
Goodhart’s Law: When a measure becomes a target, it ceases to be a good measure
We're excited to have a guest post on our blog today on model inference performance optimization. In this post, Mingran Wang and Tan Li from SambaNova talks about the right metrics to use when it comes to LLM inference performance.
In the world of computer systems, innovation is often driven by several key metrics, and building a LLM system is no exception. However, no single metric can fully capture all system requirements. Thus, selecting metrics that balance each other is crucial for the project’s success. In this blog post, we will examine Tokens per Second, a common metric for evaluating LLM systems, and explore its shortcomings and potential for misleading results in real-world applications.
Throughput vs. Latency
Typically, throughput measures the number of instances processed within a time window, while latency measures the time it takes to process each instance. A common misconception about computer system performance is confusing throughput with latency. Indeed, they complement each other in a powerful balancing loop, i.e. shorter processing times for each instance lead to a higher number of instances processed within a given period, and vice versa. However, in some scenarios, particularly when optimizing for a smooth end user experience, focusing solely on throughput can be misleading. For example, in chatbot applications, users generally prefer receiving a quick initial response followed by a gradual delivery of the rest, rather than receiving all information at once. Therefore, when optimizing UX for Chatbot systems, Time to First Token should be prioritized a bit over Tokens per Second, as it better indicates experienced system latency, whereas the latter measures throughput.
Long Input with Short Output
AI agentic workflows, predominantly featuring agent-to-agent interactions as opposed to agent-human interactions, might initially seem to prioritize Tokens per Second as the key performance metric. However, upon closer inspection, the complexity of these workflows becomes apparent. In such systems, each model call typically involves a long input for a relatively short output, as the model continually updates the context to predict the next state. Consequently, Time to First Token remains crucial for effective system performance, not only in these workflows but also in applications like RAG that process multiple or lengthy documents. Additionally, the current model trend in supporting super long context windows further strengthened this situation and needless to mention those mutl-turn conversational chatbot systems.
A More Balanced Approach
Successful system development is more nuanced than maximizing a single metric. At SambaNova, we strive for a more balanced design that integrates diverse measurements to capture the full spectrum of system capabilities. As a result, SambaNova’s RDU (Reconfigurable Dataflow Unit) system has an unique 3-tier memory hierarchy as the following:
- Large SRAM: enables an reconfigurable dataflow micro-architecture that achieves 430 Tokens per Second throughput for llama3-8b on a 8-chips (sockets) system via aggressive kernel fusion
- HBM: enables efficient graph caching & weight loading operations that lead to 0.2 seconds for Time to First Token on input size up to 4096 tokens. While other SOTA systems could take over 1.6 seconds on similar workloads
- DRAM: enables large system capacity to accommodate larger model size, longer sentence length and routing techniques such as Composition of Experts (CoE), significantly enhancing end-to-end statistical performance
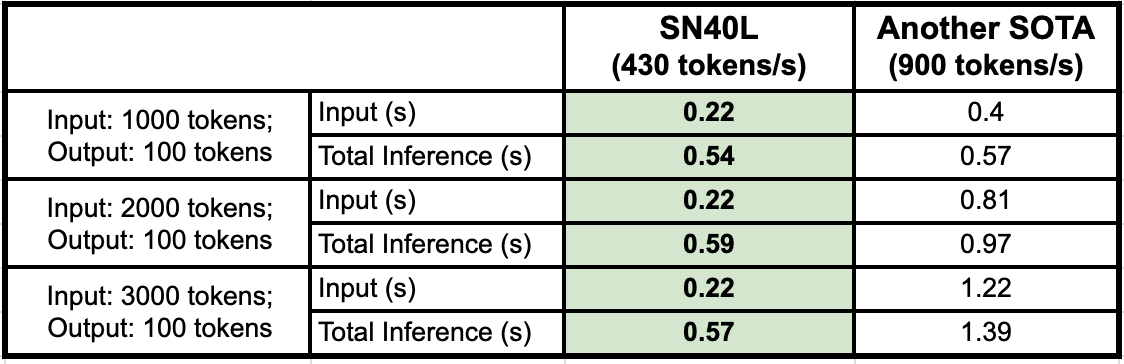
Table - Input process time and total inference time on llama3-8B (green is better)

Figure - Total Inference time vs. input tokens (llama 3 8B)
Leveraging these hardware advantages and innovative software techniques, such as tensor parallelism and continuous batching, we are thrilled about the limitless possibilities ahead for LLM systems. More information is available at https://sambanova.ai/resources/tag/blog.
Conclusion
In conclusion, the exploration of Tokens per Second reveals its limitations as a sole metric for evaluating LLM systems. This evidence strongly supports the argument for a more comprehensive metric selection in system design. A balanced approach that includes both throughput metrics like Tokens per Second and latency metrics such as Time to First Token ensures a more accurate assessment and optimization of system performance, particularly in user-centric applications.