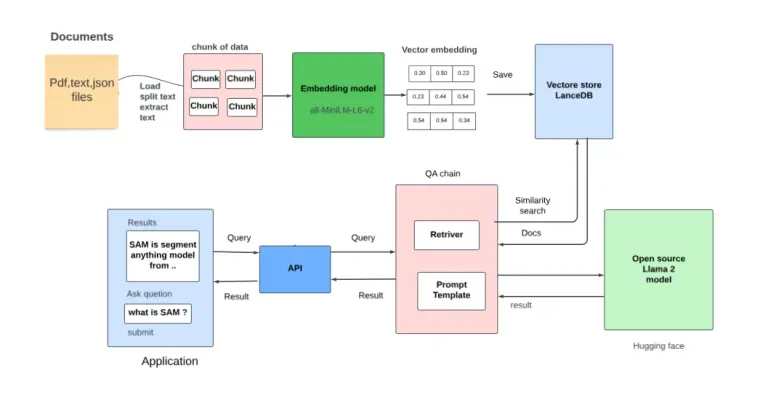
Building a real chatbot using RAG method – by Akash A. Desai
Introduction:
Many people know about OpenAI’s cool AI models like GPT-3.5 and GPT-4, but they’re usually not free to use. But here’s some good news: Meta has introduced a free, super-smart model called Llama-2. In this blog, we’re going to explore Llama-2 and use it to create a chatbot that can work with PDF files from scratch. Let’s break down the important parts step by step.
The Key Components for Building RAG based applications:
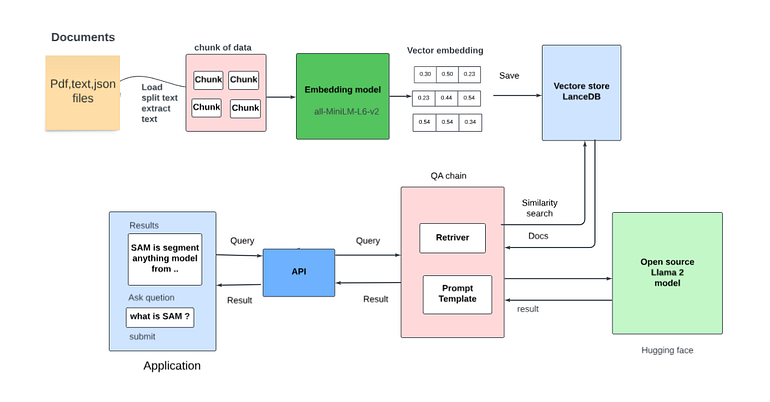
- Large Language Model: The cornerstone of our project is the Llama-2 Large Language Model. It boasts a multitude of applications and is ideal for our endeavor.
- Embedding Model: To enhance our chatbot’s performance, we employ the Huggingface embedding model, namely “sentence-transformers/all-MiniLM-L6-v2.”
- Vector Store Database: Efficiently managing data is paramount. To achieve this, we rely on a Vector Store database. We are using LanceDB vector base for this example
- Preprocessing Tool: Streamlining data preprocessing is crucial, and we leverage Langchain for this purpose.
System Compatibility:
Our system is designed to be accessible to a wide audience. It can be run smoothly on a local machine with a minimum of 15GB VRAM, even on a CPU setup. For the Llama-2 model, we opt for the quantized GGML version, which can be sourced from the Bloke repo Additionally, we utilize the Huggingface embedding model sentence-transformers/all-MiniLM-L6-v2.
Unlocking the Power of Large Language Models (LLMs) with RAG
In today’s world, making the most of Large Language Models (LLMs) in your business doesn’t have to be expensive or complicated. Let’s explore an approach called Retrieval Augmented Generation (RAG), which can help you get better results without breaking the bank.
What is RAG and Why Should You Care?
RAG, short for Retrieval Augmented Generation, is a clever technique that boosts the abilities of LLMs. It works like this: Imagine you have a smart assistant who can read and understand a huge library of books. When you ask it a question, it doesn’t just guess the answer — it actually looks up the answer in those books. This means you get more accurate and reliable information.
Here’s why RAG is a great choice:
- No More Misinformation or Hallucination: RAG ensures your LLM doesn’t make things up. It retrieves real information, enhancing the reliability of your results. To understand how it works and see examples, we’ll provide references to documents for easy interpretation
- Budget-Friendly: RAG saves you money. It’s cheaper to use and keeps your LLM up-to-date with the latest information without constant expensive training.
- Easy Updates: When you need to fix or update things, RAG makes it simple. It’s like adding or removing books from a library, not rewriting a whole new book.
The Role of LanceDB: Your Superpowered Database
In the realm of data management, LanceDB emerges as a pioneering vector database that’s tailor-made for developers. It offers a unique proposition: It's serverless, It has Python data ecosystem & native javascript support, zero management overhead, developer-friendly features, and open-source accessibility. This lightweight solution seamlessly scales from development environments to production, all while being astoundingly cost-effective, and priced up to 100x cheaper than alternatives
Think of Lancedb as the engine that makes RAG run smoothly. It’s like having a supercharged search engine for your data. Here’s why Lancedb is a game-changer:
- Find What You Need Fast: Lancedb helps you find the right information quickly and accurately, making your LLM-powered applications more efficient.
- Grows with You: As your data grows, Lancedb can handle it without slowing down. It scales up easily.
- Handles All Kinds of Data: Whether it’s text, images, or other types of data, Lancedb can handle it all, making it a flexible tool for many tasks.
By using RAG with Lancedb, you can give your LLM-powered systems the ability to provide accurate and up-to-date information, all while keeping your costs in check.
In summary, RAG and Lancedb are like the dynamic duo of cost-effective, reliable LLM-powered applications. They help your systems give you better, more trustworthy information without the complexity or high costs. This means you can stay competitive and provide top-notch service in today’s data-driven world.
By storing embeddings in LanceDB, we open up exciting possibilities, such as building chatbots that can engage with PDF documents.
Enough theory! Now it’s time to code
Follow along with Google Colab


let’s shift our focus to the coding aspect. First, we need to install the required packages:
Install some important packages
!pip install --quiet langchain
!pip install --quiet -U lancedb
!pip install pypdf
!pip install sentence-transformers
!pip install unstructured
!pip install ctransformerslet's import the packages
import lancedb
import re
import pickle
import requests
import zipfile
from pathlib import Path
from langchain.document_loaders import UnstructuredHTMLLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders import PyPDFLoader, DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
import lancedb
from langchain.llms import CTransformers
from langchain.chains import RetrievalQA
from langchain.vectorstores import LanceDB
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitterThe next step is to attach the Google Drive to the collab notebook, where your PDFs are present as well as the LLM model weight.
In this example, two PDF files are placed in a folder named “data” within Google Drive.
#mount the drive
from google.colab import drive
drive.mount('/content/drive')Let’s load the embedding model
The all-mpnet-base-v2 model provides the best quality, while all-MiniLM-L6-v2 is 5 times faster and still offers good quality. you can try different models from here
we are using all -MiniLM-L6-V2 models for this demo, & we are using CPU for inference
#load embedding model
embeddings_mini = HuggingFaceEmbeddings(model_name='sentence-transformers/all-MiniLM-L6-v2',
model_kwargs={'device': 'cpu'})effortlessly you can manage multiple PDFs.
download the sample PDFs from here & give the path of the PDF folder
#Load multiple pdfs
pdf_folder_path = '/content/drive/llm/pdf_paths/'
from langchain.document_loaders import PyPDFDirectoryLoader
loader = PyPDFDirectoryLoader(pdf_folder_path)
docs = loader.load()for a single PDF, you can use the below format
# load single pdf
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("/content/drive/llm/pdfs/layoutparser.pdf")
docs = loader.load_and_split()we are using it is RecursiveCharacterTextSplitter its configured to split text into smaller chunks for efficient processing, with a chunk size of 200 characters and a chunk overlap of 50 characters. These parameters can be adjusted to fine-tune the splitting process for optimal results.
# Now that we have our raw documents loaded, we need to pre-process them to generate embeddings:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200, # 500
chunk_overlap=50, #100 play with this numbers for better results
)
documents = text_splitter.split_documents(docs)
embeddings = embeddings_minilet's use our Vector store LanceDB
we are connecting to LanceDB, creating a table, and setting up a document search.
db = lancedb.connect('/tmp/lancedb')
table = db.create_table("pdf_search", data=[
{"vector": embeddings.embed_query("Hello World"), "text": "Hello World", "id": "1"}
], mode="overwrite")
docsearch = LanceDB.from_documents(documents, embeddings, connection=table)Now, as we are using the Llama 2 quantized model, you need to download and upload it to your Google Drive. You can choose different versions based on your system specifications. For demonstration purposes, we are using a small model, but feel free to explore other options by downloading the models from Thebloke repo.
#Loading the model
def load_llm():
# Load the locally downloaded model here
llm = CTransformers(
model = "llama-2-7b-chat.ggmlv3.q2_K.bin",
model_type="llama",
max_new_tokens = 512,
temperature = 0.6
)
return llm
qa = RetrievalQA.from_chain_type(llm=load_llm(), chain_type="stuff", retriever=docsearch.as_retriever())Finally, you can ask the questions to your llm & it will give you a response
query = "What is DIA?"
qa.run(query)query = "What is LayoutParser ?"
qa.run(query)Feel free to explore the power of LLMs on your own data with this Google Colab
Summary :
Throughout our journey, we’ve achieved two significant milestones: first, crafting a chatbot capable of working with single documents, and second, advancing to the realm of multi-document chatbots with the ability to remember previous interactions. Along the way, we’ve delved into the intricacies of embeddings, vector storage, and fine-tuning parameters for our chatbot’s efficiency.
Stay tuned for upcoming blogs where we’ll take a deeper dive into the captivating realm of Large Language Models (LLMs). If you’ve found our exploration enlightening, we’d greatly appreciate your support. Be sure to leave a like!
But that’s not all. For even more exciting applications of vector databases and Large Language Models (LLMs), be sure to explore the LanceDB repository. LanceDB offers a powerful and versatile vector database that can revolutionize the way you work with data.
Explore the full potential of this cutting-edge technology by visiting the vector-recipes. It’s filled with real-world examples, use cases, and recipes to inspire your next project. We hope you found this journey both informative and inspiring. Cheers!