by Leon Yee
Introduction
Just a few days ago, I went to Anthropic’s Hackathon, where hackers utilized their Claude 2 APIs to build some amazing programs and projects. My team and I got together to build an automatic GitHub bot, drcode, that scours a repository and suggests code optimization and readability changes — effectively doubling your productivity and cleaning up your codebase.
However, I’m not here to showcase our hackathon project; I’m excited to delve deeper into the fascinating ways to utilize these technologies.
Currently, large language models (LLMs) have a limited context window, requiring a sacrifice of important material in order to make room for context. In these kinds of situations, dynamic context retrieval can be difficult, because of how little you can input. But in the war between retrieval augmented generation and context windows, why don’t we choose both? Claude and LanceDB allow us to do just this, retrieving relevant information from embedded vector stores, and providing this context into Claude’s 100k token context window. In our case, we fetched parts of the documentation for each line in the codebase to fill up this large context window.
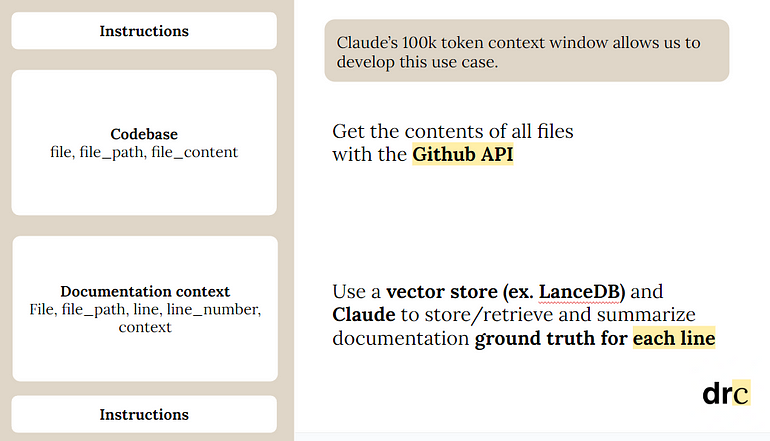
A breakdown
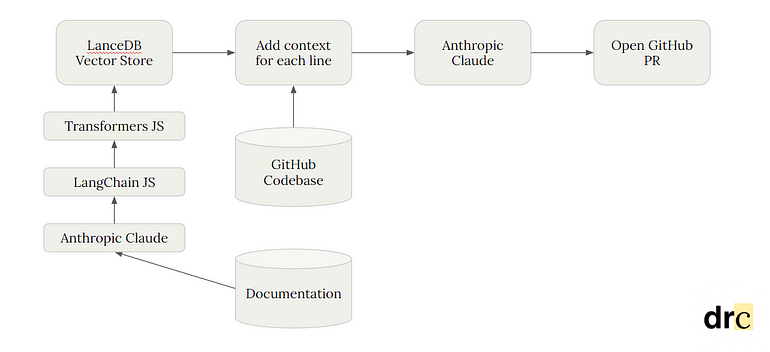
As an example, I’ll take the program that we worked on during Anthropic’s Hackathon. This is the workflow of how it operates:
- drcode first downloads all the documentation of a certain programming language, and passes it through Claude to summarize each of the files. For our project, we only downloaded the Python documentation.
- We then pass all the data that Claude outputs into LangChain, a framework for developing LLM applications, utilizing one of LangChain’s functions to recursively split the data by character. This basically just means that it tries to split chunks of text until it’s a small enough chunk size.
- Then, we use a sentence transformer called Transformers.js, from HuggingFace. This function just embeds all the text into a 384-dimensional vector space. LanceDB accepts an embedding function along with the data, automatically embedding all the data we input into the vector table.
- Next, we scrape all the code from your GitHub repository and query the LanceDB table for context. What we did was for every 3rd line, we query the table with those lines to pull the most relevant Python documentation.
- Finally, we craft a large prompt asking Claude to output a unified diff XML file, given all the information we gathered. This file is then passed into GitHub to generate a pull request.
The example
Let’s take a look at an example of how it works. We’ll first go through gathering the documentation and embedding the text. Keep in mind that the code is just a general outline and that our team worked in both Python and JavaScript.
First, we download the documentation and load the Anthropic Claude API.
import Anthropic from '@anthropic-ai/sdk'
const anthropic = new Anthropic({
apiKey: process.env.CLAUDE_API,
});
import { download } from '@guoyunhe/downloader';
await download("https://docs.python.org/3/archives/python-3.11.4-docs-text.zip", "data/", { extract: true })Now, for every file in the folders and subfolders, we want to input it into Claude for summarization. This can take quite a while and can be intensive on API usage.
// Iterate docPath through every folder.
var output = fs.readFileSync(docPath).toString();
const prompt = `\n\n${Anthropic.HUMAN_PROMPT}: You are to act as a summarizer bot whose task is to read the following code documentation about a python function and summarize it in a few paragraphs without bullet points.
You should include what the function does and potentially a few examples on how to use it, in multiple paragraphs, but leave out any unrelated information that is not about the functionality of it in python, including a preface to the response,
such as 'Here is a summary...'. \n\nREMEMBER: \nDo NOT begin your response with an introduction. \nMake sure your entire response can fit in a research paper. \nDo not use bullet points. \nKeep responses in paragraph form. \nDo not respond with extra context or your introduction to the reponse.
\n\nNow act like the summarizer bot, and follow all instructions. Do not add any additional context or introduction in your response. Here is the documentation file:
\n${output}\n\n${Anthropic.AI_PROMPT}:`
let completion = await anthropic.completions.create({
model: 'claude-2',
max_tokens_to_sample: 100000,
prompt: prompt,
});
completion = completion.completion.split(":\n\n").slice(1);
completion = completion.join(":\n\n");
docs = docs.concat(completion); //docs will contain all information.With all of the documentation now read and summarized, we can go ahead and use LangChain to split the texts, and then format it to be inserted into LanceDB.
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 250,
chunkOverlap: 50,
});
docs = await splitter.createDocuments(docs);
let data = [];
for (let doc of docs) {
data.push({text: doc['pageContent'], metadata: JSON.stringify(doc['metadata'])});
}We’re almost ready to insert the data! All we have to do now is to create an embedding function using TransformersJS.
const { pipeline } = await import('@xenova/transformers')
const pipe = await pipeline('feature-extraction', 'Xenova/all-MiniLM-L6-v2');
const embed_fun = {}
embed_fun.sourceColumn = 'text'
embed_fun.embed = async function (batch) {
let result = []
for (let text of batch) {
const res = await pipe(text, { pooling: 'mean', normalize: true })
result.push(Array.from(res['data']))
}
return (result)
};Then, we can create our table including the embedding function. The benefit of using LanceDB is that it stores everything locally, so inserting and retrieving takes a really short amount of time.
const lancedb = await import("vectordb");
const db = await lancedb.connect("data/sample-lancedb")
const table = await db.createTable("python_docs", data, embed_fun, { writeMode: WriteMode.Overwrite });Great! Moving on, we’ll have to extract all the code from a GitHub repository. We can do this by using GitHub’s API and a Personal Access Token to gather the content, but I won’t show it here. If you want to take a look at how we did it, here is the GitHub file.
We now need to embed the query, AKA the lines of the files. By iterating through the repository files we just scraped, we can pass it back into LanceDB, like this:
const db = await lancedb.connect("data/sample-lancedb")
const table = await db.openTable("python_docs", embed_fun);
let input = "FILE LINES INPUT HERE";
let result = await table.search(input).select(['text']).limit(1).execute();
console.log(result);The piece of code above is going to call the table.search function on the input, select the specific text column, and output a single text response: the context.
Joining everything together, (the file contents, split lines, and line context), into a single file would look something like this (Python):
# python_files is now [(FILE_PATH, [FILE LINES], [(LINE NUMBER, LINE, CONTEXT)])]
with open("python_files.txt", "w", encoding="utf-8") as f:
f.write('<files>\n')
for file_path, file_content, file_context in python_files:
f.write(f"<file>\n<file_path>{file_path}</file_path>\n<file_content>\n{file_content}\n</file_content>\n<file_context>\n")
for context in file_context:
f.write(f"<line>\n<line_number>{context[0]}</line_number>\n<line_content>{context[1]}</line_content>\n<context>\n{context[2]}</context>\n</line>\n")
f.write("</file_context>\n</file>\n")
f.write('</files>')# LOOKS LIKE
# <files>
# <file>
# <file_path>path/to/file.py</file_path>
# <file_content>
# import os, subprocess
# etc
# etc
# </file_content>
# <file_context>
# <line>
# <line_number>1</line_number>
# <line_content>import os, subprocess</line_content>
# <context>
# import os, subprocess
# context here
# </context>
# </line>
# <line>
# <line_number>2</line_number>
# etc
# etc
# </line>
# </file_context>
# </file>
# <file>
# etc
# etc
# </file>
# </files>Finally, our last step is to input our python_files.txt back into Claude, with all of its instructions. Because of its 100k context window, we can stack a lot of information into the prompt, including exactly what we want to be outputted.
# {python_files} is read from the file `python_files.txt`
prompt = f"""{HUMAN_PROMPT}
Description:
In this prompt, you are given a open source codebase that requires thorough cleanup, additional comments, and the implementation of documentation tests (doc tests). Your task is to enhance the readability, maintainability, and understanding of the codebase through comments and clear documentation. Additionally, you will implement doc tests to ensure the accuracy of the documentation while also verifying the code's functionality.
Tasks:
Codebase Cleanup:
Identify and remove any redundant or unused code.
Refactor any convoluted or confusing sections to improve clarity.
Comments and Documentation:
Add inline comments to explain complex algorithms, logic, or code blocks.
Document the purpose, input, output, and usage of functions and methods.
Describe the role of key variables and data structures used in the code.
Doc Tests Implementation:
Identify critical functions or methods that require doc tests.
Write doc tests that demonstrate the expected behavior and output of the functions.
Ensure the doc tests cover various scenarios and edge cases.
Function and Variable Naming:
Review function and variable names for clarity and consistency.
Rename functions and variables if needed to improve readability.
Readme File Update (Optional):
Update the README file with a summary of the codebase and its purpose.
Provide clear instructions for running the code and any dependencies required.
Note:
The codebase provided may lack sufficient comments and documentation.
Focus on making the code easier to understand for others who read it in the future.
Prioritize clarity and conciseness when writing comments and documentation.
Implement doc tests using appropriate testing frameworks or methods.
Ensure that the doc tests cover various scenarios to validate the code's correctness.
This prompt allows the LLM to work on improving codebase quality through comments and documentation while also implementing doc tests for verification. Cleaning up and enhancing codebases in this way is a crucial skill for any developer, as it facilitates teamwork, code maintenance, and future development efforts.Claude, I'm seeking your expertise in adding comments and doc tests to Python code files.:
Provide the updated code in a xml structure where your entire response is parseable by xml:
<root>
<diff>
<!--Ensure the diff follows the unified diff format that would be returned by python difflib, providing clear context and line-by-line changes for ALL files.
Give line numbers with the first line of the file content being line 1,
ONLY CHANGE LINES OF FILE CONTENT (NOT ANY OF THE XML TAGS). Do this for all files.
Add the entire thing as a cdata section '<![CDATA['
This is what it is supposed to look like per file:
--- a/path/to/file.txt (make sure to include the 'a/' in the path, and exactly 3 +s)
+++ b/path/to/file.txt (make sure to include the 'b/' in the path, and exactly 3 -s)
@@ -1,4 +1,4 @@ (ANYTHING after the @@ MUST BE ON A NEW LINE)
This is the original content.s
-Some lines have been removed.
+Some lines have been added.
More content here.
Remove this comment and add the diff patch contents in the diff tag directly. DO NOT ADD THIS IN THE COMMENT
-->
</diff>
[NO MORE DIFF SYNTAX AFTER THE DIFF TAG]
<title>
<!-- Relevant emoji + Include a github pull request title for your changes -->
</title>
<changes>
<!-- Include details of the changes made in github BULLET POINTS, not xml, with some relevant emojis -->
</changes>
</root>
Your focus should be on pythonic principles, clean coding practices, grammar, efficiency, and optimization. Do not change the file if you don't know what to do.
Before you make a change, evaluate the following:
- The code must work and stay valid
- The code doesn't add any duplicate code that isn't necessary
- The code has the right indentation for python
- The code works
If one of these is not valid, do not add the change.
Reminder to add the entire diff as a cdata section '<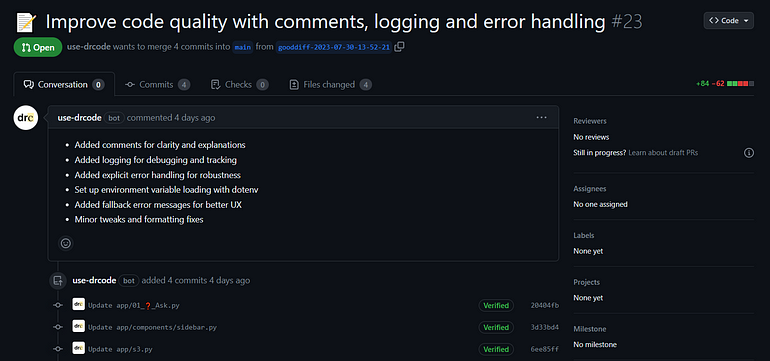
Conclusion
I hope that this implementation of these technologies has been insightful for you! I believe that combining retrieval augmented generation and large context windows can lead to substantial leaps in the field of natural language processing. Of course, LLMs still have a long way to go before they can fully emulate human-like comprehension, so not everything will be fully accurate. But using vector databases to fetch context, such as LanceDB, and a large context window LLM, such as Claude, can definitely unlock new possibilities in all sorts of domains.
Thank you for reading! If you would like to check out our full code, here it is on GitHub. We’d really appreciate you leaving a ⭐ on our LanceDB repo.