by Ayush Chaurasia
In the rapidly evolving landscape of artificial intelligence, Generative AI, especially Language Model Machines (LLMs) have emerged as the veritable backbone of numerous applications, from natural language processing and machine translation to virtual assistants and content generation. The advent of GPT-3 and its successors marked a significant milestone in AI development, ushering in an era where machines could not only understand but also generate human-like text with astonishing proficiency. However, beneath the surface of this AI revolution lies a crucial missing element, one that has the potential to unlock even greater AI capabilities: the storage layer.
The objective truths about LLMs
Let’s set the context with an LLM refresher. Here are some of the highlights with what has happened in the last couple years.
LLMs are most advanced AI systems ever built
LLMs and the derivative works have the potential to revolutionise many industries and fields of research. For example, they can be used to create more natural and engaging user interfaces, develop new educational tools, and improve the accuracy of machine translation. They can also be used to generate new ideas and insights, and to create new forms of art and literature which opens up a new direction in the field of language and linguistics.
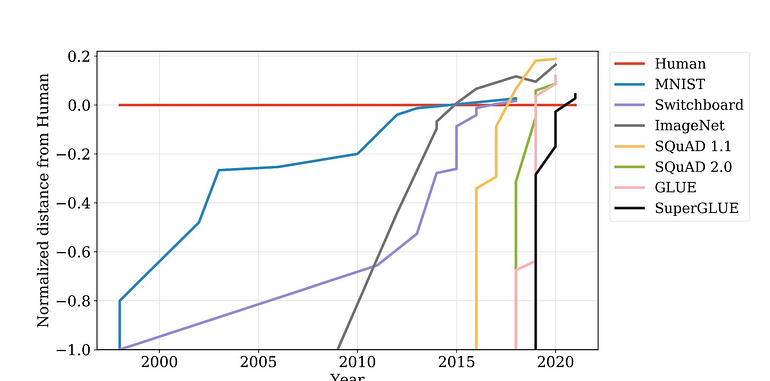
These models have crushed human levels on benchmarks faster than ever seen before:
These systems lie confidently
Although LLMs are highly advanced and in most cases it is almost impossible to distinguish a generated text from human response, these systems suffer from various levels of hallucination. Another way to put this would be that these systems lie confidently, and because of human level proficiency in generation, these lies are pretty convincing.
Consider this interaction with ChatGPT

At a glance, these results seem impressive but once you follow the links, they all lead to 404s. This is dangerous on various levels:
- First, because these links look convincing, one might just take them for citations without checking
- The best case scenario would be that you check the first link and on realising it lead to 404, you’ll check the other ones as well.
- But the worst case would be if only the first link actually exists and you only check that. It would lead you to believe all links are valid
This just one example of hallucination, there are many others that are subtler, like simply making things up.
The most powerful LLMs continue to be a black box
Personally I don’t like the term “black box” thrown at all of deep learning because most of these models can be easily dissected and modified. In fact, in most cases the modified versions of originally published models have been more popular and useful. Interpretability has historically been challenging but that is not enough to call these models black boxes. But this is different for LLMs. The most powerful LLMs are closed source and are only accessible via API requests. Additionally, due to the high cost of training and proprietary datasets, there aren’t enough resources or engineering expertise to reproduce the result. These do fit the definition of a black box.
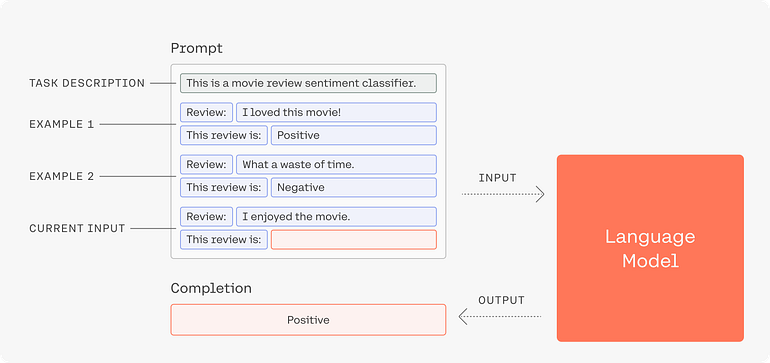
Response Vs Representation based systems
In prompt based approach, you rely on LLMs to generate responses directly from your (or your users’) queries. Using LLMs to generate responses if pretty powerful, and simple to get started with. But it gets scary soon enough when you realise that you don’t(can’t) control any aspect of the lifecycle of these systems. Combined with objective truths discussed above, this can soon become a recipe for disaster.
Using LLMs for representation
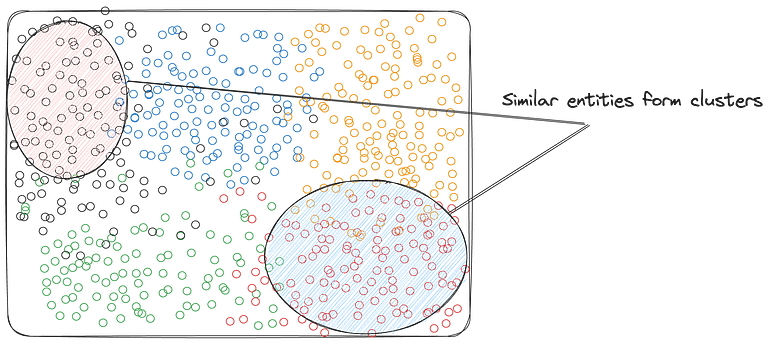
How about instead of using LLMs end-to-end, we simply use it to represent our knowledge base? The obvious way to do that would be to embed our database using these powerful models. You can have a numerical representation of your unstructured data that captures semantic meaning.

These vectors capture the relationship between entities in a high dimensional space. For example, here’s an example word embeddings where similar words in meaning are close by.
Retrieval Augmented Generation(RAG)
We have all the pieces needed to build a RAG system. In a RAG setting, instead of using LLMs to generate responses from the prompts, we retrieve relevant representations using a retriever and sew them together by prompting the LLM to form the response.
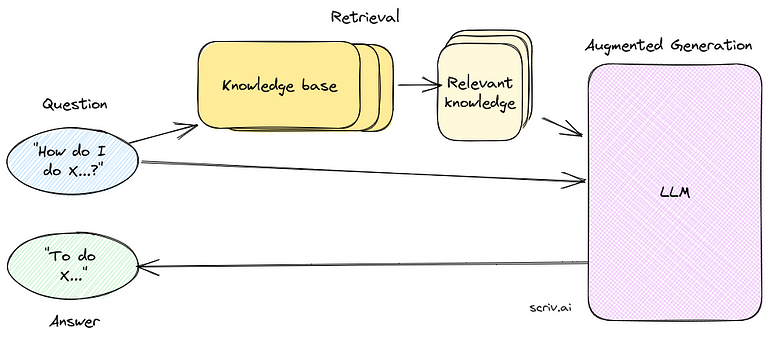
Now, you can provide exact citations from the knowledge base documents that were used to generate the response. It becomes possible to trace back response to its source
A change in domain
What we’ve accomplished so far with RAG is that we’ve reduced reliance on LLM to answer on our behalf. Instead, we now have a modular system that has different parts, each of which operates independently:
- Knowledge base
- Embedding model
- Retriever
- Response generator (LLM)
This causes a change in domain, where we go from relying blackbox AI to modular components backed by decades of research
“It’s AI as long as it doesn’t work well, it’s computer science when it starts working”
This quote has stuck with me ever since I head it almost a decade ago. I think it’s by Eric Schmidt, but I wasn’t able to find that exact lecture.
The general idea is that now we’ve changed the domain of the problem in way that the retriever becomes the centre piece of the system and we can now utilise the research work in CS sub-domains such as information retrieval, ranking, etc.
Sounds like I need to spend $$$ ?
Costs depend on a lot of factors. Let us now shift our attention to common problems a deployed ML system faces and how this approach to generative AI aims to solve them.
- Interpretability — There isn’t a way to confidently interpret deep neural nets, but this is an active area of research. It is even more difficult to interpret LLMs. But in a RAG setting, you build response in stages allowing insights to the cause of a decision.
- Modularity — There are a lot of advantages to a system that’s modular when compared to an end-to-end API accessible model. In our case, we have a granular control on what goes into our knowledge base and how it is updated over time, the configuration of our retriever and ranking algorithms, and what models we feed this information to generate final responses.
- (Re) Training Cost — The biggest problem with LLMs (including local models) is the massive data and infra requirements. This makes almost unfeasible to re-train them as new data comes in.
For example, let us consider an example of a recent event that that occurs after the training finishes (or more specifically dataset creation date cutoff). Here are some questions related to events that occurred a few days ago to some that occurred a few months ago, asked to ChatGPT.


The rate of change of information in a sub-domain of business for which an LLM is fine tuned could be much higher, making these models out of date very quickly.
If the same system relied on RAG system, it would simply need to update the knowledge base, i.e, run the new events/information through the embedding model and the rest would be handled by the retriever. On the other hand, the LLM would require retraining on new data in a direct response based system.
So it turns out this methods not only provides you finer control and modularity, but is also much cheaper to update as new information comes in.
Finetuning Vs RAG
The debate on what’s better between fine-tuning a model on domain specific data and using a general model with for RAG is pointless. Of course ideally, you want both. A fine-tuned model with better context of the domain will provide better “general” response with contexual vocabulary. But you need a RAG model for better control & interpretability of the responses.
The need for the AI native Database
At this point it is pretty clear that there is a need for well maintained knowledge base. Although there are many traditional solutions, we need to rethink those for AI solutions. Here are the main requirements:
- AI needs a LOT of Data
- Models are becoming multi-modal. Data needs to follow
- Scaling shouldn’t break the bank.
Multi-modality is the next frontier and most LLM providers have either planned to support multi-modal features or they’re already testing them.
of these while keeping in mind that we don’t need invent yet another sub-domain in ML. So leveraging existing tools and interface would be ideal.
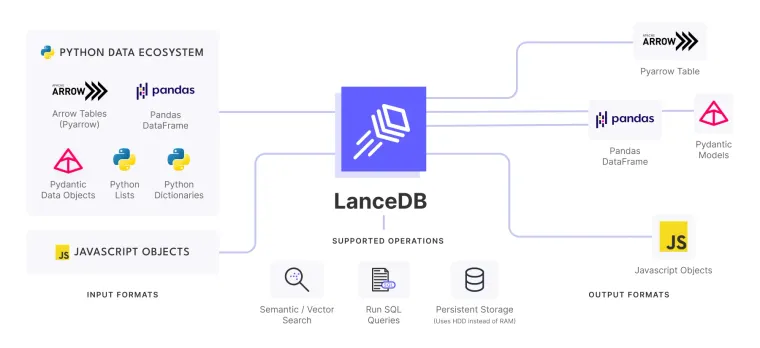
LanceDB: the AI Native, multi-modal, & embedded vector Database
LanceDB is an open-source database for vector-search built with persistent storage, which greatly simplifies retrieval, filtering and management of embeddings.
np.array — The OG vectorDB
There is an ongoing debate about the need for vectorDB and if np.array is all you need for all vector search operations.
Let’s take a look at an example of using np.array for storing vectors and finding similar vectors
import numpy as np
import pandas as pd
embeddings = []
ids = []
for i, item in enumerate(data):
embeddings.append(embedding_model(item))
ids.append(i)
df = pd.DataFrame({"id": ids, "embedding": embeddings})
df.to_pickle("./dummy.pkl")
...
df = pd.read_pickle("./dummy.pkl")
embeddings, ids = df["embedding"].to_numpy(), df["id"]
sim = cosine_sim(embeddings[0], embeddings[1])
...
This is great for rapid-prototyping but how does this scale to millions of entries? What about billions? Is loading all the embeddings in memory efficient at scale? What about multimodal data?
The ideal solution for AI-native vectorDB would be something that would would be easy to set up and should integrate with existing APIs for rapid prototyping but should be able to scale without additional changes.
LanceDB is designed with this approach. Being server-less, it requires no setup — just import and start using. Persisted in HDD, allowing compute-storage separation so you can run operations without loading the entire dataset in memory. Native integration with Python and Javascript ecosystems , allowing to scale from prototype to production applications from the same codebase.
Compute Storage Separation
Compute-storage separation is a design pattern that decouples the compute and storage resources in a system. This means that the compute resources are not located on the same physical hardware as the storage resources. There are several benefits to compute-storage separation, including scalability, performance, and cost-effectiveness.
LanceDB — The embedded VectorDB
Here’s how you can integrate the above example with LanceDB
db = lancedb.connect("db")
embeddings = []
ids = []
for i, item in enumerate(data):
embeddings.append(embedding_model(item))
ids.append(i)
df = pd.DataFrame({"id": ids, "embedding": embeddings})
tbl = db.create_table("tbl", data=df)
...
tbl = db.open_table("tbl")
sim = tbl.search(embedding_model(data)).metric("cosine").to_pandas()That’s all you need to do to supercharge your vector embeddings workflow for any scale. LanceDB is built on top of Lance file format which is modern columnar data format for ML and LLMs implemented in Rust
We’ve created on some benchmarks that provide approximate measure of performance of lance format — achieving up to 2000x better performance with Lance over Parquet
In the upcoming blog, we’ll discuss how does LanceDB works with more technical details about lance file format, lanceDB & our vision to build the storage layer for AI.
Visit about LanceDB or vectordb-recipes and Drop us a 🌟