by Tevin Wang
I believe that there are currently two major challenges using LLMs. (1) outdated information (ChatGPT has limited knowledge of the world and events after 2021) and (2) hallucinations (when LLMs produce incorrect or biased responses that seem confident).
Retrieval augmented generation (RAG) is the key to helping LLMs provide the best and up-to-date results for specific use cases and contexts. It gives LLMs context from a knowledge base by augmenting its prompts, and thus, allows it to retrieve knowledge-grounded information. Such generation technique have been shown to help reduce hallucinations.
With the help of a serverless vector database like LanceDB that has native JS support, we are able to integrate retrieval augmented generation directly in serverless functions on-prem. No api keys for the database needed. This is great for web-based AI applications, like a chatbot agent that works with website sitemaps to retrieve context and provide information about that website.
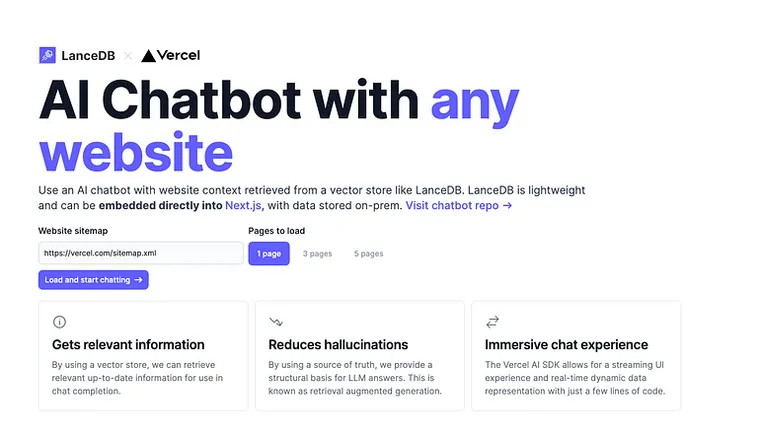
Let’s take a look at how this works in Next.js. The full source code for the website chatbot template can be found in this Github repo. You can also deploy this template to Vercel in one click.
{kind=link}
There are two main functions needed for the chatbot:
- Insertion: We’ll scrape a website sitemap provided through a form input and insert website information into LanceDB.
- Retrieval: With a query from a chat interface, we’ll query LanceDB to augment the LLM prompt with website context, and return the result from the LLM.
Insertion
We start by using a simple form to gather the url for the website sitemap:

We then send a POST request to a serverless function with this information.
const response = await fetch("/api/context", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ url: state.website, pages: state.pages, })
})In the /api/context route, we’ll use Cheerio to get website links from the sitemap, and retrieve the actual text content from the website.
async function getEntriesFromLinks(links: string[]): Promise<Entry[]> {
let allEntries: Entry[] = [];
for (const link of links) {
console.log('Scraping ', link);
try {
const response = await fetch(link);
const $ = load(await response.text());
const contentArray: string[] = [];
$('p').each((index: number, element: Element) => {
contentArray.push($(element).text().trim());
});
const content = contentArray
.join('\n')
.split('\n')
.filter(line => line.length > 0)
.map(line => ({ link: link, text: line }));
allEntries = allEntries.concat(content);
} catch (error) {
console.error(`Error processing ${link}:`, error);
}
}
return allEntries;
}
export async function getDomObjects(url: string, pages: number): Promise<Entry[]> {
const sitemapUrls = await getWebsiteSitemap(url, pages);
const allEntries = await getEntriesFromLinks(sitemapUrls);
return allEntries;
}We save these in the allEntries array to get ready for inserting into LanceDB. Next, we connect to a temporary directory, /tmp/website-lancedb, to actually store our data.
const db = await connect('/tmp/website-lancedb')Before we insert, we should provide expanded context for each text entry. This will help us retrieve more information for each query. For this demo, we’ll merge 5 entries of data together, grouped by each website page.
// Each article line has a small text column, we include previous lines in order to
// have more context information when creating embeddings
function contextualize(rows: Entry[], contextSize: number, groupColumn: string): EntryWithContext[] {
const grouped: { [key: string]: any } = []
rows.forEach(row => {
if (!grouped[row[groupColumn]]) {
grouped[row[groupColumn]] = []
}
grouped[row[groupColumn]].push(row)
})
const data: EntryWithContext[] = []
Object.keys(grouped).forEach(key => {
for (let i = 0; i < grouped[key].length; i++) {
const start = i - contextSize > 0 ? i - contextSize : 0
grouped[key][i].context = grouped[key].slice(start, i + 1).map((r: Entry) => r.text).join(' ')
}
data.push(...grouped[key])
})
return data
}To actually create vector embeddings from the website text, we’ll use OpenAI’s text-embedding-ada-002 embedding model. An OPENAI_API_KEY must be added as an environment variable.
// The embedding function will create embeddings for the 'context' column
const embedFunction = new OpenAIEmbeddingFunction('context', apiKey)Finally, we’ll batch insert our text entries into a Table, which is the primary abstraction you’ll use to work with your data in LanceDB. A Table is designed to store large numbers of columns and huge quantities of data. For those interested, a LanceDB is columnar-based and uses Lance, an open data format to store data.
const tbl = await db.createTable(`website-${hash}`, data.slice(0, Math.min(batchSize, data.length)), embedFunction)
for (var i = batchSize; i < data.length; i += batchSize) {
await tbl.add(data.slice(i, Math.min(i + batchSize, data.length)))
}Retrieval
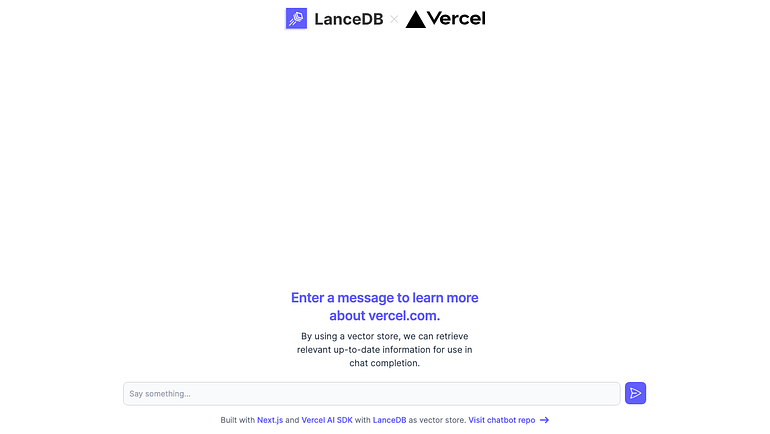
We start with a chat interface provided by the Vercel AI SDK, which allows for a streaming UI experience for chat models. You can test out the Vercel AI SDK at https://sdk.vercel.ai.

Here is LanceDB’s chat page that appears after insertion is finished.
Once a text query is recieved, we send a request to /api/chat with the following router, which uses the Edge runtime.
import { OpenAIStream, StreamingTextResponse } from 'ai'
import { Configuration, OpenAIApi } from 'openai-edge'
import { createPrompt } from './prompt'
// Create an OpenAI API client (that's edge friendly!)
const config = new Configuration({
apiKey: process.env.OPENAI_API_KEY
})
const openai = new OpenAIApi(config)
// IMPORTANT! Set the runtime to edge
export const runtime = 'edge'
export async function POST(req: Request) {
// Extract the `messages` from the body of the request
const { messages, table } = await req.json()
const baseUrl = process.env.VERCEL_URL ? 'https://' + process.env.VERCEL_URL : 'http://localhost:3000'
const context = await fetch(`${baseUrl}/api/retrieve`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ query: messages[messages.length - 1].content, table })
})
messages[messages.length - 1].content = createPrompt(messages[messages.length - 1].content, (await context.json()) as EntryWithContext[])
// Ask OpenAI for a streaming chat completion given the prompt
const response = await openai.createChatCompletion({
model: 'gpt-3.5-turbo',
stream: true,
messages
})
// Convert the response into a friendly text-stream
const stream = OpenAIStream(response)
// Respond with the stream
return new StreamingTextResponse(stream)
}This first calls /api/retrieve to get context from LanceDB. We make a search query on the table generated from insertion, utilizing the same OpenAI embedding model, returning the results.
const embedFunction = new OpenAIEmbeddingFunction('context', apiKey)
const tbl = await db.openTable(table, embedFunction)
console.log('Query: ', query)
return await tbl
.search(query)
.select(['link', 'text', 'context'])
.limit(3)
.execute()
}Then, we utilize these results to create and augment our prompt.
messages[messages.length - 1].content = createPrompt(messages[messages.length - 1].content, (await context.json()) as EntryWithContext[])
export function createPrompt(query: string, context: EntryWithContext[]) {
let prompt =
'The context that follows is pulled from a website. Respond based on the website information below, acting as an agent guiding someone through the website.\n\n' +
'Context:\n'
// need to make sure our prompt is not larger than max size
prompt = prompt + context.map(c => c.context).join('\n\n---\n\n').substring(0, 3750)
prompt = prompt + `\n\nQuestion: ${query}\nAnswer:`
return prompt
}Finally, we ask for chat completion from OpenAI.
// Ask OpenAI for a streaming chat completion given the prompt
const response = await openai.createChatCompletion({
model: 'gpt-3.5-turbo',
stream: true,
messages
})
// Convert the response into a friendly text-stream
const stream = OpenAIStream(response)
// Respond with the stream
return new StreamingTextResponse(stream)And here are the results of the query Tell me about Vercel.
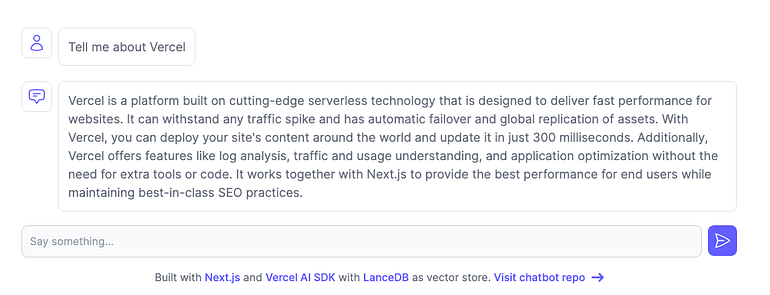
Summary
- Retrieval augmented generation (RAG) is a great way to provide LLMs relevant context from a knowledge base.
- We need a good vector database solution that provides RAG on the web, as many AI and LLM-related applications are hosted on the web.
- LanceDB is a serverless vector database that is up for the task. It is easy-to-use and free, as it can be embedded directly into a serverless function, with data stored on-prem.
- With Vercel AI SDK and LanceDB, we can create some cool Next.js web apps that utilize RAG, such as a LLM-based website chatbot.
Thanks for reading! If you have questions, feedback, or want help using LanceDB in your app, don’t hesitate to drop us a line at contact@lancedb.com. And we’d really appreciate your support in the form of a Github Star on our LanceDB repo ⭐.