
In this article, We use CLIP from OpenAI for Text-to-Image and Image-to-Image searching and we’ll also do a comparative analysis of the Pytorch model, FP16 OpenVINO format, and INT8 OpenVINO format in terms of speedup.
Here are a few Key points converted in this article.
Text-to-Image and Image-to-Image Search using CLIP
- Using the Pytorch model
- Using OpenVINO conversion to speed up by 70%
- Using Quantization with OpenVINO NNCF to speed up by 400%
These results are on 13th Gen Intel(R) Core(TM) i5–13420H using OpenVINO=2023.2 and NNCF=2.7.0 version.
You can take a look at the attached Google Colab to find all the code and easy, quick-start instructions.


CLIP from OpenAI
CLIP (Contrastive Language–Image Pre-training) is a neural network capable of processing both images and text.
CLIP is a multi-modal model, which means it can process both text and images. This capability allows it to embed different types of inputs in a shared multi-modal space, where the positions of images and text have semantic meaning, regardless of their format.
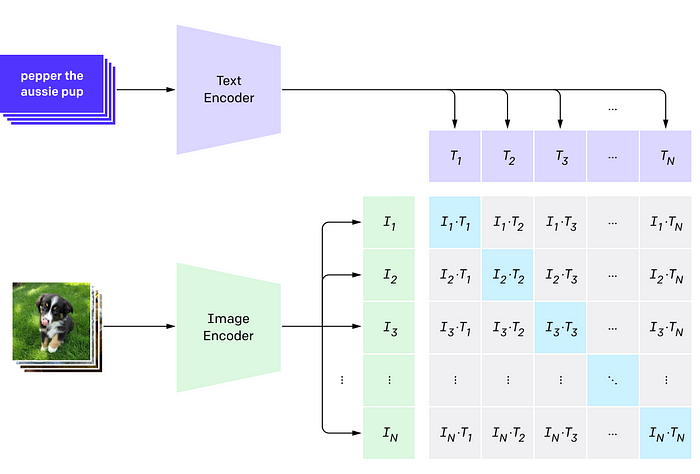
The following image presents a visualization of the pre-training procedure
OpenVINO by Intel
OpenVINO toolkit is a free toolkit facilitating the optimization of a deep learning model from a framework and deploying an inference engine onto Intel hardware. We’ll use the FP16 and INT8 formats using the OpenVINO CLIP model.

This write-up uses OpenVINO to accelerate the LanceDB embedding pipeline.
Implementation
In the Implementation section, we see the comparative implementation of the CLIP model from Hugging Face and OpenVINO formats, using the conceptual caption dataset.
We are starting with the first step of loading the conceptual caption dataset from Hugging Face.
# https://huggingface.co/datasets/conceptual_captions
image_data = load_dataset(
"conceptual_captions", split="train",
)We will select a sample of 100 images from this large number of images
# taking first 100 images
image_data_df = pd.DataFrame(image_data[:100])Helper functions to validate image URLs and get images and captions from image URL
def check_valid_URLs(image_URL):
"""
Not all the URLs are valid. This function returns True if the URL is valid. False otherwise.
"""
try:
response = requests.get(image_URL)
Image.open(BytesIO(response.content))
return True
except:
return False
def get_image(image_URL):
response = requests.get(image_URL)
image = Image.open(BytesIO(response.content)).convert("RGB")
return image
def get_image_caption(image_ID):
return image_data[image_ID]["caption"]# Transform dataframe
image_data_df["is_valid"] = image_data_df["image_url"].apply(check_valid_URLs)
#removing all the in_valid URLs
image_data_df = image_data_df[image_data_df["is_valid"]==True]
image_data_df.head()Now we have prepared the dataset and we are ready to start with CLIP using Hugging Face and OpenVINO and their performance comparative analysis in terms of speed.
Pytorch CLIP using Hugging Face
We’ll start with CLIP using Hugging Face and the time taken to extract embeddings and search using the LanceDB vector database.
def get_model_info(model_ID, device):
"""
Loading CLIP from HuggingFace
"""
# Save the model to device
model = CLIPModel.from_pretrained(model_ID).to(device)
# Get the processor
processor = CLIPProcessor.from_pretrained(model_ID)
# Get the tokenizer
tokenizer = CLIPTokenizer.from_pretrained(model_ID)
# Return model, processor & tokenizer
return model, processor, tokenizer# Set the device
device = "cuda" if torch.cuda.is_available() else "cpu"
model_ID = "openai/clip-vit-base-patch16"
model, processor, tokenizer = get_model_info(model_ID, device)Let’s write a Helper Function to extract Text and Image Embeddings
def get_single_text_embedding(text):
# Get single text embeddings
inputs = tokenizer(text, return_tensors = "pt").to(device)
text_embeddings = model.get_text_features(**inputs)
# convert the embeddings to numpy array
embedding_as_np = text_embeddings.cpu().detach().numpy()
return embedding_as_np
def get_all_text_embeddings(df, text_col):
# Get all the text embeddings
df["text_embeddings"] = df[str(text_col)].apply(get_single_text_embedding)
return dfdef get_single_image_embedding(my_image):
# Get single image embeddings
image = processor(
text = None,
images = my_image,
return_tensors="pt"
)["pixel_values"].to(device)
embedding = model.get_image_features(image)
# convert the embeddings to numpy array
embedding_as_np = embedding.cpu().detach().numpy()
return embedding_as_np
def get_all_images_embedding(df, img_column):
# Get all image embeddings
df["img_embeddings"] = df[str(img_column)].apply(get_single_image_embedding)
return dfConnect LanceDB to store extracted embeddings and search
import lancedb
db = lancedb.connect("./.lancedb")
Extracting Embeddings of 83 images using CLIP Hugging faces model and time taken to extract embeddings.
import time
# extracting embeddings using Hugging Face
start_time = time.time()
image_data_df = get_all_images_embedding(image_data_df, "image")
print(f"Time Taken to extract Embeddings of {len(image_data_df)} Images(in seconds): ", time.time()-start_time)Here are the results:
Time Taken to extract Embeddings of 83 Images(in seconds): 55.79
Ingesting Images and their Embeddings in LanceDB for querying
def create_and_ingest(image_data_df, table_name):
"""
Create and Ingest Extracted Embeddings using Hugging Face
"""
image_url = image_data_df.image_url.tolist()
image_embeddings = [arr.astype(np.float32).tolist() for arr in image_data_df.img_embeddings.tolist()]
data = []
for i in range(len(image_url)):
temp = {}
temp['vector'] = image_embeddings[i][0]
temp['image'] = image_url[i]
data.append(temp)
# Create a Table
tbl = db.create_table(name= table_name, data=data, mode= "overwrite")
return tbl
#create and ingest embeddings for pt model
pt_tbl = create_and_ingest(image_data_df, "pt_table")Query the stored embeddings
Time taken to extract embeddings of all the images and query the stored embeddings
# Get the image embedding and query for each caption
pt_img_results = {}
start_time = time.time()
for i in range(len(image_data_df)):
img_query = image_data_df.iloc[i].image
query_embedding = get_single_image_embedding(img_query).tolist()
#querying with image
result = pt_tbl.search(query_embedding[0]).limit(4).to_list()
pt_img_results[str(i)] = resultCLIP model using FP16 OpenVINO format
Now we’ll start with CLIP F16 OpenVINO format and the time taken to extract embeddings and ingesting in the LanceDB vector database.
import openvino as ov
#saving openvino model
model.config.torchscript = True
ov_model = ov.convert_model(model, example_input=dict(inputs))
ov.save_model(ov_model, 'clip-vit-base-patch16.xml')Compiling the CLIP OpenVINO model
import numpy as np
from scipy.special import softmax
from openvino.runtime import Core
"""
Compiling CLIP in Openvino FP16 format
"""
# create OpenVINO core object instance
core = Core()
# compile model for loading on device
compiled_model = core.compile_model(ov_model, device_name="AUTO", config={"PERFORMANCE_HINT": "CUMULATIVE_THROUGHPUT"})
# obtain output tensor for getting predictionsExtracting Embeddings of 83 images using CLIP FP16 OpenVINO model and time taken to extract embeddings.
import time
#time taken to extract embeddings using CLIP OpenVINO format
start_time = time.time()
image_embeddings = extract_openvino_embeddings(image_data_df)
print(f"Time Taken to extract Embeddings of {len(image_data_df)} Images(in seconds): ", time.time()-start_time)Here are the results:
Time Taken to extract Embeddings of 83 Images(in seconds): 31.79
Ingesting Images and their Embeddings in LanceDB for querying
def create_and_ingest_openvino(image_url, image_embeddings, table_name):
"""
Create and Ingest Extracted Embeddings using OpenVINO FP16 format
"""
data = []
for i in range(len(image_url)):
temp = {}
temp['vector'] = image_embeddings[i]
temp['image'] = image_url[i]
data.append(temp)
# Create a Table
tbl = db.create_table(name= table_name, data=data, mode= "overwrite")
return tbl
# create and ingest embeddings for OpenVINO fp16 model
ov_tbl = create_and_ingest_openvino(image_url, image_embeddings, "ov_tbl")Query the stored embeddingsTime taken to extract embeddings of all the images and query the stored embeddings
# Get the image embedding and query for each caption
ov_img_results = {}
start_time = time.time()
for i in range(len(image_data_df)):
img_query = image_data_df.iloc[i].image
image = image_data_df.iloc[i].image
inputs = processor(images=[image], return_tensors="np", padding=True)
query_embedding = compiled_model(dict(inputs))["image_embeds"][0]
#querying with query image
result = ov_tbl.search(query_embedding).limit(4).to_list()
ov_img_results[str(i)] = resultNNCF INT 8-bit Quantization
Using 8-bit Post Training Optimization from NNCF (Neural Network Compression Framework) and infer quantized model via OpenVINO Toolkit.
%pip install -q datasets
%pip install -q "nncf>=2.7.0"import os
from transformers import CLIPProcessor, CLIPModel
fp16_model_path = 'clip-vit-base-patch16.xml'
#inputs preparation for conversion and creating processor
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch16")
max_length = model.config.text_config.max_position_embeddings
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch16")Helper Functions to convert into Int8 format using NNCF
import requests
from io import BytesIO
import numpy as np
from PIL import Image
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
def check_text_data(data):
"""
Check if the given data is text-based.
"""
if isinstance(data, str):
return True
if isinstance(data, list):
return all(isinstance(x, str) for x in data)
return False
def get_pil_from_url(url):
"""
Downloads and converts an image from a URL to a PIL Image object.
"""
response = requests.get(url, verify=False, timeout=20)
image = Image.open(BytesIO(response.content))
return image.convert("RGB")
def collate_fn(example, image_column="image_url", text_column="caption"):
"""
Preprocesses an example by loading and transforming image and text data.
Checks if the text data in the example is valid by calling the `check_text_data` function.
Downloads the image specified by the URL in the image_column by calling the `get_pil_from_url` function.
If there is any error during the download process, returns None.
Returns the preprocessed inputs with transformed image and text data.
"""
assert len(example) == 1
example = example[0]
if not check_text_data(example[text_column]):
raise ValueError("Text data is not valid")
url = example[image_column]
try:
image = get_pil_from_url(url)
h, w = image.size
if h == 1 or w == 1:
return None
except Exception:
return None
#preparing inputs for processor
inputs = processor(text=example[text_column], images=[image], return_tensors="pt", padding=True)
if inputs['input_ids'].shape[1] > max_length:
return None
return inputsInitializing NNCF and Saving the Quantized Model
import logging
import nncf
from openvino.runtime import Core, serialize
core = Core()
#Initialize NNCF
nncf.set_log_level(logging.ERROR)
int8_model_path = 'clip-vit-base-patch16_int8.xml'
calibration_data = prepare_dataset()
ov_model = core.read_model(fp16_model_path)
if len(calibration_data) == 0:
raise RuntimeError(
'Calibration dataset is empty. Please check internet connection and try to download images manually.'
)
#Quantize CLIP fp16 model using NNCF
calibration_dataset = nncf.Dataset(calibration_data)
quantized_model = nncf.quantize(
model=ov_model,
calibration_dataset=calibration_dataset,
model_type=nncf.ModelType.TRANSFORMER,
)
#Saving Quantized model
serialize(quantized_model, int8_model_path)Compiling the INT8 model and Helper function for extracting features
import numpy as np
from scipy.special import softmax
from openvino.runtime import Core
# create OpenVINO core object instance
core = Core()
# compile model for loading on device
compiled_model = core.compile_model(quantized_model, device_name="AUTO", config={"PERFORMANCE_HINT": "CUMULATIVE_THROUGHPUT"})
# obtain output tensor for getting predictions
image_embeds = compiled_model.output(0)
logits_per_image_out = compiled_model.output(0)
image_url = image_data_df.image_url.tolist()
image_embeddings = []
def extract_quantized_openvino_embeddings(image_data_df, compiled_model):
"""
Extract embeddings of Images using CLIP Quantized model
"""
for i in range(len(image_data_df)):
image = image_data_df.iloc[i].image
inputs = processor(images=[image], return_tensors="np", padding=True)
image_embeddings.append(compiled_model(dict(inputs))["image_embeds"][0])
return image_embeddingsimport time
start_time = time.time()
#time taken to extract embeddings using CLIP OpenVINO format
image_embeddings = extract_quantized_openvino_embeddings(image_data_df, compiled_model)
print(f"Time Taken to extract Embeddings of {len(image_data_df)} Images(in seconds): ", time.time()-start_time)Here are the results
Time Taken to extract Embeddings of 83 Images(in seconds): 13.70
Ingest embeddings into LanceDB
# create and ingest embeddings for OpenVINO int8 model format
qov_tbl = create_and_ingest_openvino(image_url, image_embeddings, "qov_tbl")Time taken to extract embeddings of all the images and query the stored embeddings
# Get the image embedding and query for each caption
ov_img_results = {}
start_time = time.time()
for i in range(len(image_data_df)):
img_query = image_data_df.iloc[i].image
image = image_data_df.iloc[i].image
inputs = processor(images=[image], return_tensors="np", padding=True)
query_embedding = compiled_model(dict(inputs))["image_embeds"][0]
#querying with query image
result = qov_tbl.search(query_embedding).limit(4).to_list()
ov_img_results[str(i)] = resultNow we have the performance throughput of all the CLIP model formats Pytorch from Hugging Face, FP16 OpenVINO, and INT8 OpenVINO.
Conclusion
All these results are on CPU for comparison of the Pytorch model with the OpenVINO model formats(FP16/ INT8)
The time taken to extract Embeddings for 83 Images using CLIP in different formats are
1. Pytorch model from Hugging Face — 55.26 seconds
2. OpenVINO FP16 format — 31.79 seconds
3. OpenVINO INT8 format — 13.70 seconds
The Performance acceleration achieved with the FP16 model is 1.73 times, representing a relatively modest increase in speed compared to expectations.
Conversely, when considering the INT8 OpenVINO format, there is a 4.03 times increase in speed compared to the PyTorch model.
Visit our GitHub if you wish to learn more about LanceDB python and Typescript library.
For more such applied GenAI and VectorDB applications, examples and tutorials visit vectordb-recipes . Don’t forget to leave a star at the repo.
Lastly, for more information and updates, follow our LinkedIn and Twitter.