Today, we will work on Multimodality, a concept that empowers AI models with the capacity to perceive, listen to, and comprehend data in diverse formats together with text—pretty much like how we do!
In an ideal situation, we should be able to mix different types of data and show them to a generative AI model simultaneously and iterate on it. It could be as simple as telling the AI model, "Hey, a few days ago, I sent you a picture of a brown, short dog. Can you find that picture for me?" the model should then give us the details. We want the AI to understand things more like we humans do, and we want it to become really good at handling and responding to all kinds of information.
But the challenge here is to make a computer understand one data format with its related reference, which could be a mix of text, audio, thermal imagery, and videos. Now, to make this happen, we use something called Embeddings. It's a numeric vector containing numbers written together that might not mean much to us but are understood by machines very well.
Cat is equal to Cat
Let's think of the text components for now. We are currently aiming for our model to learn that words like "Dog" and "Cat" are closely linked to the word "Pet." This understanding is easily achievable using an embedding model that converts these text words into their respective embeddings. Then, the model is trained to follow a straightforward logic: if words are related, they are close together in the vector space; if not, the adequate distance would separate them.

But we rely on Multimodal embedding to help a model recognize that an image of a "Cat" and the word "Cat" are similar. To simplify things a bit, imagine there is a magic box that is capable of handling various inputs – images, audio, text, and more.
Now, when we feed the box with an image of a "Cat" with the text "Cat," it performs its magic and produces two numeric vectors. When these two vectors were given to a machine, it made machines think, "Hmm, based on these numeric values, it seems like both are connected to "Cat." So that's exactly what we were aiming for! Our goal was to help machines recognize the close connection between an image of a "Cat" and the text "Cat."
However, to validate this concept, we plot those two numeric vectors in a vector space, which are very close. This outcome exactly mirrors what we observed earlier with the proximity of the two text words "Cat" and "Dog" in the vector space.
Ladies and gentlemen, that's the essence of Multimodality. 👏
So, we made our model comprehend the association between "Cat" images and the word "Cat." Well, this is it; if you can do this, you will have ingested the audio, images, videos, and the word "Cat," and the model will understand how the cat is being portrayed across all kinds of file formats.
RAG is here..
If you need to learn what RAG means, I recommend this article I recently wrote, which was popular and an excellent place to get started.
So, there are impressive models like DALLE-2 that provide text-to-image functionality. You input text, and the model generates relevant images for you. But can we create a system similar to Multimodal RAG, where the model produces output images based on our data? Alright, so the goal for today is to build an AI model that, when asked something like, "How many girls were there in my party?" 💀 not only provides textual information but also includes a relevant related image. Think of it as an extension of a simple RAG system, but now incorporating images.
Before we dive in, remember that Multimodality isn't limited to text-to-image or image-to-text; it encompasses the freedom to input and output any type of data. However, let's concentrate exclusively on the interaction from image to text.
Contrastive learning
Now, the question is, what exactly was that box doing? The magic it performs is known as Contrastive Learning. While the term might sound complex, it's not that tricky. To simplify, consider a dataset with images and a caption describing each image.
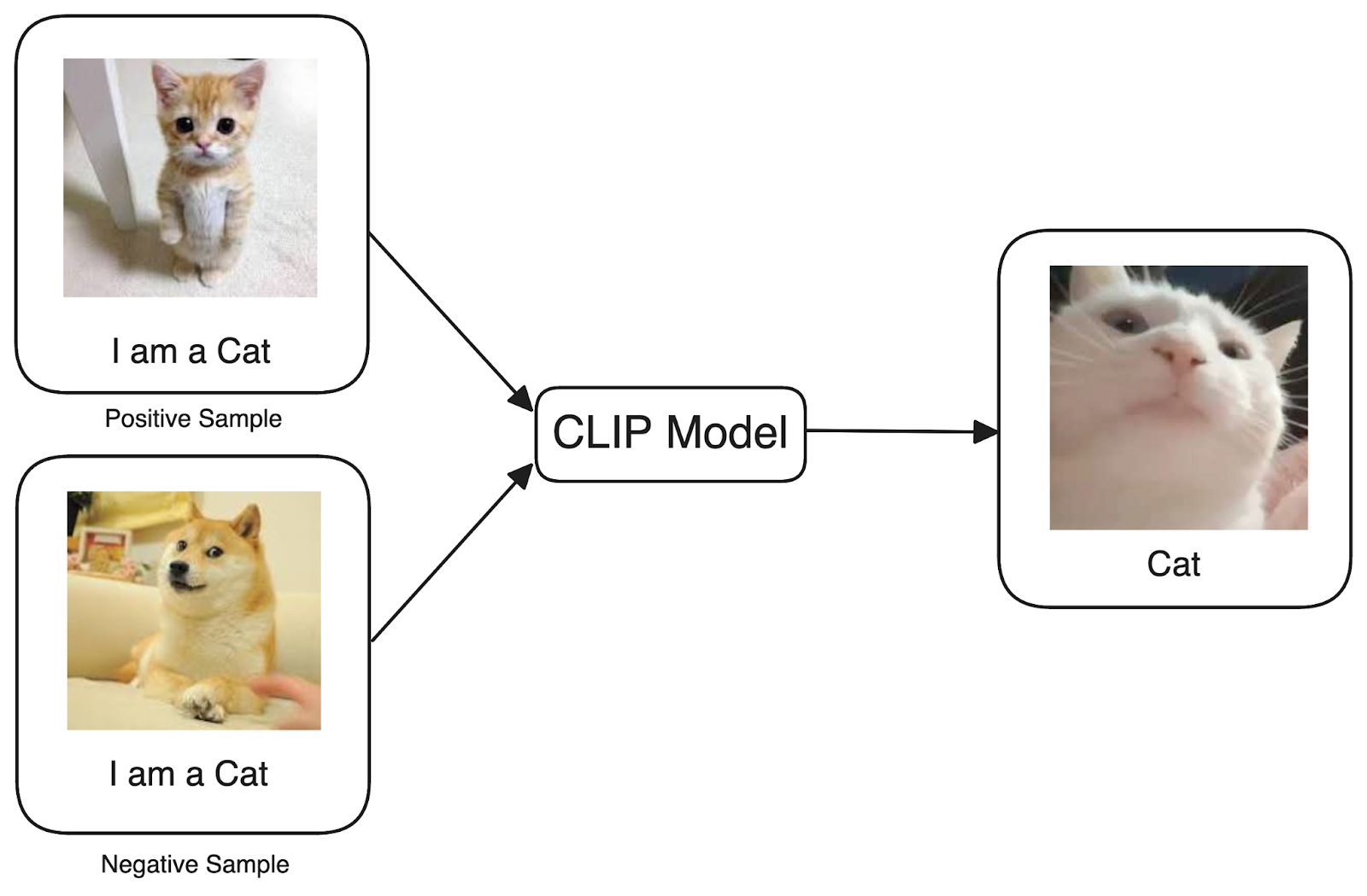
Now, we give our text-image model with these Positive and Negative samples, each consisting of an image and descriptive text. Positive samples are those where the image and text are correctly aligned—for instance, a picture of a cat matched with the text "this is an image of a cat." Conversely, negative samples involve a mismatch, like presenting an image of a dog alongside the text "This is an image of a cat."
Now, we train our text-image model to recognize that positive samples offer accurate interpretations, while negative samples are misleading and should be disregarded during training. In formal terms, this technique is called CLIP (Contrastive Language-Image Pre-training), introduced by OpenAI where authors trained an image-text model on something around 400 million image caption pairs taken from the internet, and every time model makes a mistake, the contrastive loss function increases and penalizes it to make sure the model trains well. The same principles are applied to the other modality combinations as well. Hence, the cat's voice with the word cat is a positive sample for the speech-text model, and a video of a cat with the descriptive text "this is a cat" is a positive sample for the video-text model.

Show time
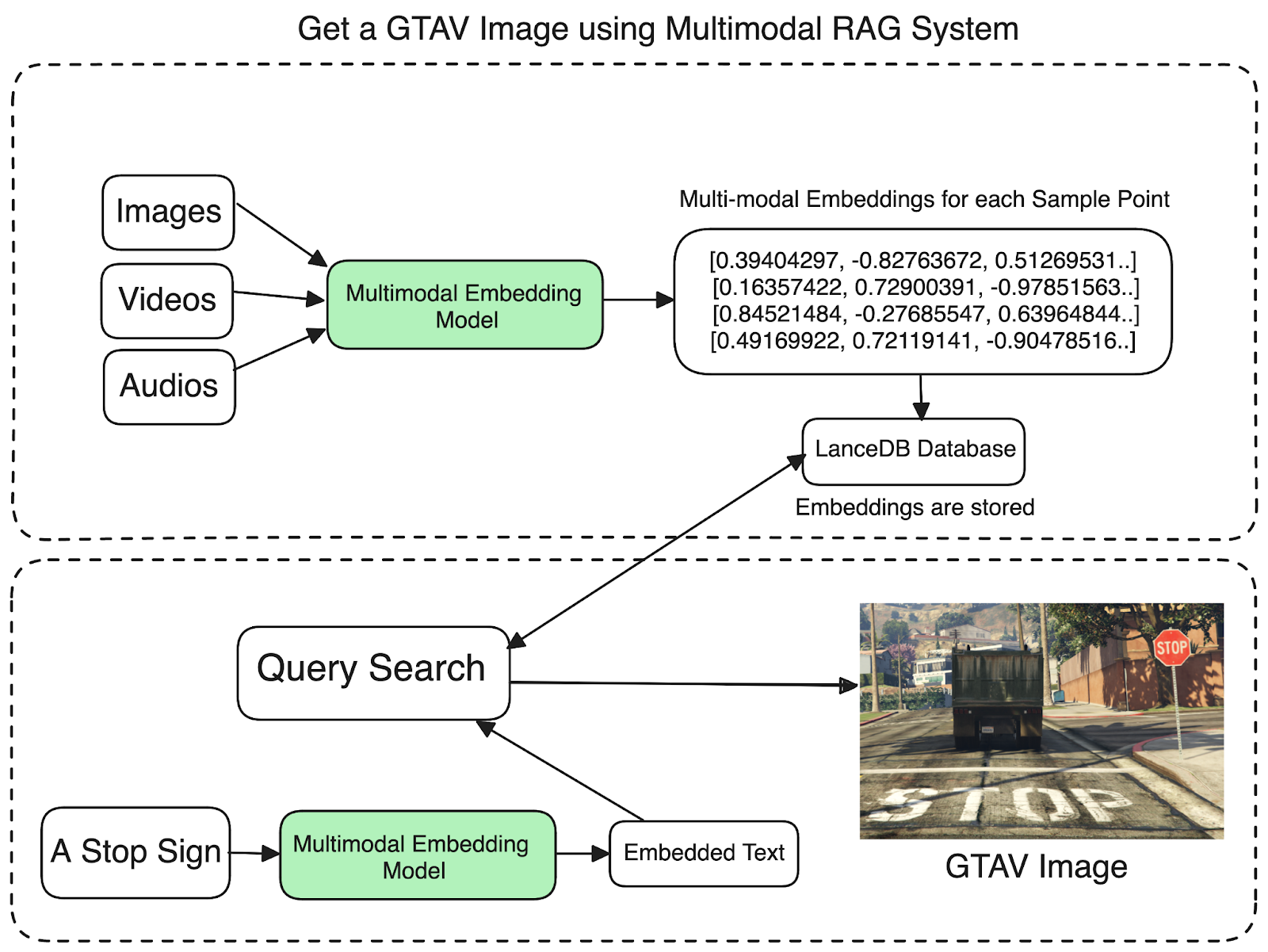
You don't have to build that box from scratch because folks have already done it for us. There's a Multimodal embedding model, like the "ViT-L/14" from OpenAI. This model can handle various data types, including text, images, videos, audio, and thermal and gyroscope data. Now, let's move on to the following question: How do we store those embeddings?
We'll need a vector database that can efficiently fetch, query, and retrieve relevant embeddings for us, ideally one that supports multimodal data and doesn't burn a hole in our wallets. That's where LanceDB comes into play.
Vector database
When we talk about the vector database, many options are available in the current market, but there is something about the LanceDB that makes it stand out as an optimal choice for a vector database. As far as I have used it, it addresses traditional embedded databases' limitations in handling AI/ML workloads. When I say traditional, I mean those database management tools that aren’t optimized for the heavy computation usage of the ML infrastructure.
TLDR: LanceDB is a serverless architecture, meaning storage and compute are separated into two distinct units. This design makes it exceptionally fast for RAG use cases, ensuring fast fetching and retrieval. Additionally, it has some notable advantages—being open source, utilizing its Lance columnar data format built on top of Apache Arrow for high efficiency and persistent storage capabilities, and incorporating its own Disk Approximate Nearest Neighbor search. All these factors collectively make LanceDB an ideal solution for accessing and working with multimodal data. I love you LanceDB ❤ ️
Data time
To add excitement, I've crafted a GTA-V Image Captioning dataset featuring thousands of images, each paired with descriptive text illustrating the image's content. When we train our magic box, the expectation is clear—if I ask that box to provide me an image of a "road with a stop sign," it should deliver a GTA-V image of a road with a stop sign. Otherwise, what's the point, right?
FAQ
1. We will use "ViT-L/14" to convert our multimodal data into its respective embeddings.
2. LanceDB is our vector database that stores the relevant embeddings.
3. GTA-V Image Captioning dataset for our magic box.
Environment Setup
I'm using a MacBook Air M1, and it's worth mentioning that certain dependencies and configurations might differ based on the system you're using.
Here are the steps to install the relevant dependencies
# Create a virtual environment
python3 -m venv env
# Activate the virtual environment
source env/bin/activate
# Upgrade pip in the virtual environment
pip install --upgrade pip
# Install required dependencies
pip3 install lancedb clip torch datasets pillow
pip3 install git+https://github.com/openai/CLIP.gitAnd remember to get your access token from the hugging face to download the data.
Downloading the Data
The dataset can easily be fetched using the datasets library.
import clip
import torch
import os
from datasets import load_dataset
ds = load_dataset("vipulmaheshwari/GTA-Image-Captioning-Dataset")
device = torch.device("mps")
model, preprocess = clip.load("ViT-L-14", device=device)Downloading the dataset may require some time, so please take a moment to relax while this process runs. Once the download finishes, you can visualize some sample points like this:
from textwrap import wrap
import matplotlib.pyplot as plt
import numpy as np
def plot_images(images, captions):
plt.figure(figsize=(15, 7))
for i in range(len(images)):
ax = plt.subplot(1, len(images), i + 1)
caption = captions[i]
caption = "\n".join(wrap(caption, 12))
plt.title(caption)
plt.imshow(images[i])
plt.axis("off")
# Assuming ds is a dictionary with "train" key containing a list of samples
sample_dataset = ds["train"]
random_indices = np.random.choice(len(sample_dataset), size=2, replace=False)
random_indices = [index.item() for index in random_indices]
# Get the random images and their captions
random_images = [np.array(sample_dataset[index]["image"]) for index in random_indices]
random_captions = [sample_dataset[index]["text"] for index in random_indices]
# Plot the random images with their captions
plot_images(random_images, random_captions)
# Show the plot
plt.show()
Storing the Embeddings
The dataset consists of two key features: the image and its corresponding descriptive text. Initially, our task is to create a LanceDB table to store the embeddings. This process is straightforward – you only need to define the relevant schema. In our case, the columns include a "vector" for storing the multimodal embeddings, a "text" column for the descriptive text, and a "label" column for the corresponding IDs.
import pyarrow as pa
import lancedb
import tqdm
db = lancedb.connect('./data/tables')
schema = pa.schema(
[
pa.field("vector", pa.list_(pa.float32(), 512)),
pa.field("text", pa.string()),
pa.field("id", pa.int32())
])
tbl = db.create_table("gta_data", schema=schema, mode="overwrite")Encode the Images
We'll simply take the images from the dataset, feed them into an encoding function that leverages our Multimodal Embedding model, and generate the corresponding embeddings. These embeddings will then be stored in the database.
def embed_image(img):
processed_image = preprocess(img)
unsqueezed_image = processed_image.unsqueeze(0).to(device)
embeddings = model.encode_image(unsqueezed_image)
# Move to CPU, convert to numpy array, extract element list
result = embeddings.detach().cpu().numpy()[0].tolist()
return resultSo our `embed_image` function takes an input image, preprocesses it through our CLIP model preprocessor, encodes the preprocessed image, and returns a list representing the embeddings of that image. This returned embedding serves as a concise numerical representation, capturing all the key features and patterns within the image for downstream tasks or analysis. Next, call this function for all the images and store the relevant embeddings in the database.
data = []
for i in range(len(ds["train"])):
img = ds["train"][i]['image']
text = ds["train"][i]['text']
# Encode the image
encoded_img = embed_image(img)
data.append({"vector": encoded_img, "text": text, "id" : i})Here, we're just taking a list and adding the numeric embeddings, reference text, and the current index ID to it. All that's left is to include this list in our LanceDB table. Voila, our data lake for the embeddings is set up and good to go.
tbl.add(data)
tbl.to_pandas()Until now, we've efficiently converted the images into their respective multimodal embeddings and stored them in the LanceDB table. Now, the LanceDB tables offer a convenient feature: adding or removing images is remarkably straightforward. Just encode and add the new image, following the same steps we followed for the previous images.
Query Search
Our next move is to embed our text query using the same multimodal embedding model we used for our images. Remember that "box" I mentioned earlier? Essentially, we want this box to create embeddings for our images and texts, ensuring that the representation of different types of data happens in the same way. Following this, we just need to initiate a search to find the nearest image embeddings that match our text query.
def embed_txt(txt):
tokenized_text = clip.tokenize([txt]).to(device)
embeddings = model.encode_text(tokenized_text)
# Move to CPU, convert to numpy array, extract element list
result = embeddings.detach().cpu().numpy()[0].tolist()
return result
res = tbl.search(embed_txt("a road with a stop")).limit(3).to_pandas()
print(res)Output:
0 | [0.064575195, .. ] | there is a stop sign...| 569 | 131.995728
1 | [-0.07989502, .. ] | there is a bus that... | 423 | 135.047852
2 | [0.06756592, .. ] | amazing view of a ... | 30 | 135.309937Let's slow down a bit and understand what just happened. Simply put, the code snippet executes a search algorithm at its core to pinpoint the most relevant image embedding that aligns with our text query. As showcased above, the resulting output gives us embeddings that closely resemble our text query. In the result, the second column presents the embedding vector, while the third column contains the image description that closely matches our text query. Essentially, we've determined which image closely corresponds to our text query by examining the embeddings of our text query and the image.
It's similar to saying, If these numbers represent the word "Cat," I spot an image with a similar set of numbers, so most likely it's a match for an image of a "Cat." 😺
If you are looking for an explanation of how the search happens, I will write a detailed explanation in the coming write-ups because it's so exciting to look under the hood and see how the search happens. There is something called Approximate Nearest Neighbors (ANN), a technique used to find the closest points in high-dimensional spaces efficiently. ANN is extensively used in data mining, machine learning, computer vision, and NLP use cases. So when we passed our embedded text query to the searching algorithm and asked it to give us the closest sample point in the vector space, it used a type of ANN algorithm to get it for us. Specifically, LanceDB utilizes DANN (Deep Approximate Nearest Neighbor) to search the relevant embeddings within its ecosystem.
In our results, we have five columns. The first is the index number, the second is the embedding vector, the third is the image's description matching our text query, and the fourth is the image's label. However, let's focus on the last column – Distance. When I mentioned the ANN algorithm, it simply draws a line between the current data point (in our case, the embedding of our text query) and identifies which data point (image) is closest to it. If you observe that the other data points in the results have a greater distance than the top one, it indicates they are a bit further away or more unrelated to our query. To clarify, the distance calculation is part of the algorithm itself.
D-DAY
Now that we have all the necessary information, displaying the most relevant image for our query is straightforward. Simply take the relevant label of the top-matched embedding vector and showcase the corresponding image.
data_id = int(res['id'][0])
display(ds["train"][data_id]['image'])
print(ds["train"][data_id]['text'])
there is a truck driving down a street with a stop signWhat’s next?
To make things more interesting, I'm currently working on creating an extensive GTA-V captioning dataset. This dataset will include more images paired with their respective reference text, providing a richer set of queries to explore and experiment with. Nevertheless, there's always room for refining the model. We can explore creating a customized CLIP model adjusting various parameters. Increasing the number of training epochs affords the model more time to grasp the relevance between embeddings.
Additionally, Meta developed an impressive multimodal embedding model known as ImageBind. We can consider trying ImageBind as an alternative to our current multimodal embedding model and comparing the outcomes. The fundamental concept behind the Multimodal RAG workflow remains consistent with numerous available options.
Explore Google Colab for access to the entire code in one place.