By Kaushal Choudhary
In this blog, we’ll cover InstructOR embedding model and how it can be used with LanceBD. LanceDB embedding API already supports this model so we can simply use it from the registry.
Link to the code. Follow along with this Colab Notebook.
Embeddings Recap
Text embedding is a piece of text projected into a high-dimensional latent space. The position of our text in this space is a vector, a long sequence of numbers. Think of the two-dimensional Cartesian coordinates from algebra class, but with more dimensions — often 768 or 1536.
For example, here’s what the OpenAI text-embedding-ada-002 model does with the paragraph above. Each vertical band in this plot represents a value in one of the embedding space’s 1536 dimensions.
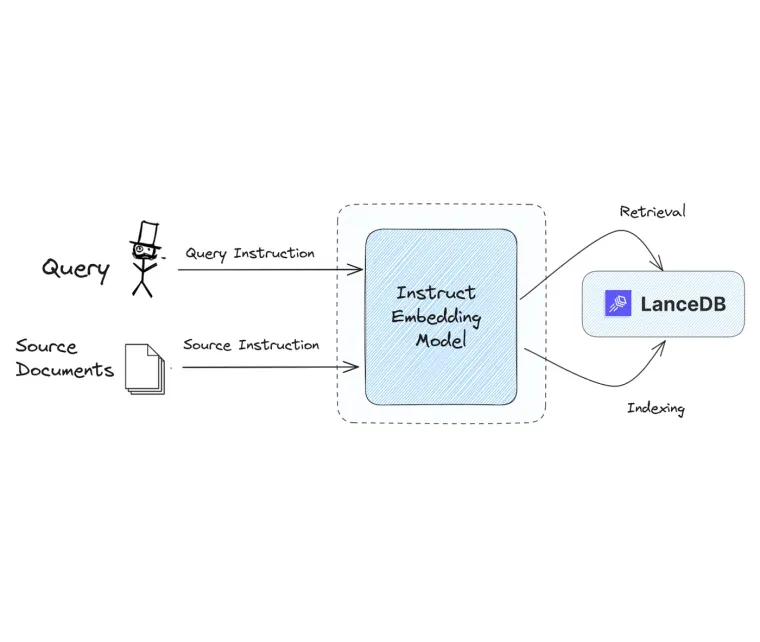
What is InstructOR embedding model, and how is it different from the otherwise vanilla embedding model?
The InstructOR multitask embedding model, is an embedding method which computes custom embedding for the particular text based on the instruction(s) provided.
Let’s look at some examples
Instruction : Represent the Science Title
# prepare texts with instructions
text_instruction_pairs = [
{"instruction": "Represent the Science title:", "text": "3D ActionSLAM: wearable person tracking in multi-floor environments"}
]
# calculate embeddings
customized_embeddings = model.encode(texts_with_instructions)Instruction : Represent the Medicine sentence for clustering
import sklearn.cluster
sentences = [['Represent the Medicine sentence for clustering: ','Dynamical Scalar Degree of Freedom in Horava-Lifshitz Gravity']]
embeddings = model.encode(sentences)
clustering_model = sklearn.cluster.MiniBatchKMeans(n_clusters=2)
clustering_model.fit(embeddings)
cluster_assignment = clustering_model.labels_
print(cluster_assignment)This type of embedding is found to be more efficient for specific task based LLMs.
Let us now get into the use cases of this embedding model.
Semantic Search with Instructor model and LanceDB.
We are using Instruct Embedding model with LanceDB embedding API. Find more here.
So, now we make a call to the registry to get our custom embedding model from the API.
Here, we also pass the instruction while calling the embedding model.
import lancedb
from lancedb.pydantic import LanceModel, Vector
from lancedb.embeddings import get_registry
from lancedb.embeddings import InstructorEmbeddingFunction
instructor = get_registry().get("instructor").create(
source_instruction="represent the document for retreival",
query_instruction="represent the document for most similar definition")Creating a schema for the data to be ingested. We can change the schema according to our need, but we are going to go with this template for now.
We will instantiate the DB and create a table to store the data.
#custom schema for our model
class Schema(LanceModel):
vector: Vector(instructor.ndims()) = instructor.VectorField()
text: str = instructor.SourceField()
#intializing the db and creating a table
db = lancedb.connect("~/.lancedb")
tbl = db.create_table("intruct-multitask", schema=Schema, mode="overwrite")Add the data to the table.
"""
data = [
{"instruction": "Represent the science title:", "text": "Aspirin is a widely-used over-the-counter medication known for its anti-inflammatory and analgesic properties. It is commonly used to relieve pain, reduce fever, and alleviate minor aches and pains."},
{"instruction": "Represent the science title:", "text": "Amoxicillin is an antibiotic medication commonly prescribed to treat various bacterial infections, such as respiratory, ear, throat, and urinary tract infections. It belongs to the penicillin class of antibiotics and works by inhibiting bacterial cell wall synthesis."},
{"instruction": "Represent the science title:", "text": "Atorvastatin is a lipid-lowering medication used to manage high cholesterol levels and reduce the risk of cardiovascular events. It belongs to the statin class of drugs and works by inhibiting an enzyme involved in cholesterol production in the liver."},
]
"""
#we pass the data in this format to lancedb for embedding
data = [
{"text": "Aspirin is a widely-used over-the-counter medication known for its anti-inflammatory and analgesic properties. It is commonly used to relieve pain, reduce fever, and alleviate minor aches and pains."},
{"text": "Amoxicillin is an antibiotic medication commonly prescribed to treat various bacterial infections, such as respiratory, ear, throat, and urinary tract infections. It belongs to the penicillin class of antibiotics and works by inhibiting bacterial cell wall synthesis."},
{"text": "Atorvastatin is a lipid-lowering medication used to manage high cholesterol levels and reduce the risk of cardiovascular events. It belongs to the statin class of drugs and works by inhibiting an enzyme involved in cholesterol production in the liver."}
]
tbl.add(data)Did you notice the commented out data variable? Now, if you were not using LanceDB’s embedding API for the Instructor model, you would have to pass the instruction along with the data like shown above. But because we have already defined the instruction while calling the model, we don’t have to pass it again.
Now, we are going use this embedding for Semantic Search.
LanceDB facilitates direct text search, obviating the necessity for manual query embedding.
query = "amoxicillin"
result = tbl.search(query).limit(1).to_pandas()
print(result)Which will give us an output like this:
vector \
0 [-0.024510665, 0.0005563133, 0.0288403, 0.0807...
text _distance
0 Amoxicillin is an antibiotic medication common... 0.163671 Same Data with Different Instruction Pair
To analyze the effect and contrast between different instruction pairs, we shall input the same data but with another pair.
This is the new instruction pair for the same input data as above. For brevity, only the instruction part is shown below.
instructor = get_registry().get("instructor").create(
source_instruction="represent the captions",
query_instruction="represent the captions for retrieving duplicate captions"
)From this we will get an output like this:
vector \
0 [-0.024483299, 0.000932854, 0.033273745, 0.077...
text _distance
0 Amoxicillin is an antibiotic medication common... 0.18135The _distance value is different for each embedding we calculated on the same data, but with different instruction pairs.
Question Answering with Instructor model and LanceDB.
You can just call the model from registry, and change the query instruction.
import lancedb
from lancedb.pydantic import LanceModel, Vector
from lancedb.embeddings import get_registry
from lancedb.embeddings import InstructorEmbeddingFunction
instructor = get_registry().get("instructor").create(
source_instruction="represent the docuement for retreival",
query_instruction="Represent the wikipedia question for retreving supporting documnents"
)Creating the schema and the DB.
class Schema(LanceModel):
vector: Vector(instructor.ndims()) = instructor.VectorField()
text: str = instructor.SourceField()
db = lancedb.connect("~/.lancedb-qa")
tbl = db.create_table("intruct-multitask-qa", schema=Schema, mode="overwrite")Let’s add the data.
data_qa = [ {"text": "A canvas painting is artwork created on a canvas surface using various painting techniques and mediums like oil, acrylic, or watercolor. It is popular in traditional and contemporary art, displayed in galleries, museums, and homes."},
{"text": "A cinema, also known as a movie theater or movie house, is a venue where films are shown to an audience for entertainment. It typically consists of a large screen, seating arrangements, and audio-visual equipment to project and play movies."},
{"text": "A pocket watch is a small, portable timekeeping device with a clock face and hands, designed to be carried in a pocket or attached to a chain. It is typically made of materials such as metal, gold, or silver and was popular during the 18th and 19th centuries."},
{"text": "A laptop is a compact and portable computer with a keyboard and screen, ideal for various tasks on the go. It offers versatility for browsing, word processing, multimedia, gaming, and professional work."}
]
tbl.add(data_qa)Querying the database using text search.
query = "what is a cinema"
result = tbl.search(query).limit(1).to_pandas()
print(result.text) vector \
0 [0.021844529, 0.0017777127, 0.022723941, 0.049...
text _distance
0 A cinema, also known as a movie theater or mov... 0.131036You can find various types of instructions for your use case. Check out the official project page of Instruct.

Visit our GitHub and if you wish to learn more about LanceDB python and Typescript library
For more such applied GenAI and VectorDB applications, examples and tutorials visit VectorDB-Recipes.
Lastly, for more information and updates, follow our LinkedIn and Twitter.