by Ayush Chaurasia
In this writeup, you’ll learn the process of building a multi-modal search engine using roboflow’s CLIP inference API and LanceDB, serverless vector with native javascript support.
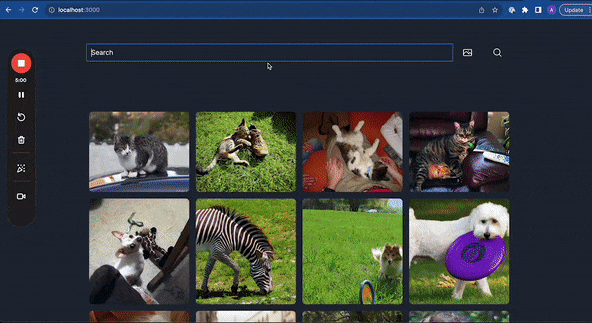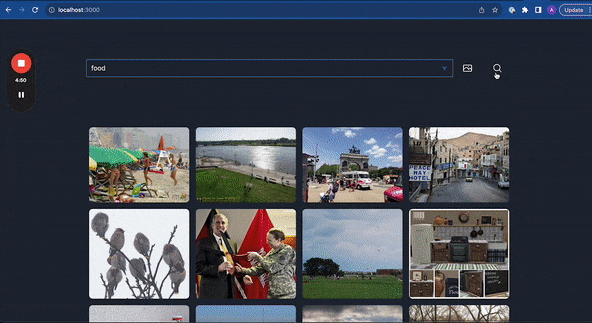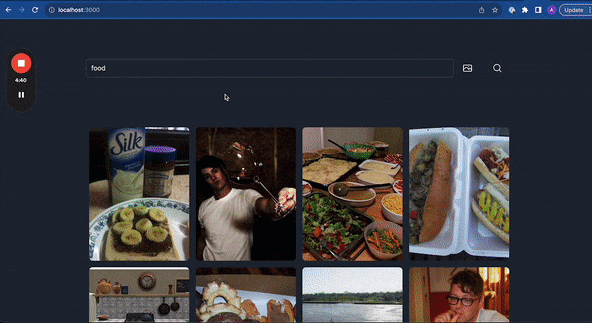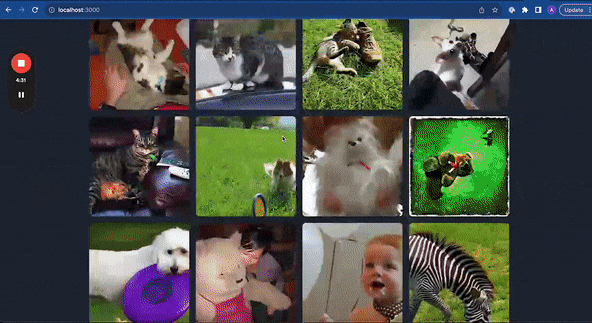
By the end of this, you should be able to build something like this, a search engine that can search images using text or other images
Full implementation can be found here
Let’s get started!
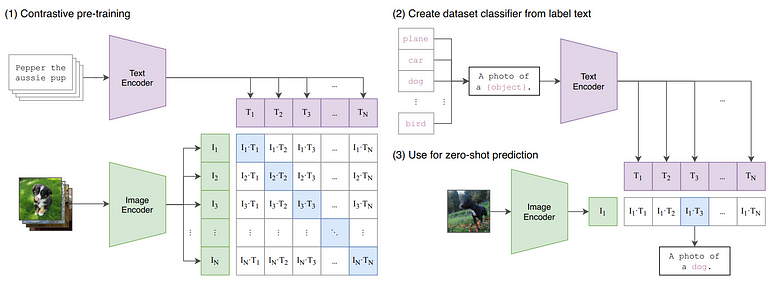
CLIP
CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs. It can be instructed in natural language to predict the most relevant text snippet, given an image, without directly optimizing for the task, similarly to the zero-shot capabilities of GPT-2 and 3
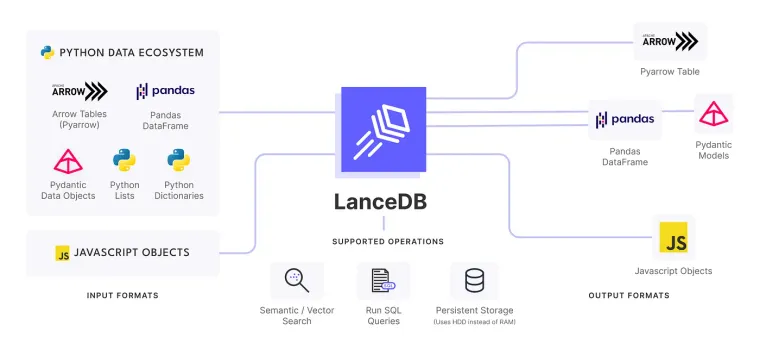
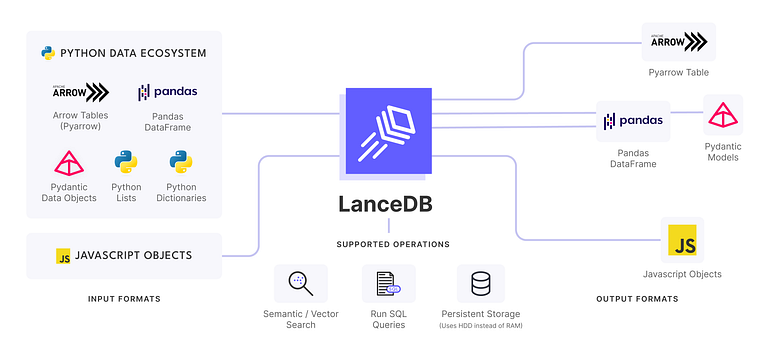
LanceDB: Serverless VectorDB in browser
Let us now set up the vector database. We’ll use nextjs serverless functions.
LanceDB is an open-source database for vector-search built with persistent storage, which greatly simplifies retrieval, filtering and management of embeddings. LanceDB has native support for both python and javascript/Typescript. As this is a web application, we’ll use the node package.
Let us now look at some of the main parts/snippets that do all the heavy lifting.
Get Image embeddings
Roboflow CLIP inference API accepts images as base64 strings. The following snippet is a function that takes the image file as base64 string, runs it through CLIP inference API and returns the embeddings. The API uses axios to process requests
async function embedImage(file: string) {
const response = await axios({
method: "POST",
url: `https://infer.roboflow.com/clip/embed_image`,
params: {
api_key: process.env.RF_API_KEY || "",
},
data: {
clip_version_id: "ViT-B-16",
image: [
{
type: "base64",
value: file,
},
],
},
headers: {
"Content-Type": "application/json",
},
});
return response.data.embeddings[0];
}Get Text embeddings
Similarly, you can also get the text embeddings.
async function embedText(text: string) {
const response = await axios({
method: "POST",
url: "https://infer.roboflow.com/clip/embed_text",
params: {
api_key: process.env.RF_API_KEY || "",
},
data: {
clip_version_id: "ViT-B-16",
text: text,
},
headers: {
"Content-Type": "application/json",
},
});
return response.data.embeddings[0];
}Create LanceDB table
Now we can simply call the above functions as nextjs apis to create LanceDB embeddings table.
async function getImgEmbeddings(img_files: Array<string>, db: any){
for (var i = 0; i < img_files.length; i++) {
const response = await fetch(`${baseUrl}/api/embed`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ data: img_files[i], type: "image" }),
});
const json = await response.json();
embeddings.push(json.embedding);
}
var data = [];
for (var i = 0; i < img_files.length; i++) {
data.push({
img: imgs[i],
vector: embeddings[i],
});
}
await db.createTable("table", data);Searching for similar images
Now that we’ve created the embedding table, let’s see how we can use it to search for similar Images using text or another image. The thing to keep in mind is that the CLIP model is capable of projecting both images and texts in the same embedding space, which is what we’ll utilize here.
export async function retrieveContext(query: Array<number>, table: string) {
const db = await connect(process.env.LANCEDB_URI);
const tbl = await db.openTable(table);
// Search for similar image and get top 25 results
const result = await tbl.search(query).select(["img"]).limit(25).execute();
const imgs = result.map((r) => r.img);
return imgs;
}
That’s pretty much all that is needed to build a multi-modal semantic search engine. We’ve covered the building blocks — Embedding images and text, populating the LanceDB table, and retrieving relevant results.
The full implementation of the Application using nextjs and tailwind can be found here on GitHub.
Learn more about LanceDB or learn more about applied GenAI applications on our vectordb-recipes . Don’t forget to drop us a 🌟!