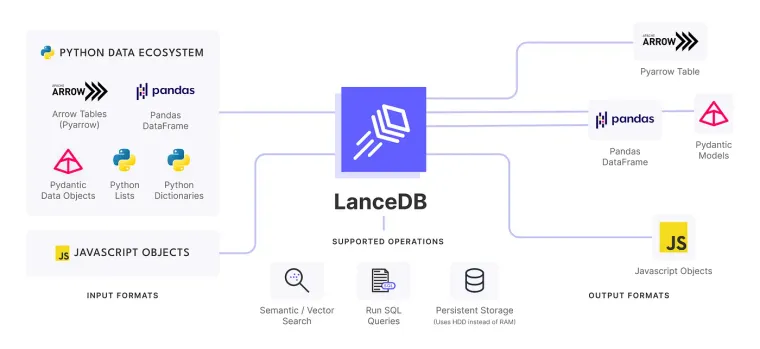
Vector databases are extremely useful for RAG, RecSys, computer vision, and a whole host of other ML/AI applications. Because of the rise of LLMs, there has been a lot of focus on vector indices, query latency, as well as the tradeoffs between latency and recall of various indices. What’s often neglected is the time it takes to build a vector index. Building a vector index is a very computationally intensive process that increases quadratically with the number of vectors or vector dimensions. As you scale up in production, this becomes a much bigger bottleneck for your AI stack.
Over the past few months, we’ve made some pretty amazing improvements using CPUs to build vector indices. And now we’re making a much bigger leap by supporting GPU acceleration for index building. So if you have access to an Nvidia GPU or a Macbook that supports MPS, you can now take advantage of the unparalleled computing power of GPUs when training large scale vector indices.
Training vector indices is expensive
Common indexing techniques like IVF (InVerted File index) or compression like PQ (Product Quantization) divide up the vectors into clusters. To find the cluster centroids, we have to use KMeans. While there are various techniques to improve the performance of KMeans, at the end of the day, it scales quadratically. This means that index training time quickly becomes prohibitively expensive at high scale.
The KMeans training algorithm is an iterative process where a ton of vector distance computations are performed to minimize the distance of vectors to their assigned clusters. It turns out that GPUs are amazingly good at this kind of math. Indexing libraries like FAISS, for example, support GPU-accelerated index training, but most vector databases have yet to add GPU support (and certainly haven’t made it easy).
LanceDB support for GPU-acceleration
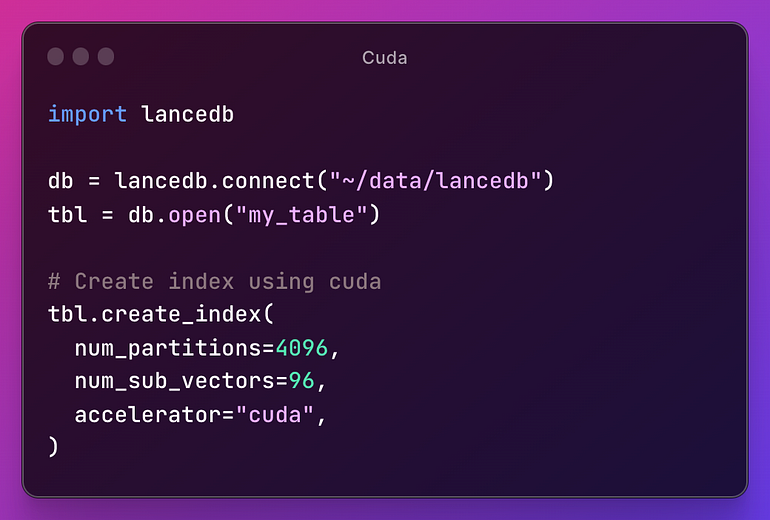
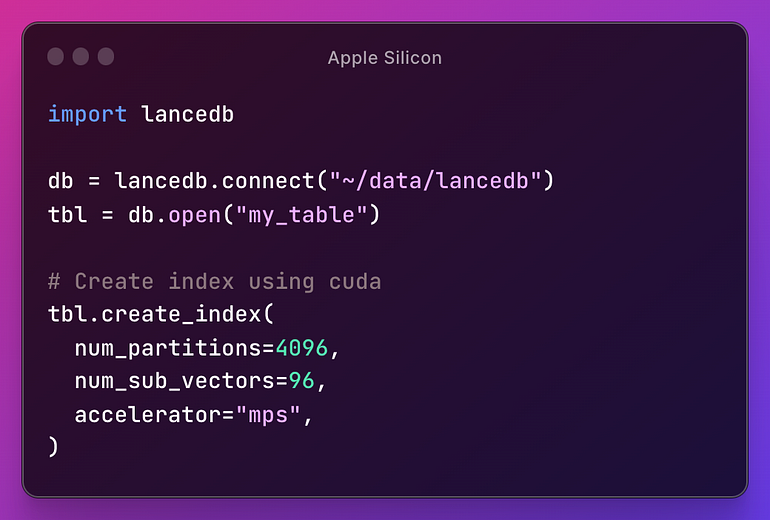
Since the beginning of LanceDB, users managing embeddings at scale have asked for GPU-acceleration to speed up their index training. In the most recent release of the Python package of LanceDB (v0.3.3), backed by Lance (v0.8.10), you can now use either CUDA or MPS by simply specifying the “accelerator” parameter when calling create_index :
Using GPU in Lancedb is as simple as specify the accelerator parameter on create_index().
Under the hood, LanceDB uses PyTorch to train the IVF clusters, and passes the kmeans centroids to the Rust core for index serialization. Thanks to the high-quality support of Cuda and MPS from the PyTorch community, it allows us to quickly deliver on two of the most popular developer platforms (Linux and Mac). Combined with other recent improvements in the LanceDB indexing process, for instance, out-of-memory shuffling, batched KMeans training in GPU, LanceDB can reliably train over tens of millions vectors without worrying about CPU or GPU Out of Memory (OOM).
Make sure you have pytorch installed (with CUDA if applicable) to use GPU-acceleration in LanceDB
Results
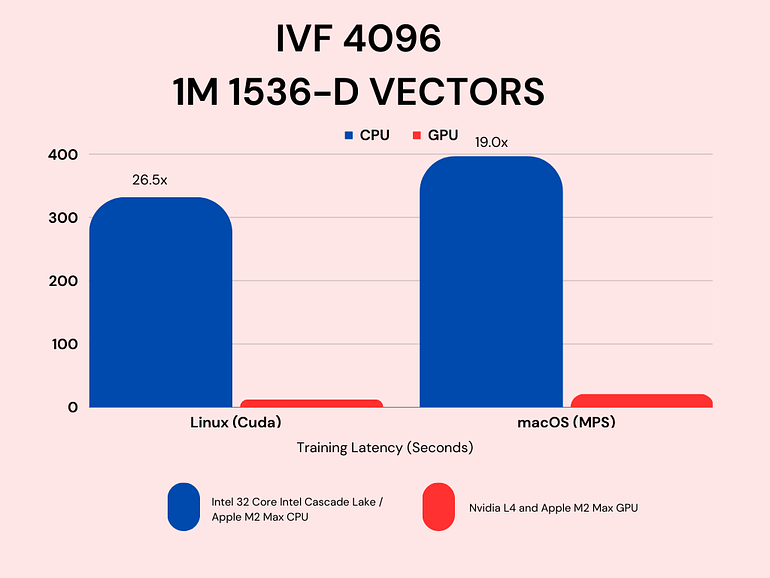
To benchmark the performance improvement for KMeans training, we trained IVF_4096 (4096 clusters) using L2 euclidean distance on a 1-million vector dataset with OpenAI Ada2 embeddings (1536D). This was done on Linux and also on MacOS:
- Google Cloud g2-standard-32 instance, 32 logical cores, and 1 x Nvidia L4 GPU, Ubuntu 22.04, nvidia-driver-525
- Apple M2 Max Macbook Pro 14', with 64GB RAM, 30 GPU cores.
In general, GPU acceleration offers up to 20–26x speed up compared to their CPU counterparts:
- Linux VM: 323s on CPU, and 12.5s on GPU
- Macbook Pro: 397s on CPU, and 21s on GPU
What’s next
Currently the IVF KMeans training is only one part of the whole index training process. We’re going to be working to add GPU acceleration for PQ training and also assigning the vectors to the correct centroids. Once this is completed, you’ll see even more drastic improvements in end-to-end index training time.
In addition, PyTorch offers LanceDB an easy path for large-scale distributed GPU training, as well as access to even more hardware accelerators (i.e., TPU via XLA) in the future. Imagine being able to train a vector index in minutes on billions of vectors, on any hardware.
Finally, now that we have a mechanism to use the GPU effectively, we could also use it for inference down the road.
Try it out!
You can start to benefit Cuda and Apple Silicon GPU support today via pip install lancedb. If you found this useful or interesting, please show us some love by starring LanceDB and Lance format.
And if you’re looking for a hosted vector database, sign up for a private preview of LanceDB Cloud at https://lancedb.com/