by Mahesh Deshwal
Problem Statement:
In a typical RAG pipeline, LLM Context window is limited so for a hypothetical 10000 pages document, we need to chunk the document. For any incoming user query, we need to fetch `Top-N` related chunks and because neither our Embedding are 100% accurate nor search algo is perfect, it could give us unrelated results too. This is a flaw in RAG pipeline. How can you deal with it? If you fetch Top-1 and the context is different then it’s a sure bad answer. On the other hand, if you fetch more chunks and pass to LLM, it’ll get confused and with higher number, it’ll go out of context.
What’s the remedy?
Out of all the methods available, Re-ranking is the simplest. Idea is pretty simple.
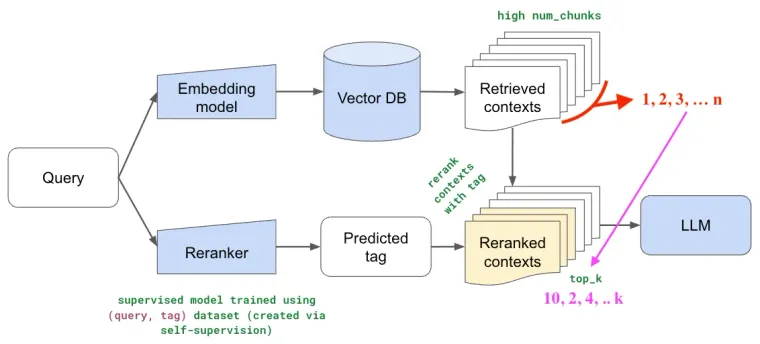
1. You assume that Embedding + Search algo are not 100% precise so you use Recall to your advantage and get similar high `N` (say 25) number of related chunks from corpus.
2. Second step is to use a powerful model to increase the Precision. You re-rank above `N` queries again so that you can change the relative ordering and now select Top `K` queries (say 3) to pass as a context where `K` < `N` thus increasing the Precision.
Why can’t you use the bigger model in the first place?
Would your search results be better if you were searching in 100 vs 100000 documents? Yes, so no matter how big of a model you use, you’ll always have some irrelevent results because of the huge domain.
Smaller model with efficient searching algo does the work of searching in a bigger domain to get more number of elements while the larger model is precise and because it just works on `K`, there is a bit more overhead but improved relevancy.

Follow along with this colab
!pip install -U lancedb transformers datasets FlagEmbedding unstructured -qq
# NOTE: If there is an import error, restart and run the notebook again
from FlagEmbedding import LLMEmbedder, FlagReranker
# Al document present here https://github.com/FlagOpen/FlagEmbedding/tree/master
import os
import lancedb
import re
import pandas as pd
import random
from datasets import load_dataset
import torch
import gc
import lance
from lancedb.embeddings import with_embeddings
task = "qa" # Encode for a specific task (qa, icl, chat, lrlm, tool, convsearch)
embed_model = LLMEmbedder('BAAI/llm-embedder', use_fp16=False) # Load model (automatically use GPUs)
reranker_model = FlagReranker('BAAI/bge-reranker-base', use_fp16=True) # use_fp16 speeds up computation with a slight performance degradationLoad BeIR Dataset. This is a dataset built specially for retrieval tasks to see how good your search is working
queries = load_dataset("BeIR/scidocs", "queries")["queries"].to_pandas()
docs = load_dataset('BeIR/scidocs', 'corpus')["corpus"].to_pandas().dropna(subset = "text").sample(10000) # just random samples for faster embed demo
docs.sample(3)Get embedding using LLM embedder and create Database using LanceDB
def embed_documents(batch):
"""
Function to embed the whole text data
"""
return embed_model.encode_keys(batch, task=task) # Encode data or 'keys'
db = lancedb.connect("./db") # Connect Local DB
if "doc_embed" in db.table_names():
table = db.open_table("doc_embed") # Open Table
else:
# Use the train text chunk data to save embed in the DB
data = with_embeddings(embed_documents, docs, column = 'text',show_progress = True, batch_size = 128)
table = db.create_table("doc_embed", data=data) # create TableSearch from a random Text
def search(query, top_k = 10):
"""
Search a query from the table
"""
query_vector = embed_model.encode_queries(query, task=task) # Encode the QUERY (it is done differently than the 'key')
search_results = table.search(query_vector).limit(top_k)
return search_results
query = random.choice(queries["text"])
print("QUERY:-> ", query)
# get top_k search results
search_results = search("what is mitochondria?", top_k = 10).to_pandas().dropna(subset = "text").reset_index(drop = True)
search_resultsRe-rank Search Results using Re-ranker from BGE Reranker
Pass all the results to a stronger model to give them the similarity ranking
def rerank(query, search_results):
search_results["old_similarity_rank"] = search_results.index+1 # Old ranks
torch.cuda.empty_cache()
gc.collect()
search_results["new_scores"] = reranker_model.compute_score([[query,chunk] for chunk in search_results["text"]]) # Re compute ranks
return search_results.sort_values(by = "new_scores", ascending = False).reset_index(drop = True)
print("QUERY:-> ", query)
rerank(query, search_results)Visit the LanceDB (YC W22) repo to learn more about lanceDB python and Typescript library
To discover more applied GenAI and vectorDB applications, examples, & tutorials, visit vectordb-recipes
Adios Amigos! Until next time …….
