
A (near) perfect match
A spiritual successor to pandas, Polars is a new blazing fast DataFrame library for Python written in Rust. At LanceDB, we hear from many of our users that they process data using Polars before inserting it into LanceDB and converting search results into Polars data frames for downstream processing. To make things easier for them, we decided to add a direct integration with Polars. Now LanceDB can ingest Polars dataframes, return results as polars dataframes, and export the entire table as a polars lazyframe. And a quick acknowledgment, this integration was made possible by the great work of Ritchie and Kyle supporting FixedSizeList, which makes storing and working with embeddings way easier.
LanceDB, as of v0.4.5, can ingest Polars DataFrames, return results as Polars DataFrames,, and export the entire table as a Polars LazyFrame.
A Simple Walkthrough
Let’s walk through a simple example of how the LanceDB-polars integration works. If you just want to see all of the code together, please see this colab notebook for details.
🐻❄️ Read raw data into Polars
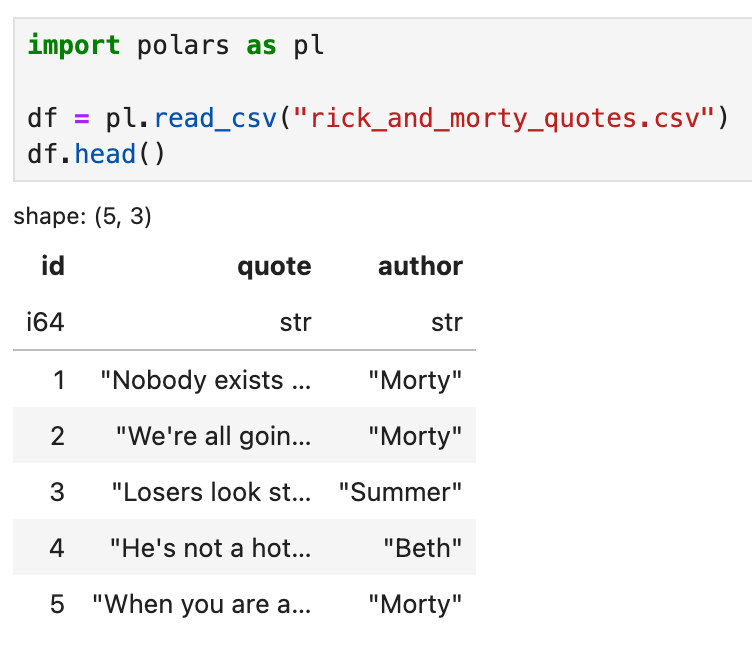
For this walkthrough, we’ll be retrieving Rick and Morty quotes to answer user questions. Let’s start with reading the raw data in CSV format using polars:
🤗 Setup embedding model
Next, we’re going to set up a LanceDB table for retrieval. For this table, we’ll use the sentence-transformers model from HuggingFace. It is integrated as one of the default embedding models in LanceDB. To keep the installation footprint small, HuggingFace is an optional dependency for LanceDB, so if you’re starting from a fresh environment, you’ll want to first run pip install -U sentence-transformers.

You can refer to other API’s or pretrained embedding models by name like “openai”, “cohere”, “openclip”, and more. You can see all of the available functions here, or you can extend it with your own.
💾 Ingest Polars into LanceDB
Next, we’re ready to create a LanceDB table for semantic search. We can use pydantic to make creating the table schema easier by creating a LanceModel (subclass of pydantic.BaseModel). As you can see below, the table schema matches the polars dataframe schema, with the exception of an additional vector column. The embedding function we created can be configured to automatically create the vectors at ingestion time. We’re using pydantic annotations to indicate that quote is the source column for embeddings and vector is to be generated from the source column using the sentence-transformers model we set up.

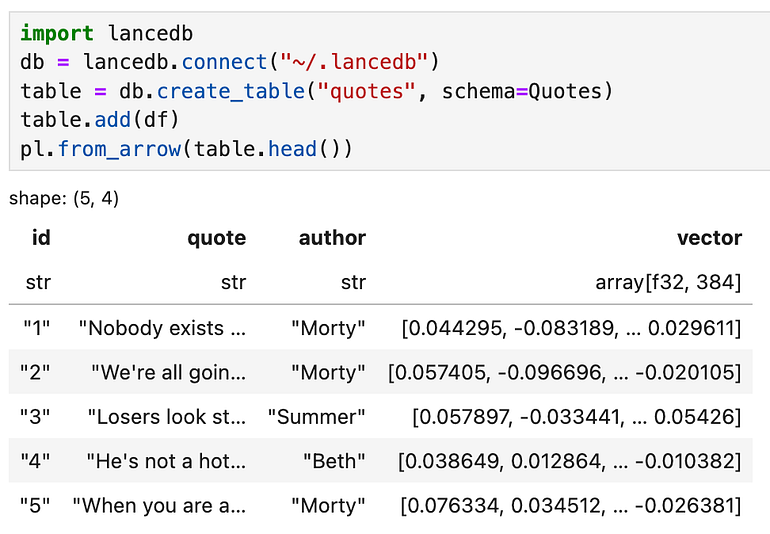
Now we can put it together. We’ll create the table under the ~/.lancedb directory. We then use the Quotes pydantic model to create the table by using the schema parameter. And finally, we add the polars dataframe df to the LanceDB table. Note that the embedding generation is handled automatically by LanceDB.
🔎 Querying the table
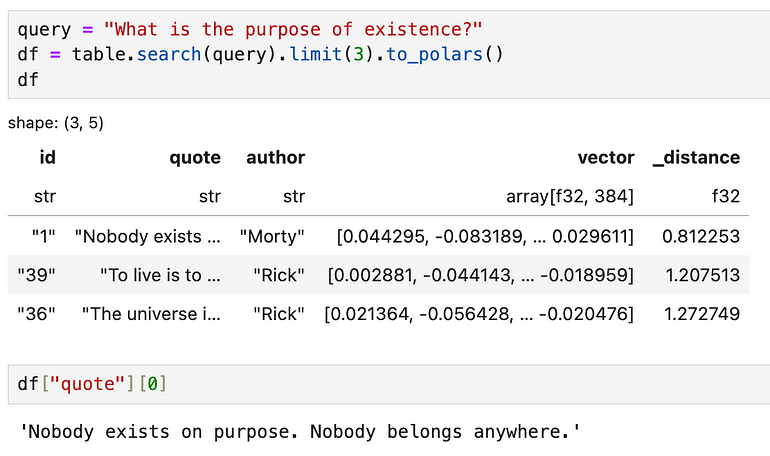
Now we can ask Rick and Morty some really deep philosophical questions, like “What is the purpose of existence?”, and we can export the results as a polars dataframe. As you would expect, the top answer seems to be that “Nobody exists on purpose”.
🕺🏻Reading the whole table into Polars
As you iterate on your application, you’ll likely need to work with the whole table’s data pretty frequently. LanceDB tables can also be converted directly into a polars LazyFrame . The reason why we don’t convert it to a DataFrame is because LanceDB tables can potentially be very large, like way bigger than memory, and LazyFrames allows us to work with large datasets easily.
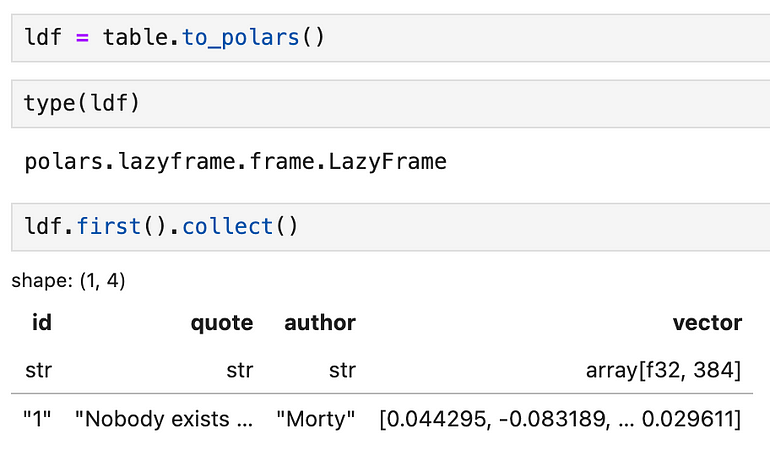
Of course, if you know your table will fit into memory, it’s pretty easy to do lancedb_table.to_polars().collect() to turn the LazyFrame into a DataFrame.
Room for Improvement
LanceDB and polars work really well with each other, but there are many places where the user experience can be improved even more.
💡 Batch ingestion of LazyFrame
Currently, you can ingest a DataFrame but not a LazyFrame. And if you try to pass in a LazyFrame anyway, you’ll get a TypeError:

This means that if you have a large dataset, you’ll have to manually read data in batches. The reason for this is that polars does not have an API to iterate over batches of a LazyFrame.
polars does not have an API to iterate over batches of a LazyFrame
💡 Filter pushdowns
We use the scan_pyarrow_dataset to convert to LazyFrame. Polars is able to push-down some filters to a pyarrow dataset, but the pyarrow dataset expects pyarrow compute expressions while Lance expects SQL strings. This means that we’ve had to disable the filter push-downs, meaning that Polars won’t be able to take advantage of the fast filtering and indexing features of Lance.
It would be great if Polars can push-down filters to LanceDB as SQL string instead of compute expression
And just musing on the long-term future of integrations between libraries that can pass off computation subtasks to each other, it would be great to coalesce around a standard like Substrait. Like how Arrow has become the standard for the exchange of in-memory data, Substrait can become the standard for the exchange of computational IR.
💡 Native Lance reader + UDFs
Currently, the interface between Lance and polars is the scan_pyarrow_dataset function in polars, which means it needs to be compatible with the generic pyarrow dataset interface. If there was a direct integration for Lance, we could build a udf and allow polars to push-down vector search directly. A sample API could look like:
ldf = pl.scan_lance("~/.lancedb/really_large_table.lance")
df = ldf.search("A natural language query").limit(10).collect()
💡 Integration at the Rust level
So far, the integration between LanceDB and Polars happens at the Python level, but I think there’s an opportunity to push the integration down to Rust. This can then enable a cross-language integration, for example, polars-nodejs + lancedb nodejs, which is an ecosystem that’s becoming a lot more important for AI.
Conclusion
I think 2024 will be the year of Rust 🦀 for data infrastructure. There’s a plethora of opportunities for Rust-based projects to integrate and create a rich ecosystem of data tooling for data eng, ML, and AI. If you use polars today, setting up a RAG application just became a little easier. And if you’re interested in working on Rust and open-source, we’re hiring (contact@lancedb.com)!