
.... and some advanced filtering and re-ranking technique
We all know what's Vanilla RAG, how it works, and how to use it but sometimes there are use cases that go beyond the traditional rules. For example, there are some use cases where we need to create very small chunks as larger ones can add noise like conversation history. Using a sentence or couple-level strategy is pretty decent in this case but don't you think the context to the current reply might be hidden somewhere in the previous one or the answer to something can be somewhere in the future ones? This is just one use case and I know you might be thinking why not use a bigger chunk if you're going in that direction? A few reasons such as no. of chunks to send are limited and bigger chunk sizes can add more noise. So? What's the solution?
A man is known by the company he keeps

Context Enrichment
It means that when you get the Top-K chunks and the size of the chunks is smaller, you can enrich this context by adding the neighboring chunks too. So when along with the Top-K most useful chunks come their Previous and Future N neighboring chunks. Simply put, make a sandwich of each context you get from the query.



Let's do some coding so that you understand completely. Let's start with simply installing and importing libraries, loading a PDF, and creating a LanceDB table.
! pip install -U openai lancedb einops sentence-transformers transformers datasets tantivy rerankers langchain PyMuPDF -qq
# Get a PDF for example
!mkdir ./data
!wget https://ncert.nic.in/ncerts/l/jess301.pdf -O ./data/history_chapter.pdf
# Import Libraries
import os, re, random, json
import pandas as pd
import torch
import lancedb
from lancedb.embeddings import get_registry
from lancedb.pydantic import LanceModel, Vector
from tqdm.auto import tqdm
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document
import fitz
from typing import List
pd.set_option('max_colwidth', 750) # For visibility
model = get_registry().get("sentence-transformers").create(name="BAAI/bge-small-en-v1.5", device=("cuda" if torch.cuda.is_available() else "cpu")) # For embedding
def read_pdf_to_string(path):
"""
Read a PDF document from the specified path and return its content as a string.
Args:
path (str): The file path to the PDF document.
Returns:
str: The concatenated text content of all pages in the PDF document.
The function uses the 'fitz' library (PyMuPDF) to open the PDF document, iterate over each page,
extract the text content from each page, and append it to a single string.
"""
doc = fitz.open(path) # Open the PDF document located at the specified path
content = ""
for page_num in range(len(doc)): # Iterate over each page in the document
page = doc[page_num] # Get the current page
content += page.get_text() # Extract the text content from the current page and append it to the content string
return content
def split_text_to_chunks_with_indices(text: str, chunk_size: int, chunk_overlap: int) -> List[Document]:
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunk = text[start:end]
chunks.append(Document(page_content=chunk, metadata={"index": len(chunks), "text": text}))
start += chunk_size - chunk_overlap
return chunks
content = read_pdf_to_string("/content/data/history_chapter.pdf")
CHUNK_SIZE = 512
CHUNK_OVERLAP = 128
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([content])
# Create the table
class Schema(LanceModel):
text: str = model.SourceField() # the Columns (field) in DB whose Embedding we'll create
chunk_index: int
vector: Vector(model.ndims()) = model.VectorField() # Default field
chunks = []
for index, doc in enumerate(texts):
chunks.append({"text":doc.page_content, "chunk_index": index+1})
MAX_CHUNK_INDEX = index+1 # we'll need this for our logic to get the final chunk index that exists in DB
db = lancedb.connect("./db")
table = db.create_table("documents", schema=Schema)
table.add(chunks) # ingest docs with auto-vectorization
table.create_fts_index("text") # Create a fts index before so that we can use BM-25 later if we want to use Hybrid search
So we have created our table where each text chunk has an index associated with it. Let's now do a simple search.
TOP_K = 3 # How many similar chunks to retrieve
NEIGHBOUR_WINDOW = 1 # 1 means 1 before and 1 after
QUERY = "What did the the revolution proclaim and what did the centralised administrative system do?"
initial_results = table.search(QUERY).limit(TOP_K) # Get all the similar chunks which are sorted by distance by default
initial_results.to_pandas().drop("vector", axis = 1)
So the most important chunks according to Query are 14,86,16 . Now when we enrich the context with NEIGHBOUR_WINDOW = 1 , it simply means to get the chunk's IDs 13,14,15 , 85,86,87 and 15,16,17 , in order.
Did you notice something here? Yes, the chunk ID 15 is repeating with 2 groups. Where would you put it? It makes sense to put it with the higher priority AKA the minimum distance group (which in our case is 14). So we'll write the code the code to get the neighbors.
similar_chunk_indices = {} # store previous and next neighbour chunk
for i in initial_results.to_list(): # Get all the similar chunks and their neighbour indices
index = i["chunk_index"]
similar_chunk_indices[index] = i["_distance"]
for near in range(1, NEIGHBOUR_WINDOW+1):
if (max(0,index-near)) not in similar_chunk_indices: # Previous neighbour
similar_chunk_indices[(max(0,index-near))] = i["_distance"] # This chunk will also have the same distance
if min(index + near, MAX_CHUNK_INDEX) not in similar_chunk_indices: # Next neighbour
similar_chunk_indices[min(index + near, MAX_CHUNK_INDEX)] = i["_distance"]
similar_chunk_indices # Look at the index 15. It is a part of 14 and 16 bothIt gives you a dictionary of chunk IDs to fetch and their distance. We assign the same distance to the neighbor as the parent chunk.
Now there is an interesting phenomenon or you can say an edge case. What if you have overlapping or continuous indices such that [3,4,5] has a distance of 0.7, [20,21,22] with distance 0.4, [6,7,8] with a distance of 0.1 and [1,2,3] comes with a distance of 0.9?
If you look at the indices, you see there is a continuous range from 1 to 8 but with different distance and ranges. In that case, wouldn't it be logical to use the continuous group together at the same position from 1 to 8 and assign it a minimum distance as 0.1 so that it comes before the group [20,21,22]?
It makes sense because if we are going to include the chunk group later anyhow, why not to use the continuity to our advantage and save ourselves from a broken context.
def group_and_rerank_chunks(indices_dict:dict):
"""
function to take the {"chunk_index":"distance"} dict and return {"priority": indices_group_list} dict
"""
sorted_indices = sorted(indices_dict.keys()) # Sort the indices
# Group by distance with continuity consideration
groups = []
current_group = []
current_min_distance = float('inf')
for i in range(len(sorted_indices)):
index = sorted_indices[i]
distance = indices_dict[index]
if not current_group: # Start a new group
current_group.append(index)
current_min_distance = distance
else:
if index == current_group[-1] + 1: # Check continuity
current_group.append(index)
current_min_distance = min(current_min_distance, distance)
else: # Save the current group and start a new one
groups.append((current_min_distance, current_group))
current_group = [index]
current_min_distance = distance
if current_group: # add the last group
groups.append((current_min_distance, current_group))
groups.sort(key=lambda x: x[0]) # Sort groups by minimum distance
return {i: group for i, (dist, group) in enumerate(groups)}
# group_and_rerank_chunks({
# 50:75, 51:75, 52:75, 53:75, 54:75, 55:75,
# 997:1, 998:1, 999:1,
# 5:50, 6:50, 7:50,
# 1:100, 2:100, 3:100,
# 8:100, 9:1000, 10:1000}) # Test this one to understand
reranked_indices = group_and_rerank_chunks(similar_chunk_indices)
reranked_indices # Look at the group for 16. Even though it has more disatnce than 86 but since it's part of a continuous group, we put it beforeIt gives us the two groups results as: {0: [13, 14, 15, 16, 17], 1: [85, 86, 87]} and these groups are sorted by how would they occur in the final RAG.
Now off to some efficient retrieval using LanceDB functionality
Do we need to search the query again? No. Definitely not. Because LanceDB gives functionality to search the SQL-like queries directly. If we know the chunk_index already, we can directly write a query to fetch those rows and post-process them. Isn't that beautiful (and efficient)!
indices_to_search = []
for priority, indices in reranked_indices.items():
indices_to_search.extend(indices)
similar_results = table.search().\
where(f"chunk_index IN {tuple(indices_to_search)}").\
limit(len(similar_chunk_indices)).\
to_pandas().\
set_index("chunk_index").loc[indices_to_search, :].reset_index() # Just a trick to sort the DF according to the chunk priority group
similar_results.drop("vector", axis = 1)
And now we are left with just 1 post-processing step. Which is? Yes, repeated sentences like you teacher. Don't remember? Didn't you put that CHUNK_OVERLAP = 128 ? So it means that we have to remove those. We simply go group by group and remove the overlapping prefix from the second entry onwards.
final_rag_text = "## Context - 1:\n"
group_priority = 0 # Priority of the Chunk group
grouped_indices = reranked_indices[group_priority]
remove_overlap = False # from the 2nd element in the group, remove prefix overlap
for _, row in similar_results.iterrows():
chunk_index = row["chunk_index"]
if remove_overlap: # if the previous chunk is there, remove the overlap
final_rag_text += row["text"][CHUNK_OVERLAP:]
else:
final_rag_text += row["text"]
remove_overlap = True
if chunk_index == grouped_indices[-1]: # last element of the group means the new group has started
group_priority += 1
remove_overlap = False # new group has started so don't trim the first element
if group_priority in reranked_indices: # If not the last key in the dict
final_rag_text += f"\n\n## Context - {group_priority+1}:\n"
grouped_indices = reranked_indices[group_priority]
print(final_rag_text)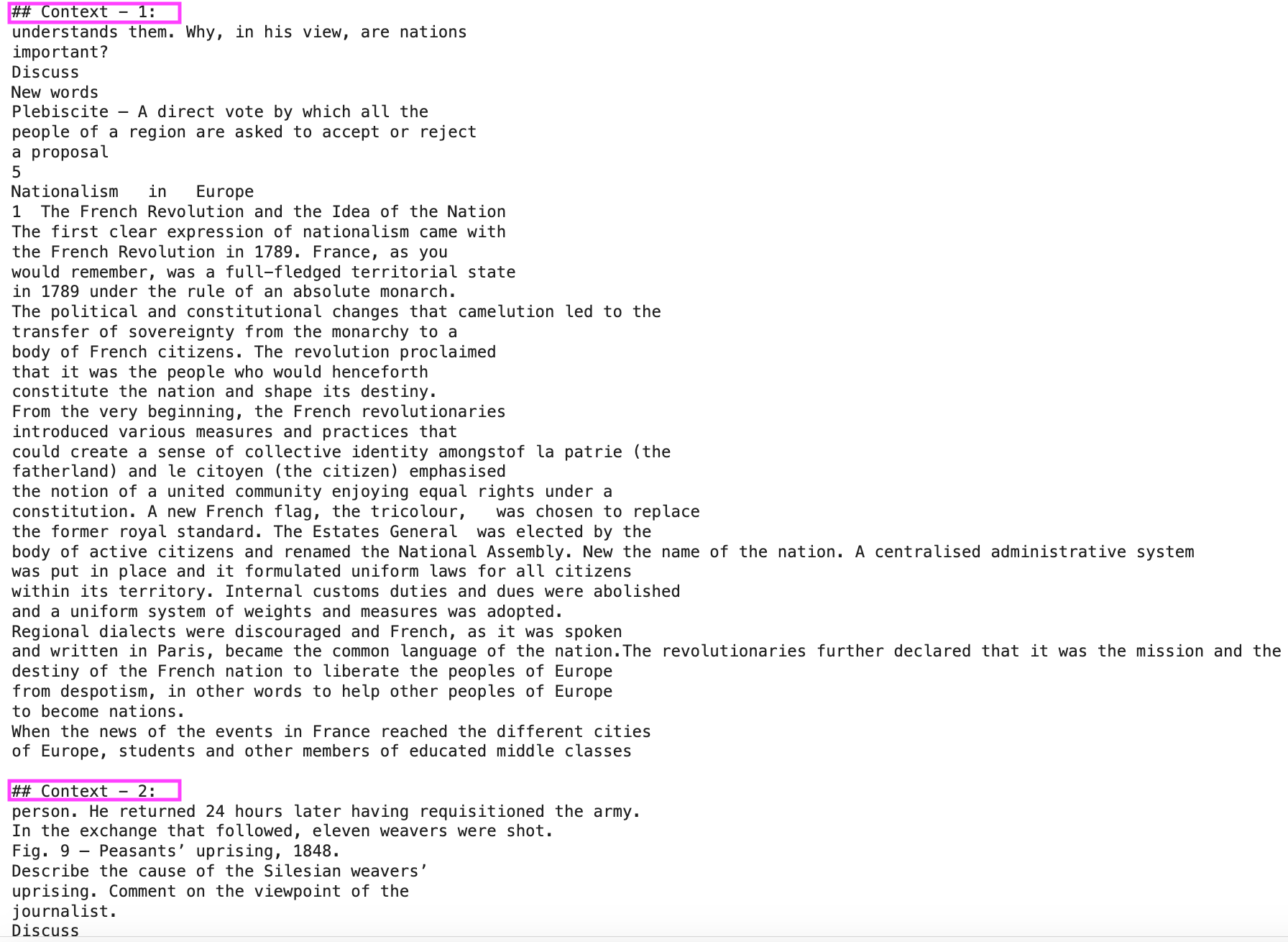
Both the groups are shown here, in order, with overlapping removed.
If you are interested, you can also check advanced chunking and retrieval techniques like Parent Document Retriever, HyDE, Re-Ranking etc