
NER stands for Named Entity Recognition, a form of natural language processing (NLP) that involves extracting and identifying essential information from text. The information that is extracted and categorized is called an entity. It can be any word or a series of words that consistently refers to the same thing. Some examples of entities are:
- Person: The name of a person, such as John, Mary, or Barack Obama.
- Organization: The name of a company, institution, or group, such as Google, NASA, or LanceDB.
- Location: The name of a geographical place, such as London, Mount Everest, or Mars.
- Date/Time: A specific point or period in time, such as 2023, November 5, or 14:23:31.
- Numeral: A numerical value, such as 42, 3.14, or $199.99.

In simpler words, if your task is to find out ‘where’, ‘what’, ‘who’, and ‘when’ from a sentence, NER is the solution you should opt for.
Methods of Named Entity Recognition
- Dictionary-Based NER — In this method, a vocabulary-based dictionary is utilized, and basic string-matching algorithms are employed to determine if an entity exists within the provided text by comparing it with the entries in the vocabulary. However, this method is typically avoided due to the necessity of regularly updating and maintaining the dictionary.
- Rule-Based NER — This approach relies on employing a predefined collection of rules for extracting information, with these rules being categorized into two types: pattern-based and context-based. Pattern-based rules analyze the morphological patterns of words, while context-based rules examine the context in which the words appear within the text document.
- Deep Learning- Based NER — Deep learning NER outperforms all other methods in terms of accuracy due to its ability to construct word associations, leading to a superior understanding of the semantic and syntactic connections among words. Additionally, it possesses the capability to automatically analyze topic-specific and high-level terminology.
In this blog, we’ll see an example of Named Entity Recognition using the Deep Learning approach for which, we use a dataset containing ~190K articles scraped from Medium. We selected 50K articles from the dataset as indexing all the articles may take some time.
To extract named entities, we will use a NER model finetuned on a BERT-base model.
The flow will look like this
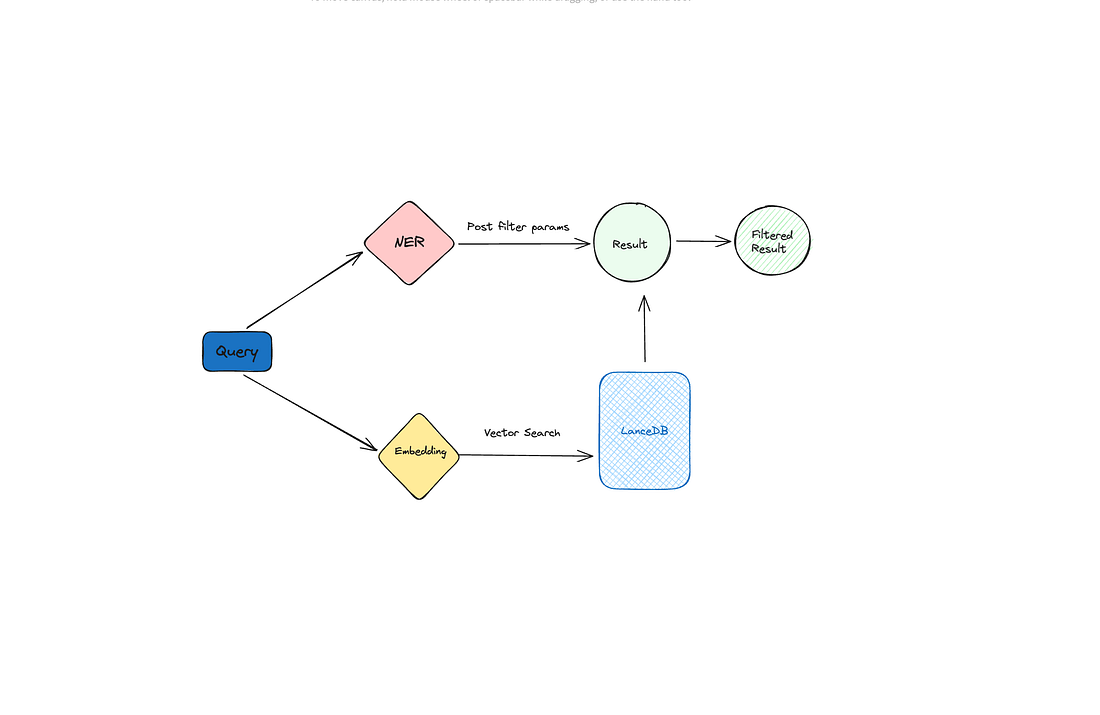
In short, we use the NER model to further filter the semantic search results. The predicted named entities are used as “post filters” to filter the vector search results.
Implementation
In the Implementation section, we see the step-by-step implementation of NER on the Medium dataset. Starting with the first step of loading the dataset from huggingface.
from datasets import load_dataset
# load the dataset and convert to pandas dataframe
df = load_dataset(
"fabiochiu/medium-articles",
data_files="medium_articles.csv",
split="train"
).to_pandas()Once a dataset is loading, we’ll preprocess a loaded dataset which will include removing empty rows, taking only 1000 words from the article, etc.
# drop empty rows and select 20k articles
df = df.dropna().sample(20000, random_state=32)
df.head()
# select first 1000 characters
df["text"] = df["text"].str[:1000]
# join article title and the text
df["title_text"] = df["title"] + ". " + df["text"]These are basic preprocessing steps that I have performed; you can apply them further according to your datasets.
To extract named entities, we will use a NER model finetuned on a BERT-base model. The model can be loaded from the HuggingFace model hub.
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_id = "dslim/bert-base-NER"
# load the tokenizer from huggingface
tokenizer = AutoTokenizer.from_pretrained(
model_id
)
# load the NER model from huggingface
model = AutoModelForTokenClassification.from_pretrained(
model_id
)
# load the tokenizer and model into a NER pipeline
nlp = pipeline(
"ner",
model=model,
tokenizer=tokenizer,
aggregation_strategy="max",
device=device
)Let’s try to use the NER pipeline to extract named entities from the text
text = "What are the best Places to visit in London"
nlp(text)The output of the pipeline looks like
[{'entity_group': 'LOC',
'score': 0.99969244,
'word': 'London',
'start': 37,
'end': 43}]This shows our NER pipeline is working as expected and accurately extracting entities from the text.
Now we have the NER pipeline, we’ll initialize the Retriever.
A Retriever model is used to embed passages (article title + first 1000 characters) and queries. It creates embeddings such that queries and passages with similar meanings are close in the vector space. We will use a sentence-transformer model as our retriever. The model can be loaded using the following code.
from sentence_transformers import SentenceTransformer
# load the model from huggingface
retriever = SentenceTransformer(
'flax-sentence-embeddings/all_datasets_v3_mpnet-base',
device=device
)Now let's generate Embeddings and insert them inside LanceDB for querying
Connect LanceDB
import lancedb
db = lancedb.connect("./.lancedb")Let’s first write a helper function to extract named entities from a batch of text.
def extract_named_entities(text_batch):
# extract named entities using the NER pipeline
extracted_batch = nlp(text_batch)
entities = []
# loop through the results and only select the entity names
for text in extracted_batch:
ne = [entity["word"] for entity in text]
entities.append(ne)
return entitiesNow generating embeddings and storing them in the table of LanceDB with their respective metadata
from tqdm.auto import tqdm
import warnings
import pandas as pd
import numpy as np
warnings.filterwarnings('ignore', category=UserWarning)
# we will use batches of 64
batch_size = 64
data = []
from collections import defaultdict
# table_data = defaultdict(list)
for i in tqdm(range(0, len(df), batch_size)):
# find end of batch
i_end = min(i+batch_size, len(df))
# extract batch
batch = df.iloc[i:i_end].copy()
# generate embeddings for batch
emb = retriever.encode(batch["title_text"].tolist()).tolist()
# extract named entities from the batch
entities = extract_named_entities(batch["title_text"].tolist())
# remove duplicate entities from each record
batch["named_entities"] = [list(set(entity)) for entity in entities]
batch = batch.drop('title_text', axis=1)
# get metadata
meta = batch.to_dict(orient="records")
# create unique IDs
ids = [f"{idx}" for idx in range(i, i_end)]
# add all to upsert list
to_upsert = list(zip(ids, emb, meta,batch["named_entities"]))
for id, emb, meta, entity in to_upsert:
temp = {}
temp['vector'] = np.array(emb)
temp['metadata'] = meta
temp['named_entities'] = entity
data.append(temp)
#create table using above data
tbl = db.create_table("tw", data)
# check table
tbl.head()Now we have all the embeddings with their metadata in a table, we can start querying.
Let’s first write a helper function to extract the named entity, encode text into retriever format, and filter the query results.
def search_lancedb(query):
# extract named entities from the query
ne = extract_named_entities([query])[0]
# create embeddings for the query
xq = retriever.encode(query).tolist()
# query the lancedb table while applying named entity filter
xc = tbl.search(xq).to_list()
# extract article titles from the search result
r = [x["metadata"]["title"] for x in xc for i in x["metadata"]["named_entities"] if i in ne]
return pprint({"Extracted Named Entities": ne, "Result": r})Now Let's try Querying
query = "How Data is changing world?"
search_lancedb(query)Output looks like
{'Extracted Named Entities': ['Data'],
'Result': ['Data Science is all about making the right choices']}Another Query
query = "Why does SpaceX want to build a city on Mars?"
search_lancedb(query)Output looks like
{'Extracted Named Entities': ['SpaceX', 'Mars'],
'Result': ['Mars Habitat: NASA 3D Printed Habitat Challenge',
'Reusable rockets and the robots at sea: The SpaceX story',
'Reusable rockets and the robots at sea: The SpaceX story',
'Colonising Planets Beyond Mars',
'Colonising Planets Beyond Mars',
'Musk Explained: The Musk approach to marketing',
'How We’ll Access the Water on Mars',
'Chasing Immortality',
'Mission Possible: How Space Exploration Can Deliver Sustainable '
'Development']}For quickstart, You can try out Google Colab, which has all this code.
NER is widely used in various NLP tasks. These include:
- Efficient search algorithms
- Content recommendations
- Customer support
- Healthcare
- Summarizing resumes
- Content classification for news channels.
Conclusion
Named entity recognition primarily uses NLP and Deep Learning. With NLP, a NER model studies the structure and rules of language and tries to form intelligent systems that are capable of deriving meaning from text and speech. Meanwhile, Deep Learning algorithms help an NER model to learn and improve over time.
Using these two technologies, the model detects a word or string of words as an entity and classifies it into a category it belongs to. Harnessing the advanced vector search functionalities provided by LanceDB enhances its overall utility.
Visit the LanceDB repo to learn more about lanceDB python and Typescript library
To discover more such applied GenAI and vectorDB applications, examples, and tutorials visit VectorDB-Recipes