
Decrease chunk retrieval failure rate by 35% to 50%
Have you ever worked on a task where your users search in one language and the context is in another? Tasks like text to code, text to music composition, text to SQL etc etc. When you work on these tasks, you have strings like code, and textual context that do not make sense with BM-25 matching and the query has some semantic sense where you cannot convert it to code. Let's see how we can tackle this problem with contextual retrieval.

Let's start with implementing a basic RAG with a code search and generation!
You can follow along with colab:

!pip install -U openai lancedb einops sentence-transformers transformers datasets tantivy rerankers -qq
# Get the data
!wget -P ./data/ https://raw.githubusercontent.com/anthropics/anthropic-cookbook/refs/heads/main/skills/contextual-embeddings/data/codebase_chunks.json
# IMPORT
import os, re, random, json
import pandas as pd
from datasets import load_dataset
import torch
import gc
import lancedb
import openai
from lancedb.embeddings import get_registry
from lancedb.pydantic import LanceModel, Vector
from tqdm.auto import tqdm
from openai import OpenAI
pd.set_option('max_colwidth', 400)
OAI_KEY = "sk-....." # Replace with your OpenAI Key
os.environ["OPENAI_API_KEY"] = OAI_KEY
gpt_client = OpenAI(api_key = OAI_KEY) # For Contenxt text generation
model = get_registry().get("sentence-transformers").create(name="BAAI/bge-small-en-v1.5", device="cuda") # For embedding
Now let's chunk some data and create a DB!
def load_raw_data(datapath = '/content/data/codebase_chunks.json', debugging = False):
with open(datapath, 'r') as f: dataset = json.load(f)
if debugging:
print("Debugging Mode: Using few doc samples only ")
dataset = dataset[:5] # just use a sample only
data = []
num_docs = len(dataset)
total_chunks = sum(len(doc['chunks']) for doc in dataset)
with tqdm(total = num_docs, desc=f"Processing {total_chunks} chunks from {len(dataset)} docs") as pbar:
for doc in dataset: # Full document
for chunk in doc['chunks']: # Each document has multiple chunks
data.append(
{"raw_chunk": chunk['content'], # We won't make Embedding from this instead we'll create new Context based on Chunk and full_doc
"full_doc": doc["content"], # This shouldn't be saved in DB as it'll grow the DB size to a lot
'doc_id': doc['doc_id'],
'original_uuid': doc['original_uuid'],
'chunk_id': chunk['chunk_id'],
'original_index': chunk['original_index'],
})
pbar.update(1)
return data
raw_chunks = load_raw_data(debugging = True) # For debugging and tutorial purpose, just use ther first few documents onlyLet's create a basic RAG that we do and search a query to see the result right!
class VanillaDocuments(LanceModel):
vector: Vector(model.ndims()) = model.VectorField() # Default field
raw_chunk: str = model.SourceField() # the Columns (field) in DB whose Embedding we'll create
doc_id: str # rest is just metadata below
original_uuid: str
chunk_id: str
original_index: int
full_doc: str
db = lancedb.connect("./db")
vanilla_table = db.create_table("vanilla_documents", schema=VanillaDocuments)
vanilla_table.add(raw_chunks) # ingest docs with auto-vectorization
vanilla_table.create_fts_index("raw_chunk") # Create a fts index before so that we can use BM-25 laterQUERY = "implement corpus management with event handling"
vanilla_table.search(QUERY, query_type="hybrid").\
limit(3).\
to_pandas().\
drop(["vector", "original_uuid"], axis = 1)
Umm!!! Looks weird, Some random functions are coming up! You see, doc_2_chunk_0 -> doc_3_chunk_0 it means that the retriever is giving two different modules as chunks and if you use it as context, your user, program, ROI is going to suffer. This happens because there was no docstring and retriever had no idea of which function is exactly doing the asked task.
Solution? Contextual Retrieval!
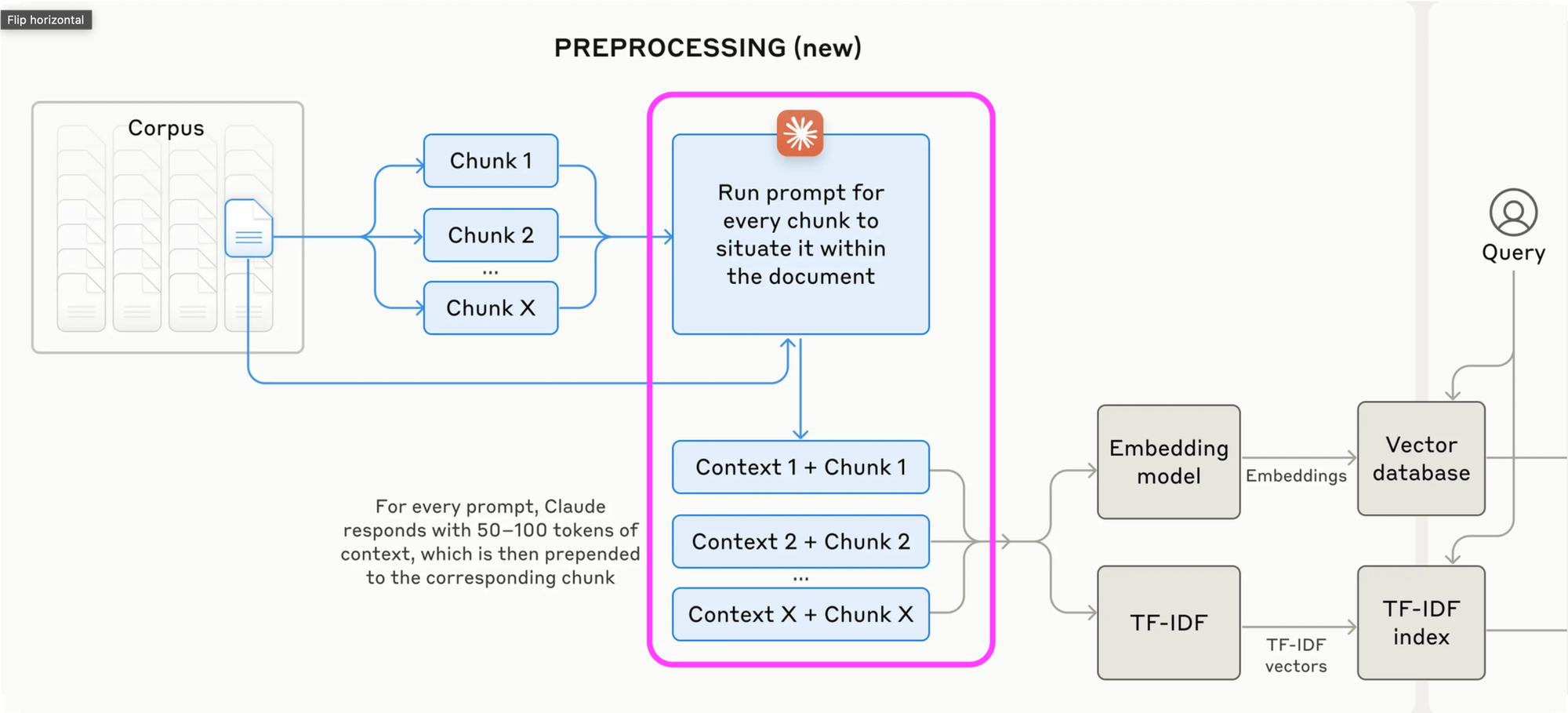
Let's take the same example of a text-to-code generation from above. What can you do to improve the issue above? You'd either go in the past and ask the developer building the code to write detailed docstring and comments. Another solution could be to generate a doc-string for the whole function and module. Well! you're very close to what Anthropic mentioned in their research. The idea here is to do these things:
- For each document, make chunks (Nothing new. Just like Vanilla RAG)
- For each Chunk you created, as an LLM create a context of that Chunk (You see this is new!)
- Append that context to the original chunk
- Create BM-25 and Vector Index based on those chunks for Hybrid Search (New to you? See this blog on hybrid search)
- Search as usual!
def create_context_promopt(full_document_text, chunk_text):
prompt = f"""
<document>
{full_document_text}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{chunk_text}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk.
Answer only with the succinct context and nothing else.
"""
return prompt, gpt_client.chat.completions.create(model = "gpt-4o-mini", messages=[{"role": "user", "content": prompt}]
).choices[0].message.content.strip()
for chunk in raw_chunks:
prompt, response = create_context_promopt(chunk["full_doc"], chunk["raw_chunk"])
chunk["prompt"] = prompt
chunk["chunk_context"] = response
chunk["chunk_with_context"] = chunk["chunk_context"] + "\n" + chunk["raw_chunk"]What does the above code portion do?
What the above code does is ask an LLM to create the context for the chunk. How But the chunks here are portion of the some code from file. How would it create the whole context if the code if from in between?
This is where the first part of prompt <document> comes in. Along with the chunk, we are passing the whole document (full code in our case) so that the LLM has access to the entire code and write context for the code portion we want.
Wait! the whole document along with the chunk? What? If a document has 20 Chunks, it means we'll be passing the whole document 20 times? Wouldn't it be too costly on the input tokens I send to any LLM?

Prompt Caching to the rescue
For a bigger knowledge base containing millions of chunks, it becomes very expensive to append context for each chunk. With prompt caching, you only need to load a document into the cache once instead of passing it in for every chunk. By structuring your prompts effectively, you can save 50-90% on costs through this feature available from LLM providers. If the same prefix appears in prompts within 5-10 minutes, you won’t be charged for those tokens again. We designed the prompts so that the document cost is incurred just once, reducing expenses for all subsequent chunks.

Let's make the new table and see the results. Remember, here we are creating index from the text field which is basically the Chunk Context + Original Chunk
class Documents(LanceModel):
vector: Vector(model.ndims()) = model.VectorField() # Default field
text: str = model.SourceField() # the Columns (field) in DB whose Embedding we'll create
doc_id: str # rest is just metadata below
raw_chunk:str
full_doc: str
original_uuid: str
chunk_id: str
original_index: int
KEYS = ["raw_chunk", "full_doc", "doc_id", "original_uuid", "chunk_id", "original_index"]
context_documents = []
for chunk in raw_chunks:
temp = {"text": chunk["chunk_with_context"]} # Create embedding from 'text' field which is (Chunk_Context_i + Chunk_i)
for key in KEYS: temp[key] = chunk[key] # Get other metadata
context_documents.append(temp)
context_table = db.create_table("added_context_table", schema=Documents)
context_table.add(context_documents) # ingest docs with auto-vectorization
context_table.create_fts_index("text") # Create a fts index before so that we can use BM-25 laterIn the final step, we boosted performance by querying Contextual Retrieval with hybrid search. In traditional RAG, vector search often retrieves many chunks from the knowledge base — of varying relevance.
Let's search and see the difference
context_table.search(QUERY, query_type="hybrid").\
limit(3).\
to_pandas().\
drop(["vector", "original_uuid"], axis = 1)
As you can see from the above, both the top-2 codes are from the same document doc_2_chunk_0 -> doc_2_chunk_3
You can evaluate them automatically using the eval dataset here.
Run it yourself:

Rules of thumb
When implementing Contextual Retrieval, keep the following factors in mind:
- Chunk Boundaries: How you split documents into chunks can affect retrieval performance. Pay attention to chunk size, boundaries, and overlap.
- Embedding Model: While Contextual Retrieval improves performance across various models, some like Gemini and OpenAI may benefit more.
- Custom Prompts: A generic prompt works well, but tailored prompts for your specific domain—such as including a glossary—can yield better results.
- Number of Chunks: More chunks in the context window increase the chance of capturing relevant information, but too many can overwhelm the model. We found that using 20 chunks performed best, though it’s good to experiment based on your needs.
Conclusion
Using the combinations of contextual retrieval, prompt caching, and LanceDB hybrid search, differences in Naive Retrieval and Contextual Retrieval shows both the top-2 codes are from the same document. To make this search results even better and refined LanceDB Reranking API can be used.