This article will teach us how to make an AI Trends Searcher using CrewAI Agents and their Tasks. But before diving into that, let's first understand what CrewAI is and how we can use it for these applications.
What is CrewAI?
CrewAI is an open-source framework that helps different AI agents work together to do tricky stuff. You can give each Agent its tasks and goals, manage what they do, and help them work together by sharing tasks. These are some unique features of CrewAI:
- Role-based Agents: Define agents with specific roles, goals, and backgrounds to provide more context for answer generation.
- Task Management: Use tools to dynamically define tasks and assign them to agents.
- Inter-agent Delegation: Agents can share tasks to collaborate better.
To better grasp CrewAI, let's create collaborative AI agents to get AI trends search engines using CrewAI.
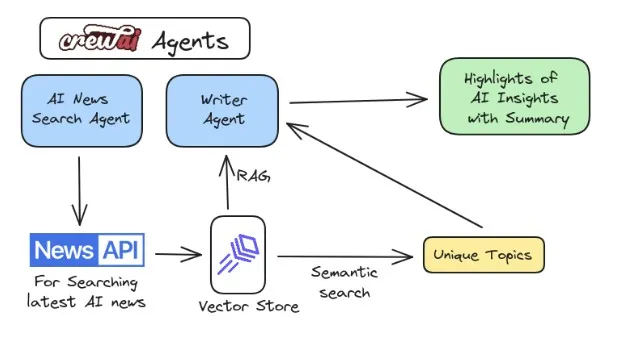
Building Crew to get AI trends
First, an AI news search agent finds the latest news using the News API and saves it into the LanceDB vector database. Then, a writer agent uses semantic search to gather all the unique news highlights from the vector database and create bullet points summarizing the current trends in AI.
Now we are clear with How we are going to create this crew, let's delve into the coding it
You'll require a News API key and OPENAI_API key for this project. The News API key is freely available here; get your API key, and let's get started
Install dependencies
pip install crewai langchain-community langchain-openai requests duckduckgo-search lancedb -qImport Required Modules
from crewai import Agent, Task, Crew, Process
from langchain_openai import ChatOpenAI
from langchain_core.retrievers import BaseRetriever
from langchain_openai import OpenAIEmbeddings
from langchain.tools import tool
from langchain_community.document_loaders import WebBaseLoader
import requests, os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import LanceDB
from langchain_community.tools import DuckDuckGoSearchRun
# Now let's keep our OpenAI API key and News API key as environment variable
os.environ["NEWSAPI_KEY"] = "*********"
os.environ["OPENAI_API_KEY"] = "sk-*********"for this example, we'll use the OpenAI embedding function to embed scrapped trending news and insert it in LanceDB. Additionally, we'll employ OpenAI's Language Model (LLM) for creating agents and executing their assigned tasks.
embedding_function = OpenAIEmbeddings()
llm = ChatOpenAI(model="gpt-4-turbo-preview")Setting up LanceDB
Now, let's set up the LanceDB vector database and table where we'll keep all our news and their respective embeddings.
import lancedb
# creating lancedb table with dummy data
def lanceDBConnection(dataset):
db = lancedb.connect("/tmp/lancedb")
table = db.create_table("tb", data=dataset, mode="overwrite")
return table
embedding = OpenAIEmbeddings()
emb = embedding.embed_query("hello_world")
dataset = [{"vector": emb, "text": "dummy_text"}]
# LanceDB as vector store
table = lanceDBConnection(dataset)Now we have set LanceDB, let's extract AI news and insert it with its embeddings into the vector database.
# Save the news articles in a database
class SearchNewsDB:
@tool("News DB Tool")
def news(query: str):
"""Fetch news articles and process their contents."""
API_KEY = os.getenv('NEWSAPI_KEY') # Fetch API key from environment variable
base_url = f"https://newsapi.org/v2/top-headlines?sources=techcrunch"
params = {
'sortBy': 'publishedAt',
'apiKey': API_KEY,
'language': 'en',
'pageSize': 15,
}
response = requests.get(base_url, params=params)
if response.status_code != 200:
return "Failed to retrieve news."
articles = response.json().get('articles', [])
all_splits = []
for article in articles:
# Assuming WebBaseLoader can handle a list of URLs
loader = WebBaseLoader(article['url'])
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
all_splits.extend(splits) # Accumulate splits from all articles
# Index the accumulated content splits if there are any
if all_splits:
vectorstore = LanceDB.from_documents(all_splits, embedding=embedding_function, connection=table)
retriever = vectorstore.similarity_search(query)
return retriever
else:
return "No content available for processing."Building RAG
Now we have all the trending news in our database, let's build a RAG around it.
# Get the news articles from the database
class GetNews:
@tool("Get News Tool")
def news(query: str) -> str:
"""Search LanceDB for relevant news information based on a query."""
vectorstore = LanceDB(embedding=embedding_function, connection=table)
retriever = vectorstore.similarity_search(query)
return retrieverSetting up a search tool for validating news extracted from API on the web, we'll use the DuckDuckGo search engine.
search_tool = DuckDuckGoSearchRun()Setting Up Agents with their roles and goals
# Defining Search and Writer agents with roles and goals
news_search_agent = Agent(
role='AI News Searcher',
goal='Generate key points for each news article from the latest news',
backstory="""You work at a leading tech think tank.
Your expertise lies in identifying emerging trends in field of AI.
You have a knack for dissecting complex data and presenting
actionable insights.""",
tools=[SearchNewsDB().news],
allow_delegation=True,
verbose=True,
llm=llm
)
writer_agent = Agent(
role='Writer',
goal='Identify all the topics received. Use the Get News Tool to verify the each topic to search. Use the Search tool for detailed exploration of each topic. Summarise the retrieved information in depth for every topic.',
backstory="""You are a renowned Content Strategist, known for
your insightful and engaging articles.
You transform complex concepts into compelling narratives.""",
tools=[GetNews().news, search_tool],
allow_delegation=True,
verbose=True,
llm=llm
)With the roles and goals for our agents established, let's assign tasks to them so we can officially add them to the crew.
# Defining Search and Writer agents with roles and goals
news_search_agent = Agent(
role='AI News Searcher',
goal='Generate key points for each news article from the latest news',
backstory="""You work at a leading tech think tank.
Your expertise lies in identifying emerging trends in field of AI.
You have a knack for dissecting complex data and presenting
actionable insights.""",
tools=[SearchNewsDB().news],
allow_delegation=True,
verbose=True,
llm=llm
)
writer_agent = Agent(
role='Writer',
goal='Identify all the topics received. Use the Get News Tool to verify the each topic to search. Use the Search tool for detailed exploration of each topic. Summarise the retrieved information in depth for every topic.',
backstory="""You are a renowned Content Strategist, known for
your insightful and engaging articles.
You transform complex concepts into compelling narratives.""",
tools=[GetNews().news, search_tool],
allow_delegation=True,
verbose=True,
llm=llm
)Now Let's define tasks associated with these agents.
# Creating search and writer tasks for agents
news_search_task = Task(
description="""Conduct a comprehensive analysis of the latest advancements in AI in 2024.
Identify key trends, breakthrough technologies, and potential industry impacts.
Your final answer MUST be a full analysis report""",
expected_output='Create key points list for each news',
agent=news_search_agent,
tools=[SearchNewsDB().news]
)
writer_task = Task(
description="""Using the insights provided, summaries each post of them
highlights the most significant AI advancements.
Your post should be informative yet accessible, catering to a tech-savvy audience.
Make it sound cool, avoid complex words so it doesn't sound like AI.
Your final answer MUST not be the more than 50 words.""",
expected_output=
'Write a short summary under 50 words for each news Headline seperately',
agent=writer_agent,
context=[news_search_task],
tools=[GetNews().news, search_tool]
)Now, we are ready with all our bits and pieces of AI trend searching, starting from trending News in LanceDB, RAG, and CrewAI agents' tasks. Let's connect all of it and build a crew that will perform all these tasks with a single kickoff.
Creating Crew
# Instantiate Crew with Agents and their tasks
news_crew = Crew(
agents=[news_search_agent, writer_agent],
tasks=[news_search_task, writer_task],
process=Process.sequential,
manager_llm=llm
)Kickoff the crew - Let the magic happen
# Execute the crew to see RAG in action
result = news_crew.kickoff()
print(result)Colab Walkthrough


Conclusion
Congratulations! We have created AI agents using CrewAI to search the latest trending AI news search. The CrewAI framework offers flexibility and can be customized to automate various tasks beyond content creation, including data analysis, customer support, and beyond. Try out different tasks, agents, and tools to unlock the complete potential of CrewAI in streamlining your workflows.