by Mahesh Deshwal
What is Hybrid Search, and what’s the need for it?
With the increasing usage of LLMs in RAG setting, there’s a lot of focus on Vector (Embedding) search. Everything works well when you’re dealing with toy problems or datasets, but you start to notice performance and evaluation constrains as the applications scale. What do I mean by that? Let’s take an example of a simple search from a global company where you know user preferences like taste in music, geo-location, etc.
Now, if they love Rap music and search lyrics to a song, you wouldn’t want to recommend something they hate or a song having the same meaning in a different language, at any cost. Another example of a bad result is that if they want to literally search a book named “Elephant in the Room,” and you give them a paragraph providing the semantic meaning of it. That’s a pretty good recipe for user churn. So what’s the solution?
Hybrid search
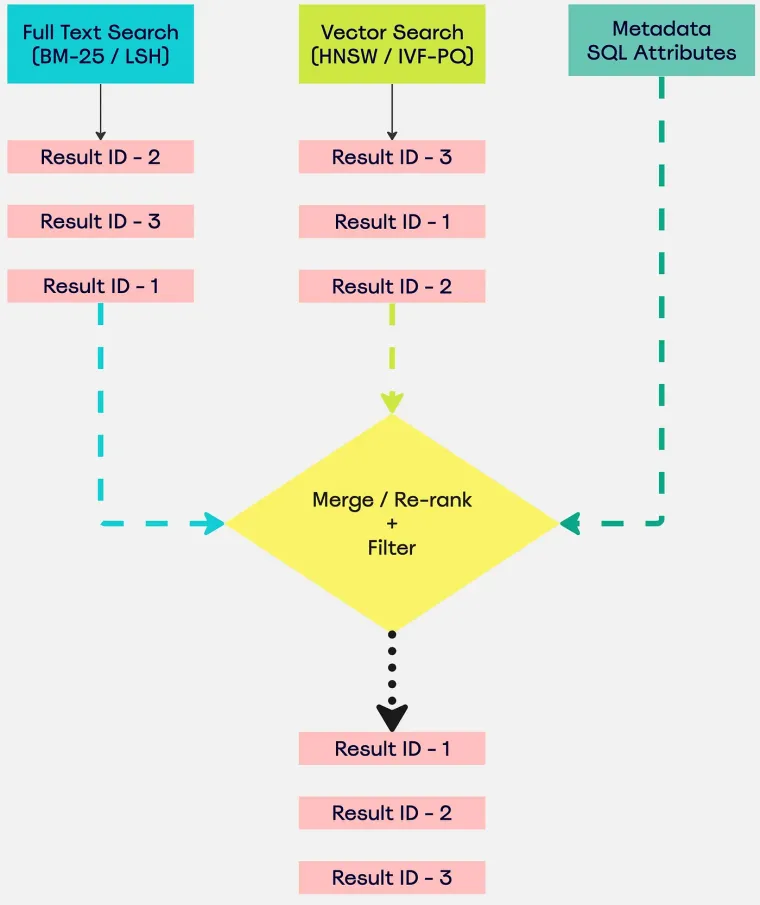
There are a few common ways of searching for queries these days:
- Full-text search (FTS) — Where you search the exact query in DB “syntactically” matching the words. Some famous algorithms used for these are BM-25 and LSH. This is a keyword based search
- Vector (Embedding) search — This takes in an embedding of of text, video, audio etc and returns the “semantically” similar results. Some most used algorithms by vector databases are PQ, IVF-PQ, HNSW, etc
- SQL (or NoSQL) — These use conditional filters where you filter the data based on things you already know.
Hybrid Search is a broad (often misused) term. It can mean anything from combining multiple methods for searching, to applying ranking methods to better sort the results. In this blog, we use the definition of “hybrid search” to mean using a combination of keyword-based and vector search.
Now that we have a general idea of how hybrid search works, let’s take a look at a few methods that you can use to merge these together. Let’s assume you have your Top-K results for both Semantic Search as well as Text Search. Now let’s suppose you have some metadata from the user. For example user is searching for specific items or maybe user wants to search in particular genre or maybe user is from a particular geo-location. What you can do now is to use filters (SQL or Pandas) to remove the unwanted results to further improve your search.
1. Fusion / Merging of scores:
In fusion or merging, you take both sets of results and combine them by some logic. But keep in mind that usually BM-25 has unbounded scores and Vector search has scores between 0–1 as it’s cosine similarity mostly. So, you need to “normalize” the scores to keep them in the same range. You can apply Min-Max scaling.
How you merge is up to you. If your task is more semantic-oriented, you can give more weight (say 0.75) to semantic search scores and the remaining (0.25) to normalized BM-25 scores or vice versa. You can choose to remove the results that are not common OR place them at the end OR sort according to their scaled score (multiplied by 0.75 or 0.25, depending on which category they belong to). FYI, there are also other ways of calculating new scores directly by using retrieved text and query pair, without using the existing scores. For example — Cross encoders or API based rerankers like Cohere.
2. Re-Ranking:
In re-ranking, you increase the recall to fetch more than needed results. Now look at the result returned from both tables and then you shift the rank of results, which are common in both. If your task is more syntactic, then you look at the BM-25 results and sort that table, and if your task is more semantic, then you can re-rank the embedding results based on whether the same occurs in BM-25 or not. So here, you first increased recall, and then you reranked to increase precision.
3. Stacked & Filtered results:
You can get the BM-25 and Vector results based on different filter criteria. For example, you would want to get all the BM-25 results where the length of the text is < 150 AND the Language is English, but for the semantic search, you’d want to get results in any language. Now how do you use those? One thing I used once was to “stack” one after another. 1st final can come from BM-25 (or Vector search) 2nd comes from the Vector (or BM-25) and so on. You get a balance between these.
A study of how some of these actually work in practice is given in this blog.
Apart from these approaches, you can use a Re-Ranker to re-score all of the Top-K results once again using a semantic reranker or some other approach like MinHash, SimHash, etc. To know more on Re-ranking, read here.

Let’s look at some code.
LanceDB uses tantivity for the full text search. It also provides a Reranking API, where you can define your merge/fusion function AND make use of Re Ranking too. If you don’t know about Re ranking, Visit this blog.
import os
import lancedb
import re
import pandas as pd
import random
from datasets import load_dataset
import torch
import gc
import lance
import os
import lancedb
import openai
from lancedb.embeddings import get_registry
from lancedb.pydantic import LanceModel, Vector
os.environ["OPENAI_API_KEY"] = "sk-......." #YOUR API
embeddings = get_registry().get("openai").create()Now let us create a LanceDB table and load the the good old BEIR data. Remember, in this data, there is no metadata so we are creating our additional metadata as the Number of words for demo purpose
queries = load_dataset("BeIR/scidocs", "queries")["queries"].to_pandas()
full_docs = load_dataset('BeIR/scidocs', 'corpus')["corpus"].to_pandas().dropna(subset = "text")
docs = full_docs.head(64) # just random samples for faster embed demo
docs["num_words"] = docs["text"].apply(lambda x: len(x.split())) # Insert some Metadata for a more "HYBRID" search
docs.sample(3)
class Documents(LanceModel):
vector: Vector(embeddings.ndims()) = embeddings.VectorField()
text: str = embeddings.SourceField()
title: str
num_words: int
data = docs.apply(lambda row: {"title":row["title"], "text":row["text"], "num_words":row["num_words"]}, axis = 1).values.tolist()
db = lancedb.connect("./db")
table = db.create_table("documents", schema=Documents)
table.add(data) # ingest docs with auto-vectorization
table.create_fts_index("text") # Create a fts index before the hybrid search_id title text num_words
8804 d2fbc1a8bcc7c252a70c524cc96c14aa807c2345 Approximating displacement with the body veloc... In this paper, we present a technique for appr... 128
6912 75859ac30f5444f0d9acfeff618444ae280d661d Multibiometric Cryptosystems Based on Feature-... Multibiometric systems are being increasingly ... 200
5797 90a2a7a3d22c58c57e3b1a4248c7420933d7fe2f An integrated approach to testing complex systems The increasing complexity of today’s testing s... 332Moment of truth? Let’s search first giving more weight to Full Text Search
from lancedb.rerankers import LinearCombinationReranker
reranker = LinearCombinationReranker(weight=0.3) # Weight = 0 Means pure Text Search (BM-25) and 1 means pure Sementic (Vector) Search
table.search("To confuse the AI and DNN embedding, let's put random terms from other sentences- automation training test memory?", query_type="hybrid").\
rerank(reranker=reranker).\
limit(5).\
to_pandas()
You see, I confused the model with the query by putting random terms for text but the sense was different. Since it is 0.3 it favours more to the text search. Now let’s full throttle to 0.7 and se the results for the same query

Whoohooo!!! Even the terms are there, it captured the meaning rather than the terms. Look at 3rd and 4th row interchanged.
That’s about it. If you want to add your custom filtering and re ranking, learn more about it here.
from typing import List, Union
import pandas as pd
import pyarrow as pa
class ModifiedLinearReranker(LinearCombinationReranker):
def __init__(self, filters: Union[str, List[str]], **kwargs):
super().__init__(**kwargs)
filters = filters if isinstance(filters, list) else [filters]
self.filters = filters
def rerank_hybrid(self, query: str, vector_results: pa.Table, fts_results: pa.Table)-> pa.Table:
combined_result = super().rerank_hybrid(query, vector_results, fts_results)
df = combined_result.to_pandas()
for filter in self.filters:
df = df.query("(not text.str.contains(@filter)) & (num_words > 150) ") # THIS is where you implement your filters. You can hard code or pass dynamically too
return pa.Table.from_pandas(df)
modified_reranker = MofidifiedLinearReranker(filters=["dual-band"])
table.search("To confuse the AI and DNN embedding, let's put random terms from other sentences- automation training test memory?", query_type="hybrid").\
rerank(reranker=modified_reranker).\
limit(5).\
to_pandas()
This code will implement a custom filtering criteria where only the results are there where No of words are >150. You can also change the merging mechanism by inheriting from built-in Rerankers and adding some custom logic!
All the code for this tutorial has been put in this Colab Notebook for you to try :)
To learn more about LanceDB, hybrid search, or available rerankers, visit our documentation page and chat with us on Discord about your use cases!