
Streaming data applications can be tricky. When you can read data faster than you can process the data then bad things tend to happen. The most common scenario is you run out of memory and your process crashes. When the process doesn't crash, it often breaks performance (e.g. swapping or pausing inefficiently). The various solutions to this problem are largely classified as "backpressure". It's been a while since I last posted in this series and one of the things I've been spending a lot of time on is getting backpressure right. It's proven to be quite tricky 🙃 In this blog post I want to explain some classic approaches for backpressure and then describe the approach we've been taking in the Lance file reader.
Push vs. Pull?
Whenever we talk about backpressure we also often talk about push vs. pull. In a push-based system a producer creates and launches a task as soon as data is available. This makes parallelism automatic but backpressure is tricky. In a pull-based system the consumer creates a task to pull a batch of data and process it. This makes backpressure automatic but parallelism is tricky.
The reality is that every multi-threaded scanner / query engine is doing both push and pull somewhere if you look hard enough. Both approaches have to solve this problem and systems tend to use the same classic solution to do so.
Classic Solution: Row Group Queue
The classic solution is to limit the number of row groups that can be processed with a queue somewhere between the producer and the consumer. If the queue fills up the then file reader will stop reading. There are a variety of ways this queue can be implemented (e.g. a blocking queue in a push-based workflow or a readahead queue in a pull-based workflow).
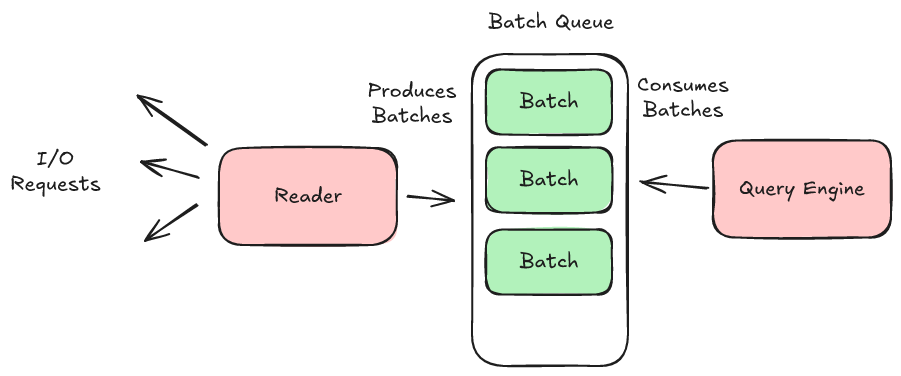
As an example we can consider the pyarrow scanner which has a from_dataset method with the following parameter:
batch_readahead - int, default 16
The number of batches to read ahead in a file. This might not work for all file formats. Increasing this number will increase RAM usage but could also improve IO utilization.
I don't want this post to be too long so I'm going to summarize the issues I've historically encountered with the row group queue approach:
- It's often unclear whether this limit applies to file-based row groups (which tend to be large) or compute-based batches (which tend to be small).
- The correct limit will depend on the query (how many columns are being loaded)
- Not all batches are the same size and so the correct limit can even fluctuate within a single query.
- Queuing batches means you are inserting a thread transfer between decode and compute. This is something we wanted to avoid in Lance.
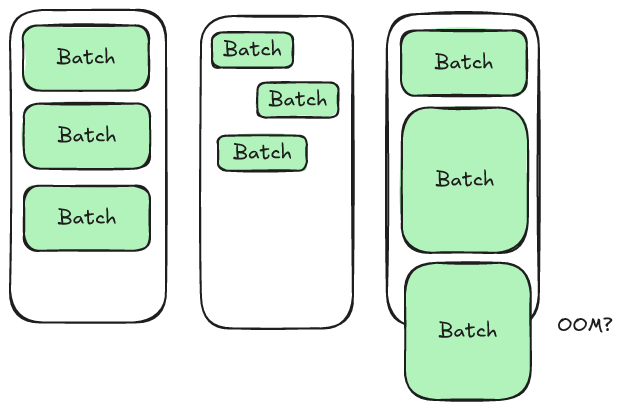
Our motivation for Lance is to find an approach that is simple to configure, can be consistently applied to all datasets, and can work without a concept of row groups.
Lance Solution: I/O Buffer
To understand the Lance solution we need to revisit the concept of separating I/O from decoding that we described in an earlier post. Every Lance reader has a "scheduling thread" and a "decode thread". The scheduling thread determines what I/O we need to issue and the decode thread takes the data, as it arrives, and decodes it.
In between these two threads is a special component called the I/O scheduler. It receives I/O requests from the scheduling thread, sorts them according to their priority order, throttles how many concurrent requests we can make, and then delivers the results to the decoders. This gives us the perfect place to apply backpressure.
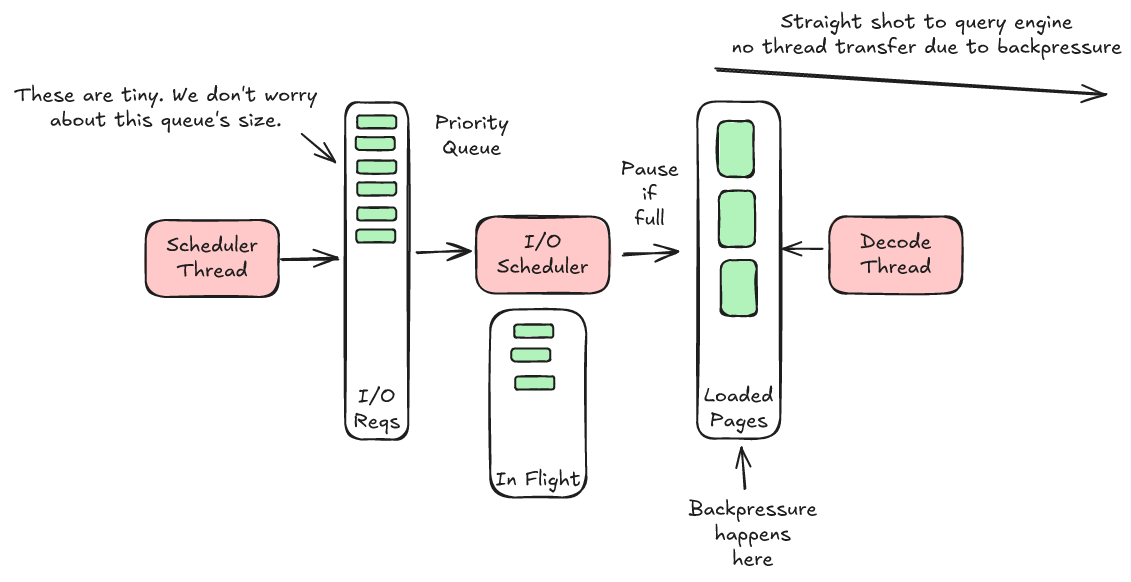
When the I/O scheduler finishes an I/O request it places the data in a queue for the decoders, the I/O buffer. If this queue fills up then we know the decoders are falling behind. The I/O scheduler will then stop issuing new I/O requests. When the decoders catch up then the buffer will start to empty and we can start issuing I/O requests again.
The best part about the I/O buffer is that the I/O buffer size is in bytes and not rows. What's more, we can easily calculate the correct value. We want to make sure that we have enough room in the buffer to saturate our I/O.
One Small Problem...
Unfortunately, we have one small wrinkle that's caused us a lot of trouble. When we are reading variable-size data types (e.g. strings, lists, etc.) we don't know up-front how many items we need to read from disk. For example, if the user asks for 10,000 strings then will a column need 1KiB? 1MiB? 50MiB? We simply don't know.
We never want to pause I/O. This means we don't want to stop and wait until the string sizes come back before we continue reading other columns. As a result, we end up scheduling some "lower priority" requests while we are waiting for the string sizes to come back. Once we know the string sizes we can make a high priority request to get the data.
Unfortunately, if our I/O buffer fills up with low priority items then we might not have space for a high priority request once our string sizes get back to us. The decoder works in priority order and, since our high priority request is stuck, the decoder gets stuck and the whole system grinds to a deadlock.
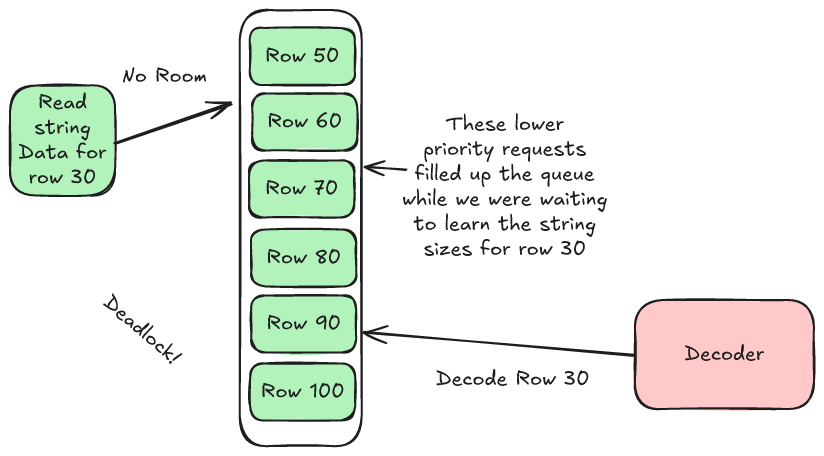
Our solution today is to allow requests to bypass the backpressure limit if they are higher priority than anything in the backpressure queue. This works, but it's a bit messy, and it got us thinking, "wouldn't it be great if we knew the priority ahead of time?" It turns out that we can record that information when we write the file and this is exactly what we plan to do in our 2.1 format.
It's unlikely users will ever notice (the current system works very well anyways) but it will let us rip out several complicated branches from our scheduling and decoding logic once we have finalized 2.1 and so I'm excited to move to the new system.
Conclusion
Configuring backpressure in Lance is very easy. In fact, it is so easy you should never really have to mess with it in normal scenarios (the default of 2GiB works well for most situations). We can read massive data files, turn around and process them slowly, and never have to worry about the reader using way too much memory. This is absolutely essential when working with multi-modal data because the large data types make it all too easy to waste RAM on the machine whenever you have an expensive processing step.