We've been working on readers / writers for our recently announced Lance v2 file format and are posting in-depth articles about writing a high performance file reader. In the first article I talked about how we obtain parallelism without row groups. Today, I want to explain how, and why, we separate scheduling from decoding.
What are Scheduling & Decoding?
Scheduling is the act of figuring out what I/O requests need to be performed to read the requested ranges (potentially with a filter). Decoding is the act of taking the loaded I/O and converting it into the desired encoding. Both tasks are synchronous CPU tasks however there is I/O that happens in between them. For example, if we were asked to load a range of rows from a flat encoded array we might have something that looks like this:
async def load_float_range(f: BinaryIO, row_start: int, row_end: int):
# Scheduling
bytes_start = row_start * 4
num_bytes = (row_end - row_start) * 4
# I/O (we are pretending we have asynchronous python I/O here)
await f.seek(bytes_start)
bytes = await f.read(num_bytes);
# Decoding
return [ \
struct.unpack('f', bytes[i:i+4]) \
for i in range(0, len(bytes), 4) \
]
}Scheduling for a flat encoding is very simple. We multiply the row range by the # of bytes per value to get the byte range. Decoding is also pretty simple. We need to reinterpret the bytes as the desired data type. Both steps can get much more complicated.
Separating the Steps
When we talk about separating these two steps we mean that we are putting each responsibility into its own interface (trait, abstract base class, etc.) In other words, instead of a single interface like this:
class Decoder(ABC):
def decode(f: BinaryIO, row_start: int, row_end: int) -> pa.Array:
passWe have two interfaces:
class Scheduler(ABC):
def schedule(row_start: int, row_end: int, io_reqs, decoders) -> None:
pass
class Decoder(ABC):
def decode(data: bytes) -> pa.Array:
passio_reqs and decoders aren't defined. These are channels for threaded communication. More details below. Also, these interfaces are a bit simpler than what we actually have in practice (e.g. we've omitted filters).Why Separate?
Now that we understand what this separation is, the next obvious question is why we would want to do this. There are a few different reasons:
Performance
In theory, it is possible to achieve good performance without splitting these two steps, but in practice I believe this to be incredibly hard to achieve. For example, consider the variable length list encoding. This typically leads to a situation (described further below) called "indirect I/O" where some scheduling has to happen after some decoding. In most readers I've seen, this is tackled by pausing the scheduling process and this leads to gaps where I/O could be performed but isn't (something that should be avoided at all costs in a reader). In fact, this is generally inevitable in combined readers, though it is rather tricky to explain and involves the way we apply back pressure (read ahead limits must be tied to decoding and I/O but shouldn't be tied to scheduling).
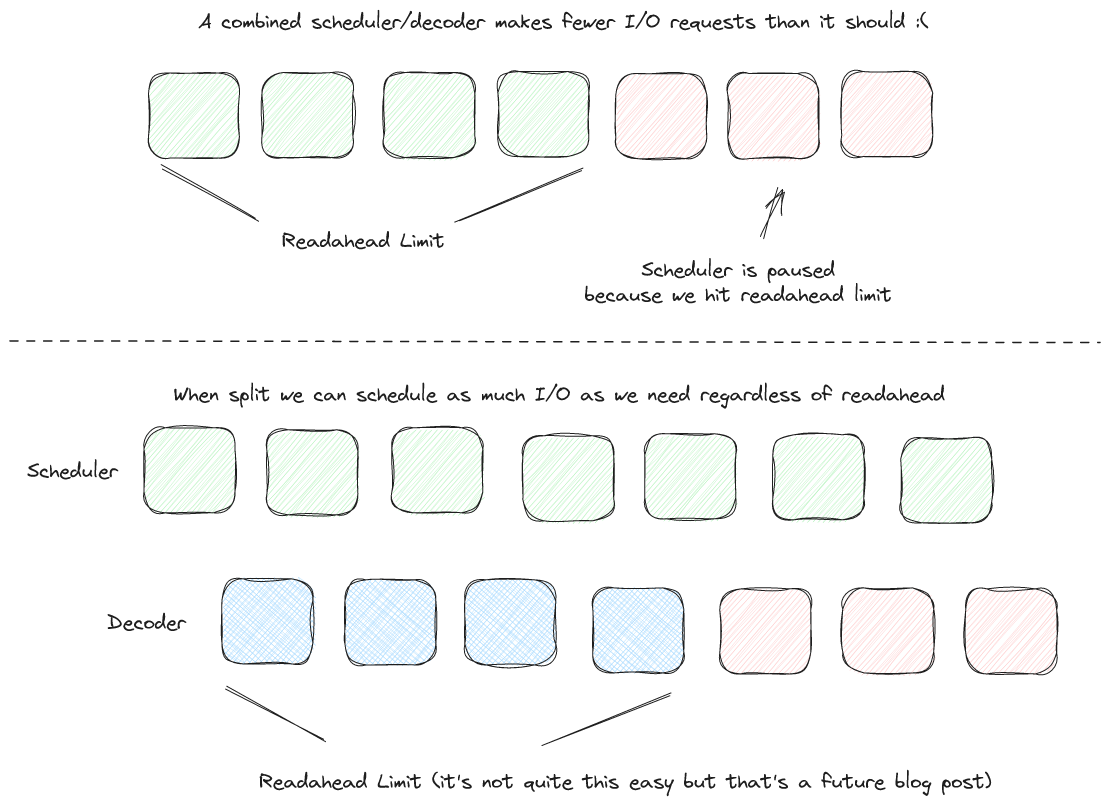
A second factor in performance, which will be discussed in much more depth in a future post, is thread locality. By moving the decoding steps we make it possible to do decode-based parallelism. If we combine decode-based parallelism with our query engine we can "fuse" the decode with our query pipeline. This prevents a copy of our data to/from main memory by preserving CPU cache locality.
Extensibility and Decoupling
This next argument is about design. Breaking up a complex task into two composable tasks generally reduces the complexity (provided each task stands on its own). A good example of this is the list decoder which has very complex scheduling logic and non-trivial decoding logic as well.
We've also found that it makes categorization of encodings more sophisticated. For example, pushdown statistics are typically viewed by a file reader as a specialized structure. Under the lens of scheduling and decoding we can view pushdown statistics as just another encoding, one that is purely a scheduler and has no decoding component.
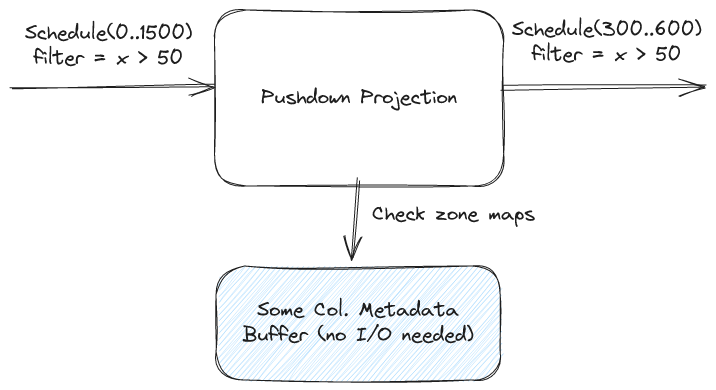
Schedule-Only Tasks (e.g. cost / cardinality estimation)
Finally, by breaking scheduling out into its own phase, we can choose to run just the scheduling phase. This is important for tasks like cost estimation. By running the scheduling phase by itself and accumulating the I/O requests we can quickly and cheaply determine how much I/O a given request might take. Note: we can also calculate other statistics such as expected cardinality (e.g. using a histogram) even if they don't affect the I/O.
Implementation
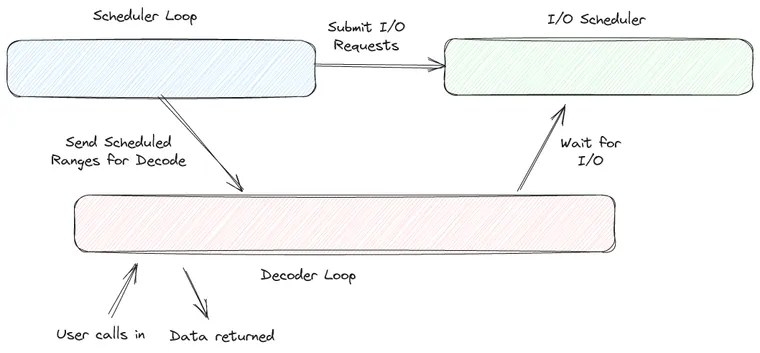
Hopefully we've convinced you that separating these two concepts is important. Implementation of such a reader is tricky but not impossible. To do this in Lance we separate the work into three different loops, the scheduler loop, the decoding loop, and the I/O loop. These pieces run in parallel and communicate with each other as the file is read.
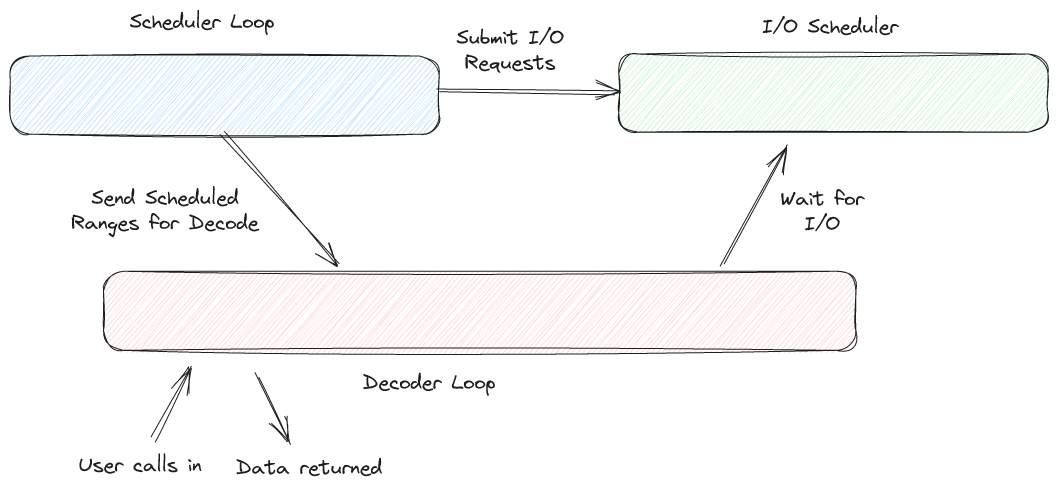
The scheduler loop walks through the file metadata and, for each page included in the requested range, issues I/O requests and then describes the range that was scheduled to the decoder loop. The scheduler loop is run today on a single thread task launched for the purpose. The scheduler loop is a synchronous task, quite short (well under 10% of the total runtime in large files, even with fast I/O) and never blocks.
The I/O scheduler receives I/O requests from the scheduler and throttles them to achieve a configurable I/O depth. The I/O scheduler is a single thread task that blocks frequently, whenever the I/O depth has been reached, or when it is waiting for input from the scheduler.
The decoder loop first waits for scheduled ranges, and then waits for enough I/O to complete in order to decode a batch. There is no dedicated task for the decoder loop. Instead, it is run by caller threads. Each call to decode another batch becomes a thread task of sorts. That will be described in a dedicated blog post soon.
On No! Indirect I/O!
I mentioned earlier that scheduling lists was quite complicated, since some of the scheduling work needs to be done after decoding. This is a problem for our design since our scheduler loop never blocks. To give an example, consider we are asked to read row 17 from an array of type list<int32>. First, we must read how long list 17 is. We schedule an I/O request for the byte range containing the list length. Then (assuming list 17 isn't empty) we must read the actual list data. We don't know the byte range containing the actual data (it depends on the length).
We call this problem "indirect I/O" and our solution is to launch a temporary, nested, scheduler loop. This scheduler loop is launched immediately and waits for the offsets. Once the offsets arrive it decodes the offsets and runs scheduling for the list data. This needs to be a "full scheduler loop" because we can have quite a complicated situation like list<struct<list<struct<...>>>. In fact, each layer of list adds another layer of indirect I/O and another scheduler loop.
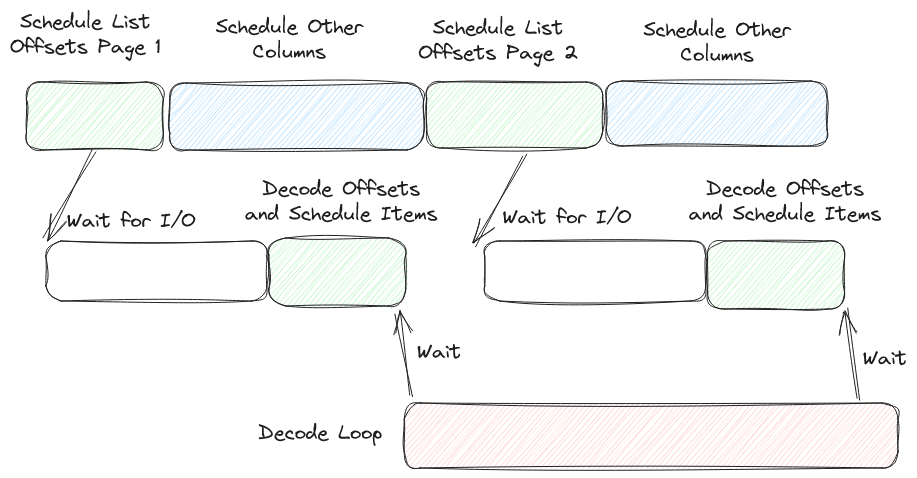
This isn't great for performance but it is inevitable with the typical encoding used for variable length lists. Most existing readers that I've seen either don't address this (because they don't support reading ranges and thus force a complete page load of the list and all its list items) or do this by blocking the scheduler (note that an async / await is still "blocking the scheduler" if you have a batch read ahead limit).
There are also ways to avoid this indirect I/O. The most common is when you are doing full scans and you are asking for a complete page of list offsets. In this case the indirect I/O can be skipped (we know we need all of the list items referenced by the page). Another potential shortcut we would like to investigate is to use "skip tables" for list lengths. These tables would be optional column metadata which, if present, can be used to quickly determine a rough set of item ranges needed, without doing any I/O. However, it is important for us that our reader be able to handle the indirect case well. Also note that future encodings such as run-end encoding may also need indirect I/O.
I/O Priority
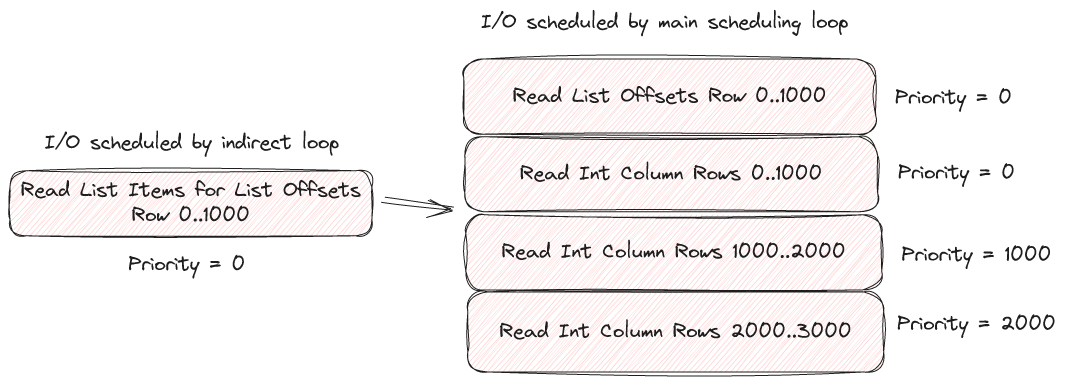
Since we do not block the scheduler while waiting for list offset data it means that the scheduler continues and submits more I/O requests for later and later portions of data. This causes an I/O priority problem. Once we have the list offsets loaded we will want to run the indirect scheduler loop. It will also submit I/O requests. We don't want to place these requests at the end of the queue.
To solve this our I/O loop actually has a priority queue that is used once we've hit the max I/O depth. The logic for this queue is fairly simple. Every I/O request is associated with some top-level row number. The lower the row number the higher the priority of the I/O.
Results
The end result of all of this is that we can read files quickly and with very consistent I/O scheduling. For an example we have done some profiling of a full read of one file of the NYC taxi data. In parquet this file is about ~420MB. In Lance this file occupies ~2.3GB because we don't yet have any compressive encodings. Even though the data is 5 times larger, we've found that Lance only lags behind pyarrow's parquet reader by about 2x (and uses about 75% as many CPU operations because it isn't dealing with compression) because Lance manages to achieve much better parallelism. The gap is quickly closing 🏎️.
To show the effects of indirect I/O and priority we profiled a version of Lance that doesn't use the "avoid indirect I/O on full page load" shortcut. We also have traces both with and without prioritized I/O.
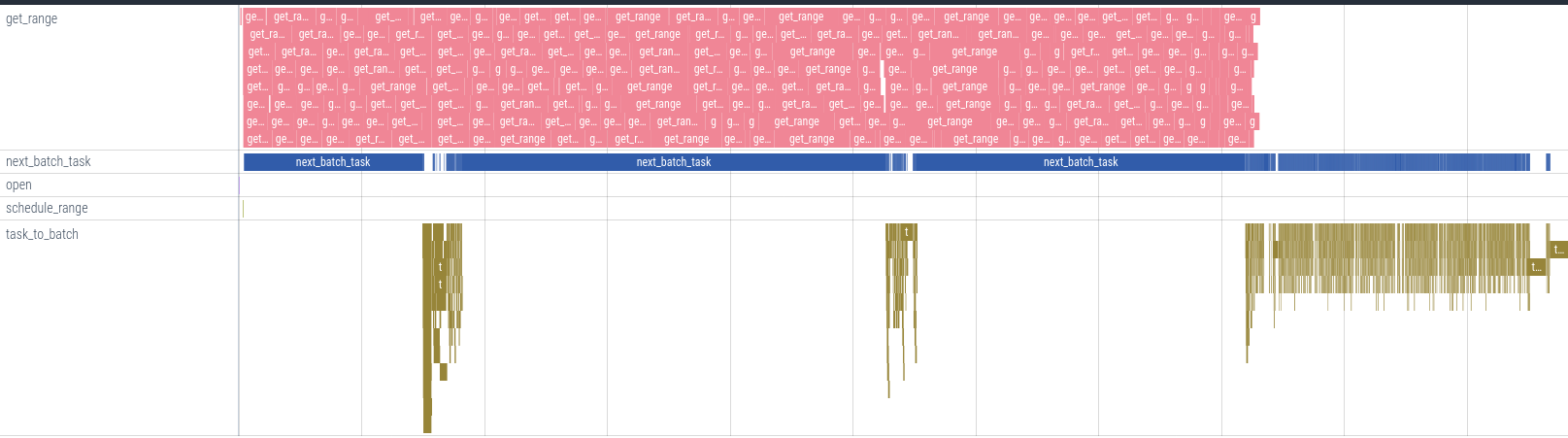
In both traces the pink tasks represent our I/O and there are very few gaps in the I/O. The brown represents the decode tasks. Without prioritized I/O the I/O and decode don't overlap much because the decode is waiting on I/O that gets put at the end of the queue.
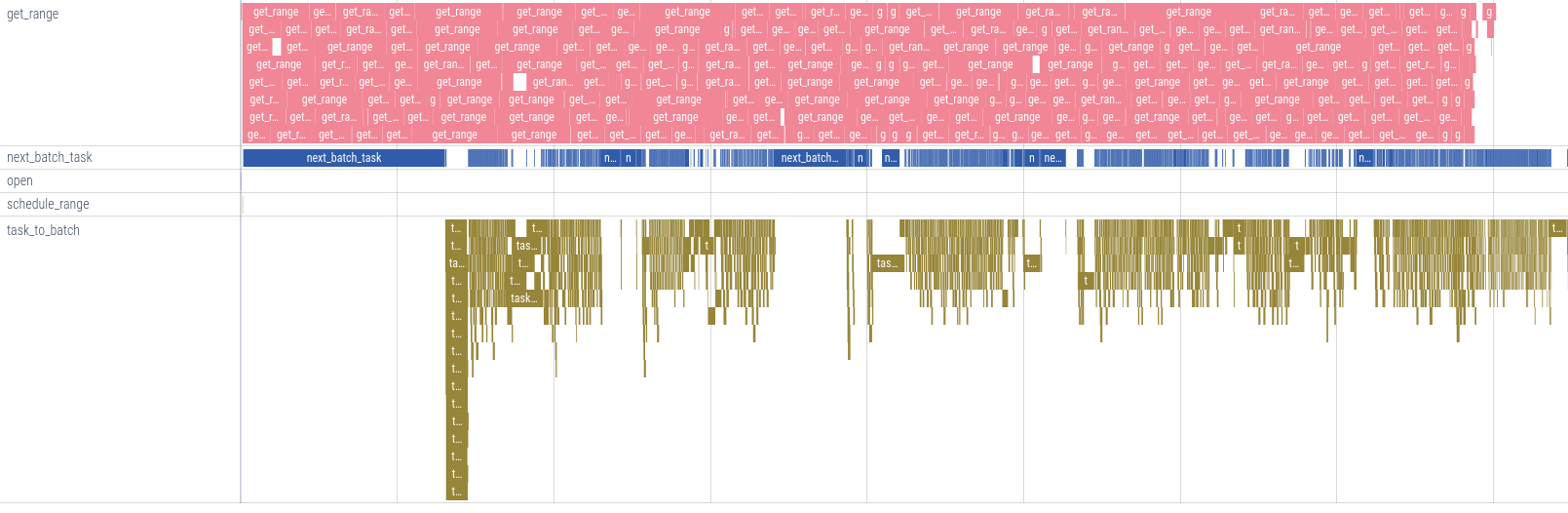
With prioritized I/O we can clearly see the delay is much smaller and the decode is able to run in parallel with the I/O. At the same time we are still able to feed the I/O scheduler.
Finally, note that metadata loading and scheduling are very fast. This is partly because we are doing a full scan (instead of a point lookup) but I was still not expecting it to be this fast. We have to really zoom in to see these tasks:
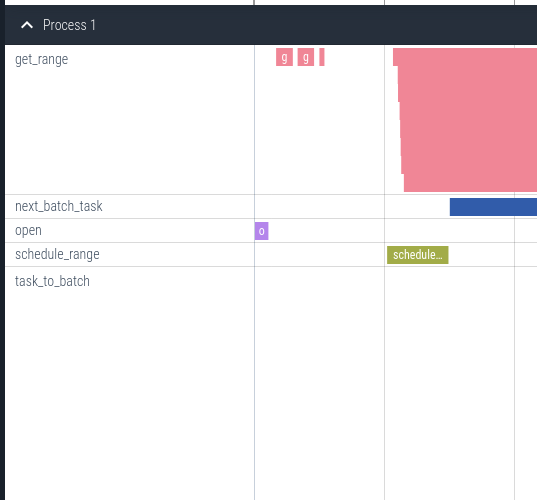
In both cold (no data in page cache) and warm reads the metadata loading, metadata decoding, and scheduling take less than 0.5% of the total read time. This is primarily because lance has very large pages and fairly sparse metadata. However, this can still be a significant amount of time for point lookups as we will see in future blog posts.