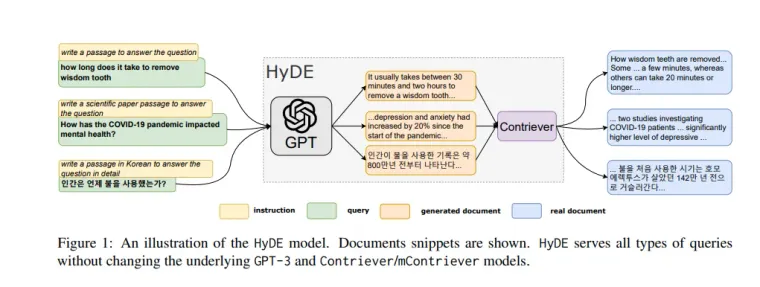
In the world of search engines, the quest to find the most relevant information is a constant challenge. Researchers are always on the lookout for innovative ways to improve the effectiveness of search results. One such innovation is HyDE, which stands for Hypothetical Document Embeddings, a novel approach to dense retrieval that promises to make searching for information even more efficient and accurate.
The Challenge of Dense Retrieval
Dense retrieval, a method used by search engines to find relevant documents by comparing their semantic similarities, has shown great promise across various tasks and languages. However, building fully zero-shot dense retrieval systems without any relevant labels has been a significant challenge. Traditional methods rely on supervised learning, which requires a large dataset of labeled examples to train the model effectively.
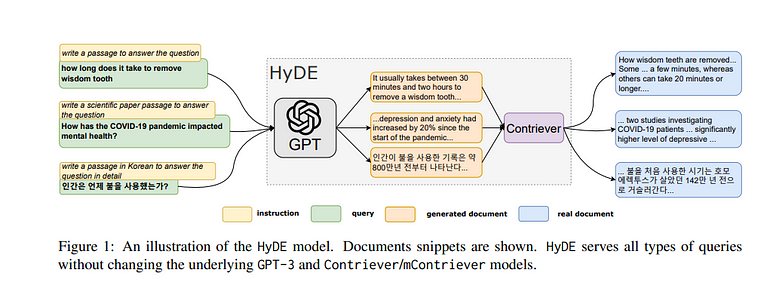
Introducing HyDE
The HyDE approach recognizes the difficulty of zero-shot learning and encoding relevance without labeled data. Instead, it leverages the power of language models and hypothetical documents. Here’s how it works:
- Generating Hypothetical Documents: When a user enters a query, HyDE instructs a language model, like GPT-3, to generate a hypothetical document. This document is designed to capture relevance patterns but may contain inaccuracies.
- Unsupervised Encoding: The generated hypothetical document is then encoded into an embedding vector using an unsupervised contrastive encoder. This vector identifies a neighbourhood in the corpus embedding space, where similar real documents are retrieved based on vector similarity.
- Retrieval Process: HyDE searches for real documents in the corpus that are most similar to the encoded hypothetical document. The retrieved documents are then presented as search results.
The Benefits of HyDE
What makes HyDE intriguing is its ability to perform effectively without the need for relevant labels. It offloads the task of modeling relevance from traditional retrieval models to a language model that can generalize to a wide range of queries and tasks. This approach has several advantages:
- Zero-Shot Retrieval: HyDE can work “out of the box” without relying on a large dataset of labeled examples.
- Cross-Lingual: It performs well across various languages, making it suitable for multilingual search applications.
- Flexibility: HyDE’s approach allows it to adapt to different tasks without extensive fine-tuning.
Implementing HyDE in Langchain
To utilize HyDE effectively, one needs to provide a base embedding model and an LLMChain for generating documents. The HyDE class comes with default prompts, but there’s also the flexibility to create custom prompts.
Follow along with the Google Colab


from langchain.llms import OpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.chains import LLMChain, HypotheticalDocumentEmbedder
from langchain.prompts import PromptTemplateInitialize the LLM & embedding model
# instantiate llm
llm = OpenAI()
emebeddings = OpenAIEmbeddings()embeddings = HypotheticalDocumentEmbedder.from_llm(llm, emebeddings, "web_search")
# Now we can use it as any embedding class!
result = embeddings.embed_query("What bhagavad gita tell us?")We can also generate multiple documents and then combine the embeddings for those. By default, we combine those by taking the average. We can do this by changing the LLM we use to generate documents to return multiple things.
multi_llm = OpenAI(n=3, best_of=3)embeddings = HypotheticalDocumentEmbedder.from_llm(
multi_llm, embeddings, "web_search"
)result = embeddings.embed_query("What bhagavad gita tell us?")The HypotheticalDocumentEmbedder does not actually create full hypothetical documents. It only generates an embedding vector representing a hypothetical document. This HypotheticalDocumentEmbedder is used to generate "dummy" embeddings that can be inserted into a vector store index.
This allows you to reserve space for documents that don’t exist yet so that you can incrementally add new real documents later.
Use your own prompts
You can also make and use your own prompts when creating documents with LLMChain. This is helpful if you know what topic you’re asking about. With a custom prompt, you can get a text that fits your topic better.
Let’s try this out. We’ll make a prompt which we’ll use in the next example.
prompt_template = """
As a knowledgeable and helpful research assistant, your task is to provide informative answers based on the given context. Use your extensive knowledge base to offer clear, concise, and accurate responses to the user's inquiries.
Question: {question}
Answer:
"""prompt = PromptTemplate(input_variables=["question"], template=prompt_template)llm_chain = LLMChain(llm=llm, prompt=prompt)embeddings = HypotheticalDocumentEmbedder(
llm_chain=llm_chain,
base_embeddings=embeddings
)loading the pdf we are using
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader
#Load the multiple pdfs
pdf_folder_path = '/content/book'
from langchain.document_loaders import PyPDFDirectoryLoader
loader = PyPDFDirectoryLoader(pdf_folder_path)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
)
documents = text_splitter.split_documents(docs)let’s create a vector store for retrieving information
from langchain.vectorstores import LanceDB
import lancedb# lancedb as vectorstore
db = lancedb.connect('/tmp/lancedb')
table = db.create_table("documentsai", data=[
{"vector": embeddings.embed_query("Hello World"), "text": "Hello World", "id": "1"}
], mode="overwrite")
vector_store = LanceDB.from_documents(documents, embeddings, connection=table)the result of vector_store getting some relevant information from the doc
[Document(page_content='gaged in work, such a Karma -yogi is not bound by Karma. (4.22) \nThe one who is free f rom attachment, whose mind is fixed in Self -\nknowledge, who does work as a service (Sev a) to the Lord, all K ar-\nmic bonds of such a philanthropic person ( Karma -yogi) dissolve \naway. (4.23) God shall be realized by the one who considers eve-\nrything as a manifest ation or an act of God. (Also see 9.16) (4.24) \nDifferent types of spiritual practices', metadata={'vector': array([-0.00890432, -0.01419295, 0.00024622, ..., -0.0255662 ,
0.01837529, -0.0352935 ], dtype=float32), 'id': '849b3475-6bf5-4a6a-955c-aa9c1426cdbb', '_distance': 0.2407873421907425}),
Document(page_content='renunciation (Samny asa) is also known as Karma -yoga . No one \nbecomes a Karma -yogi who has not renounced the selfish motive \nbehind an action. (6.02) \nA definition of yoga and yogi \nFor the wise who seeks to attain yoga of meditation or calm-\nness of mind, Karma -yoga is said to be the means. For the one \nwho has attained yoga, the calmness becomes the means of Self -\nrealization. A person is said to have attained yogic perfection when', metadata={'vector': array([ 0.00463139, -0.02188308, 0.01836756, ..., 0.00026087,
0.01343005, -0.02467442], dtype=float32), 'id': 'f560dd78-48b8-419b-8576-978e6afee272', '_distance': 0.24962666630744934}),
Document(page_content='one should know the nature of attached or selfish action, the nature \nof detached or selfless action, and also the nature of forbidden ac-\ntion. (4.17) \nA Karma -yogi is not subject to the K armic laws \nThe one who sees inaction in action, and action in inaction, is \na wise person. Such a person is a yogi and has accomplished eve-\nrything. (4.18) \nTo see inaction in action and vice versa is to understand that \nthe Lord does all the work indirectly through His power by using us.', metadata={'vector': array([-0.01086397, -0.01465061, 0.00732531, ..., -0.00368611,
0.01414126, -0.0371828 ], dtype=float32), 'id': 'a2088f52-eb0e-43bc-a93d-1023541dff9d', '_distance': 0.26249048113822937}),
Document(page_content='the best of your ability, O Arjuna, with your mind attached to the \nLord, aba ndoning worry and attachment to the results, and remain-\ning calm in both success and failure. The calmness of mind is \ncalled Karma -yoga . (2.48) Work done with selfish motives is infe-\nrior by far to selfless service or Karma -yoga . Therefore, be a \nKarma -yogi, O Arjuna. Those who work only to enjoy the fruits of \ntheir labor are, in truth, unhappy. Because , one has no control over \nthe results. (2.49)', metadata={'vector': array([ 0.00598168, -0.01145132, 0.01744962, ..., -0.01556102,
0.00799331, -0.03753265], dtype=float32), 'id': 'b3e30fff-f3a5-4665-9569-b285f8cf9c76', '_distance': 0.2726559340953827})]below is a screenshot of a PDF file that has all the information related to a query.

passing the string query to get some reference
# passing in the string query to get some refrence
query = "which factors appear to be the major nutritional limitations of fast-food meals"
vector_store.similarity_search(query)
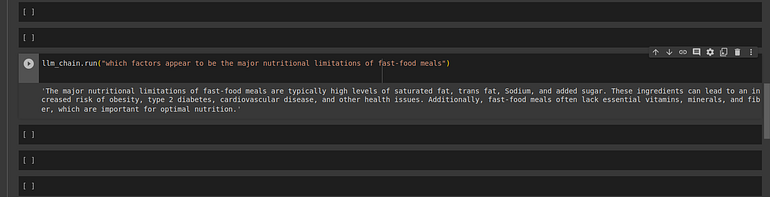
llm_chain.run("which factors appear to be the major nutritional limitations of fast-food meals")
The major nutritional limitations of fast-food meals
are typically high levels of saturated fat, trans fat, Sodium,
and added sugar. These ingredients can lead to an increased risk of obesity,
type 2 diabetes, cardiovascular disease, and other health issues.
Additionally, fast-food meals often lack essential vitamins, minerals,
and fiber, which are important for optimal nutrition.HyDE response: here we can see that we are getting the output. which is very good.

A vanilla RAG is not able to get the correct answer because it's directly searching similar keywords in the database.
Normal RAG System:
- In a typical RAG system, the retrieval phase involves searching for relevant information from a corpus using traditional keyword-based or semantic matching methods.
- The retrieved documents are then used to augment the generation process, providing context and information for generating responses or answers.
- The quality of the retrieved documents heavily depends on the effectiveness of the retrieval methods, which may not always capture highly relevant information.
Example Output:


you can check our blog for a vanilla RAG
Here is whole code to try
- HyDE uses Language Models (LLMs) to generate hypothetical documents, making information retrieval more precise.
- It doesn’t rely on extensive labeled data, making it a valuable tool when training data is limited.
- HyDE can assist in building the training data needed for specific retrieval tasks.
- It excels at retrieving relevant chunks of information in the RAG pipeline.
For even more exciting applications of vector databases and Large Language Models (LLMs), be sure to explore the LanceDB repository.
Explore more GenAI and LLM applications by visiting the vector-recipes. It’s filled with real-world examples, use cases, and recipes to inspire your next project. We hope you found this journey both informative and inspiring. Cheers!