decodes the data, and then puts it back into main memory. The filter thread then reads this decoded data from main memory. Ideally, we want to find some way to avoid that trip to main memory.
Here's a simple analogy. Let's imagine we have two chefs making sandwiches. We could divide the work amongst chefs (we're just going to imagine they store their bread in the refrigerator for some reason):
- Chef A
- Go into the fridge and get two slices of bread and a jar of mayo
- Apply mayonnaise on the two slices of bread
- Put the bread slices back in the fridge
- Chef B
- Go into the fridge and get one slice of turkey and two slices of bread with mayo (from chef A)
- Put the turkey on the bread
- Put the finished sandwich in the fridge
Alternatively, we could have both chefs do the same thing:
- Chef A & B:
- Go into the fridge, get two slices of bread, a jar of mayo, and one slice of turkey
- Make a sandwich
- Put the finished sandwich back in the fridge
These both seem like reasonable approaches to making sandwiches. However, let's now move the fridge 400 meters away from the workstation. Suddenly the first approach is much less appealing because it requires two trips to the refrigerator per sandwich.
Fusion to the rescue
The solution to this problem is a concept sometimes described as "operator fusion" (the concept is also sometimes referred to as "data parallelism").
Operator fusion is a way to improve performance by merging one operator [..] into a different operator so that they are executed together without requiring a roundtrip to memory
In order to do any kind of work on data we have to move it from main memory into the CPU cache (and into the registers). If we can perform two operations back to back then we can avoid a round trip to main memory. Here is a simple example that doesn't even use threads:
# Two passes through the data (no fusion)
def decode(data_stream):
decoded = []
for cache_sized_batch in data_stream:
decoded.append(decode(cache_sized_batch))
return decoded
def filter(data_stream):
filtered = []
for cache_sized_batch in data_stream:
filtered.append(filter(cache_sized_batch))
return filtered
decoded_and_filtered = filter(decode(data_stream))
# One pass through the data (fused)
def decode(data_stream):
for cache_sized_batch in data_stream:
yield decode(cache_sized_batch)
def filter(data_stream):
for cache_sized_batch in data_stream:
yield filter(cache_sized_batch)
decoded_and_filtered = list(filter(decode(data_stream)))This example points out a neat point. "Fusing" two operators does not mean they need to be mashed into a single method. It only means that we need to avoid running the operations on two different and distinct passes through the data (or two different CPU cores).
"Read Task" Reader
This leads us to the newest file reader API, utilized by Lance, which is an iterator of "read tasks". A read task performs the actual decode from the on-disk format into the desired in-memory layout of the data.
Pros:
✅ Moves I/O parallelism into the reader
✅ Flexible batch sizes
✅ Low memory requirements
✅ Fusion of decode and query
Cons:
🟡 Slightly more complex
The read task reader is the API used by Lance. Actually, Lance offers all of the above APIs as convenience APIs, but they delegate to the read task reader.
The read task reader supports all of the features we want. The user can choose whatever batch size they would like. Read tasks are delivered quickly and (mostly) synchronously. Parallelism in Lance is done by read ahead. The user picks how many batches they want to compute in parallel and grabs that many read tasks (rust streams make this easy with the buffered API).
Here are a few charts demonstrating these benefits as well as some of the performance characteristics of the Lance file reader.
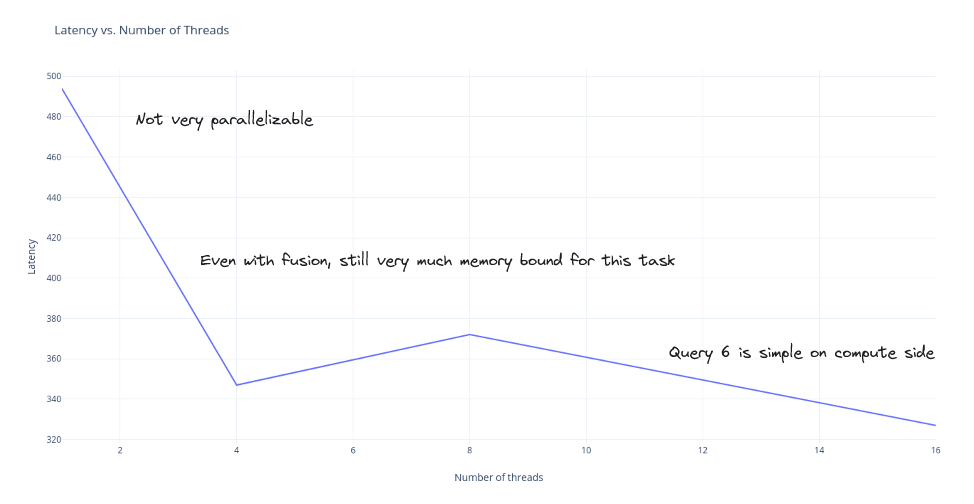
The I/O parallelism is completely independent from the CPU parallelism. The user can grab 20 read tasks or a single read task at a time and it will have no affect on how much parallel I/O the reader performs (assuming the user is keeping up and back pressure is not applied). An added bonus is that we will never read the file out of order (there is simply no reason to do so).
Finally, because the decode task is executed by the user (the query engine), we now have the ability for operators to be fused:
Does it matter?
Operator fusion is a "query engine best practice" and we wanted to make sure we handle it. However, it is one of those things that is incredibly difficult to prove useful in actual practice. In many situations it doesn't matter.
- If you're I/O bound then it doesn't matter
- If you're not highly parallel then it doesn't matter (prefetch hides RAM latency)
- If you're not doing any CPU work then it doesn't matter
- If you need to cross a language boundary then you cannot (today) fuse the work (there is no "read task reader" in the C data interface)
- RAM bandwidth is skyrocketing in modern systems
Still, in the situations where it does matter, it's a great tool to have available. Also, just to test that last bullet point I tried running the experiment on my macbook (the M1 has a staggering amount of RAM bandwidth) and still saw considerable speedup with the fused approach (and an incredible 220ms runtime, the M1 is an awesome chip). My best guess is the prefetch isn't entirely able to overcome the latency but these effects are hard to measure.
What about Parquet?
Nothing I've talked about in this blog post is particular to the Lance file format. A Parquet file reader can (and maybe should) be written that separates scheduling from decode and allows for decode / query fusion.
There is one caveat: it may not be possible to create such a reader when generalized block compression is used (e.g. snappy, gzip). This is because compression blocks don't normally line up across columns / batch sizes. This means you either have to run the decompression multiple times or you have to run the decompression on a separate thread from the query. On the other hand, it may be possible to size your compression blocks so that they all have the same # of rows (or divide into some common number) and then use this as your batch size. However, this only applies to full range reads, which is something we don't want to rely on in Lance.
Lastly, I should mention that there has been a lot of recent activity and discussion on the Parquet mailing list about potentially creating a new Parquet version. This is pretty cool and we are following along. Maybe someday the Lance writer can create files that are parquet-reader-compatible but still performant for our random access use cases.
P.S. (fun trivia)
The fact that I am using DataFusion to demonstrate operator fusion did not escape my notice. I wondered if it was a coincidence or if the DataFusion name was inspired by operator fusion in some way and so I asked on the DataFusion discord where Andy Grove revealed that yes, it was indeed a coincidence.
my algorithm for coming up with product names is to write one list of words that are closely related to the project (so "data" came from that list) and then a bunch of random words that I think sound cool so that included things like "fire", "storm", "fusion" and then pair words together. I also felt that I could come up with some meaning later about how fusion could be justified, but I don't recall if I was aware of the concept of operator fusing back then. Also, I was driving a Ford Fusion at the time, which was a possible influence 😃
-Andy Grove