
Lance is a columnar data format that is easy and fast to version, query and train on. It’s designed to be used with images, videos, 3D point clouds, audio, and, of course, tabular data.
Why Lance?
Lance file format fits perfectly in the deep learning ecosystem as a tool for storing, managing, versioning, and loading your data.
For starters, Lance's integration with PyTorch, Tensorflow and Huggingface 🤗 allows for seamless dataset curation (and loading) without switching frameworks and worrying about dtype conversions!
The key features of Lance include:
- High-performance random access: 100x faster than Parquet.
- Vector search: find nearest neighbours in under 1 millisecond and combine OLAP queries with vector search.
- Zero-copy, automatic versioning: manage versions of your data automatically, and reduce redundancy with zero-copy logic built-in.
- Ecosystem integrations: Apache-Arrow, DuckDB, and more are on the way.
Lance also supports any POSIX file system and cloud storage, like AWS S3 and Google Cloud Storage, allowing users to start their work post-haste instead of focusing on system compatibility.
Convenience
Lance tackles the challenge of managing unstructured data with intricate relationships.
Making sense of unstructured datasets
Lance leverages a columnar storage format, enabling easy and efficient querying, filtering, and updates to your datasets.
df = pd.DataFrame({"a": [10]})
tbl = pa.Table.from_pandas(df)
dataset = lance.write_dataset(tbl, "/tmp/test.lance", mode="append")
dataset.to_table().to_pandas()The same can be extended to multi-modal datasets, as Lance supports storing bytes or blobs.
Lance supports updating dataset. For example, consider a rick-and-morty dataset containing "id", "author", & "quote" columns. Now, you can easily update the dataset based on a condition. For example,
table.update(where="author='Rick'", values={"author": "Richard Daniel Sanchez"})
table.to_pandas()
Schema evolution
Lance allows to efficiently merge tables based on an overlapping column. For example, if you want to add a vector embedding column for each quote, you could do something like this:
embeddings = vec_to_table(vectors)
embeddings = embeddings.append_column("id", pa.array(np.arange(len(table))+1))
table.merge(embeddings, left_on="id")
table.head().to_pandas()
Deletion
What if the whole show was just Rick-isms? Let's delete any quote not said by Ric
table.delete("author != 'Richard Daniel Sanchez'")That's it!
Lance also provides utility features like switching versions, rollbacks, etc. You can read more about Lance on documentation site.
Zero-copy versioning
For brevity, let's say you decided to follow the Creating Instruction dataset for LLM fine-tuning example and created your own version of Alpaca dataset in Lance format. After some fine-tuning runs of your favourite LLM, you decided that your examples are too few and you decided to add a few more examples.
Assuming your new examples follow the same format as the rest of your dataset (in this case, the variable examples is a Pyarrow table consisting of 4 columns, with each column containing a list of tokens), the process of adding new samples to your dataset is as easy as executing the write dataset method with append mode!
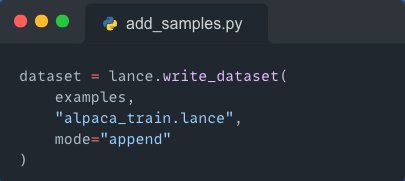
Well that was easy! You can also see all the versions of this dataset along with their timestamp!
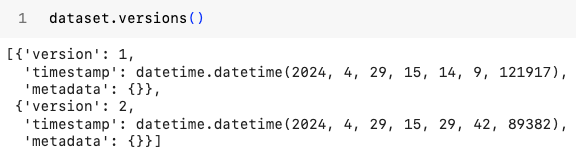
Lance versioning has zero-copy logic built-in. It's like giving a dataset the powers of Git!
Let's say you now did some more fine-tuning runs and your model performance started decreasing instead of increasing. After some deep debugging, you found out that the new examples you just added were of low quality.
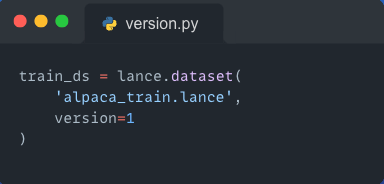
You now want to use the older version of the dataset for your fine-tuning run. With Lance, you can do this by just passing in the version argument to your lance.dataset() call.
Performance and Benchmarks
Thanks to lightning-fast random access, Lance enables fast dataloading for your deep learning runs so little time is spent on loading data, allowing for higher GPU utilisation.
Don't waste your precious $ on GPU credits performing expensive I/O such as loading images from the disc when you can just store them as a Lance dataset and load them with fast random access!
Alongside Lance integrations with widely-used deep learning frameworks, the Lance Deep learning recipes repository provides many tutorials on how to do popular deep learning tasks using a Lance dataset.
Benchmarks
Now, let's actually take a look at two benchmarks we ran to see how Lance fares against Vanilla PyTorch datasets.
We ran benchmarks on two I/O-intensive tasks: image classification and image segmentation, and found that not only does an equivalent lance dataset provide features such as versioning, it also provides a speed boost during training!
These benchmarks were run against community-made Lance versions of popular deep learning datasets.
Image Classification
This task is just as simple as it sounds: Basic image classification with 10 classes. We are using the CINIC-10 dataset in Lance format.
The vanilla PyTorch approach uses Torchvision's ImageFolder to load images and labels during training.
The Lance + PyTorch approach is to make a custom dataset to load the images (stored in Binary format) from the Lance dataset along with corresponding labels.
Thanks to fast random access that Lance provides, the latter is faster than PyTorch's Dataset!
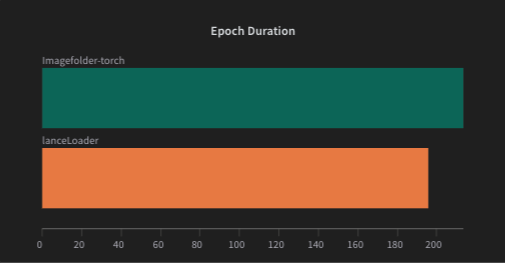
The above chart shows the average training time (in seconds) for Lance Dataset vs ImageFolder dataset on the CINIC-10 dataset.
Image Segmentation
For this task, we measured the time it took to load all batches using our COCOLance dataset vs Torchvision's COCODetection dataset. These numbers were averaged over 5 epochs.
For the COCOLance Dataset, we used the coco2017 Lance (train) dataset from the community.
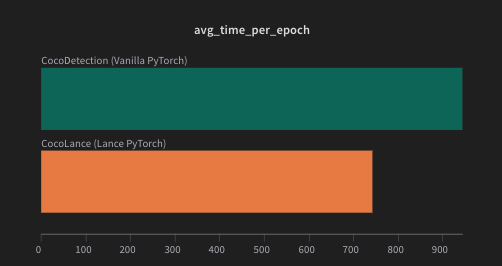
The time difference we observe in the above comparison (in seconds) is closer to 3 minutes per epoch. For 50 epochs, that's over 150 minutes (or 2.5 hours 🤯) saved just by loading data from a Lance dataset (stored on the disc just like other data) instead of loading data from a directory!
As you can see, not only does using a Lance dataset provide speed improvements over Vanilla PyTorch datasets, it also provides functionalities for efficient and fast data management, so you can scale your deep learning workflows as fast as you want without worrying about managing the dataset!
Final Remarks
Lance can be used to accelerate deep learning workflows for projects of any size with the same ease.
Along with our integrations, if you want to see examples both on how to create deep learning datasets and also on how to use them to train models for different tasks, check out the Lance Deep learning recipes repository.