This is a collective work of the following authors:
Sharan Shirodkar (Prediction Guard) Daniel Whitenack (Prediction Guard)
Bingyang (Icy) Wang (Emory University) Guangming (Dola) Qiu (Emory University) Jerry (Yuzhong) M. (Emory University) Yige Wang (Emory University)
Introduction
In spite of their eloquence and popularity, Large Language Models (LLMs) often struggle to generate output that is factually accurate. In particular, they can hallucinate information due to a limited grounding in reality. This problem is magnified in high-stakes domains like healthcare, where any faulty information could lead to critical errors or patient harm. Even minor inaccuracies cannot be tolerated when lives are at stake.
At the same time, generative AI systems are poised to create widespread, positive changes in healthcare. Imagine a world where healthcare professionals and volunteers are free to devote their full attention to their patients, unburdened by labor-intensive paperwork. Envisage a future where AI can streamline administrative processes, freeing up valuable time and resources.
In this post, we present innovative work from a team of Emory University students that leveraged LanceDB and Prediction Guard to prevent hallucinations in an LLM-based system for processing medical transcriptions. This work was part of the recent Data4Good Case Competition sponsored by Microsoft, Prediction Guard, and Purdue University.
The Data4Good Competition
The Data4Good Competition concluded on December 2nd, 2023, bringing together undergraduate and graduate students from various regions to showcase their critical thinking, data analysis, and artificial intelligence skills. Co-sponsored by Mitchell E. Daniels, Jr. School of Business master’s programs, Microsoft, INFORMS, Prediction Guard, and Certiport, this prestigious case competition offered a total prize pool of $45,000. Teams of 3–4 students competed in regional rounds, and the top-performing teams advanced to the final competition held at Purdue University in West Lafayette, IN.
The competition addressed the pressing issue of automating medical form filling, recognizing the labor-intensive nature of this process within the healthcare and hospice sectors. Participants were challenged to leverage open-source LLMs (like Llama 2 and WizardCoder) to extract, rephrase, summarize, and validate information needed for medical forms based on simulated medical transcription (e.g., patient-doctor conversations or doctor dictations). These open-source models were accessed via Prediction Guard, a company developing private LLM APIs with features focusing on safety and trust (PII and prompt injection filtering, factuality checking, toxicity checks, etc.). The competition provided (as input data) synthesized transcriptions of medical conversations similar to:
D: What brings you in?
P: Hi, I’ve I’ve had this pain on the outside of my uh right elbow now it’s it I first started knowing, noticing it several months ago, but recently it’s just been more painful.
D: OK, so you said several months ago. Um did anything happen several months ago? Was there any sort of trigger, trauma, anything like that to that area?
P: No, there wasn’t any any trauma or any triggers that that I noticed, I was just um feeling it, uh, a bit more at the end of of work. Um yeah, I was just having it uh, feeling the pain a bit more at the end of work.
D: OK, does uh anything make it better or worse, the pain?
P: Um yeah, if I, really if I’m just resting the elbow um it makes it better, and I’ve tried uh things like ibuprofen um which has helped with the pain, I’ll I’ll do that for um hoping I can get through work sometimes if the pain is bad enough.
D: Right, OK. Um and if you were to describe the quality of the pain, is it sharp, throbby, achy?
P: Uh it’s um kind of uh, well, it’s achy and then sometimes depending on the movement it can get, it can be sharp as well.
D: It can be sharp, OK. OK, um and what sorts of movements make it worse?
P: Um, so like, really it’s mostly the movements at my wrist, if I’m bending my wrist down, uh I can I can feel it, or um if I’m having to pick things up or hold heavy objects at work, I do a lot of repetitive uh things at at work, I work on a line.
D: OK, OK. And 1 to 10, 10 being the worst pain you’ve ever felt, how bad is this pain?
P: It is about a four.
D: About a four, OK. And have you ever experienced this type of pain before?
P: etc…
Based on these kinds of transcriptions, teams needed to create an LLM-based system to answer specific medical form questions like:
- What symptoms is the patient experiencing? Pain on the outside of their right elbow
- When did the symptoms start? 3 months ago
- What medicine did the doctor prescribe? Tylenol
- etc…
Obviously, hallucinating the answers to such questions could have serious consequences for patient care. That’s where Emory’s unique retrieval-based system utilizing LanceDB and Prediction Guard could step in to help!
Mitigating Hallucinations via Retrieval Augmentation
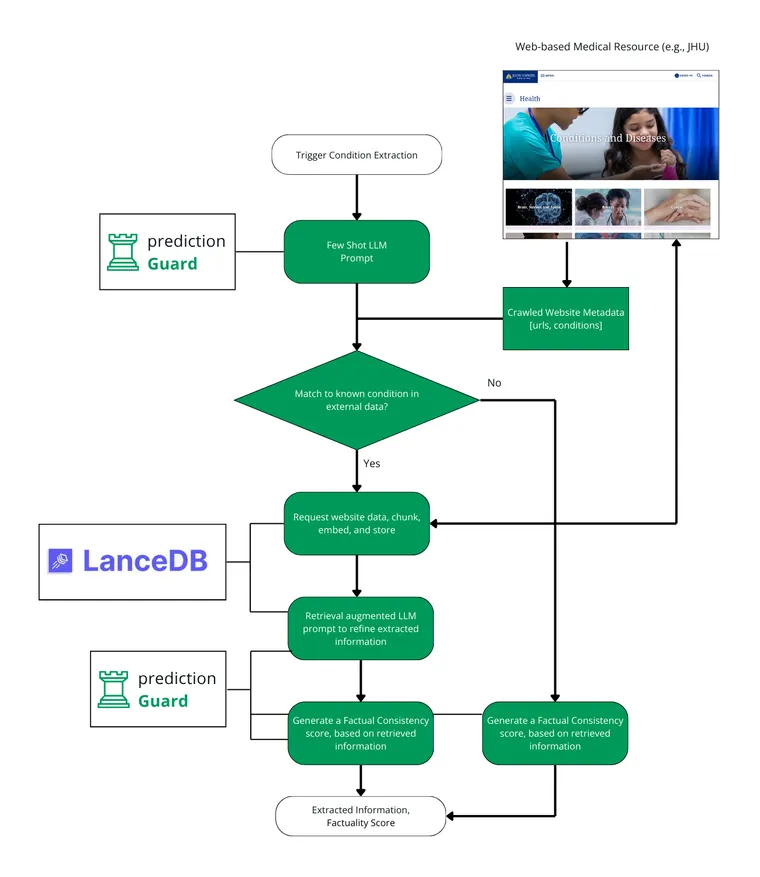
Although every medical transcription will be unique, much external information exists about real-world medical conditions, symptoms, medicines, etc. To ground the information extraction capabilities of their solution, the Emory students employ a hybrid, two-step retrieval augmentation methodology.
First, the solution utilizes non-vector fuzzy matching to crawl information about certain trusted sources of medical information, such as those from JHU Medicine, by crawling the site map under www.hopkinsmedicine.org/health/conditions-and-diseases/<name of conditions>. The crawled information includes extracted URLs (e.g., of pages discussing medical conditions and treatments) along with corresponding metadata (title, page description, etc.). When processing a new medical transcription, an LLM (using a few shot prompt) extracts a guess for the symptoms and condition represented in the transcription. The LLM might suggest, for example, that the patient is experiencing a “fungal infection” with symptoms including “Weight loss, Chest pain, and Itchy or scaly skin.” This guess information is then fuzzy matched (via Levenshtein Distance and a collection of common condition acronyms) to relevant reference URLs via the crawled metadata.

If the content from the matched reference URLs has not been downloaded previously, it is requested and parsed programmatically. The content is chunked, embedded, and loaded into LanceDB on the fly in sections such as introductions, symptoms, and treatments. Sentence Transformers is used to generate embeddings via the open-access embedding model “all-MiniLM-L12-v2”. LanceDB was used partially because of the ease with which the API could be integrated into the processing code. However, the on-disk and serverless nature of LanceDB make it additionally appealing for this use case because healthcare clients will often need to self-host databases and/or keep data within their own networks.

In the second stage of retrieval, the transcription is matched to relevant chunks from the retrieved medical documents via vector search. These chunks of the documents are injected into a template for a retrieval augmented prompt and a second LLM call. The second LLM call benefits from the reference medical information, improving the results and reducing the likelihood of hallucinating irrelevant symptoms, treatments, or condition names.
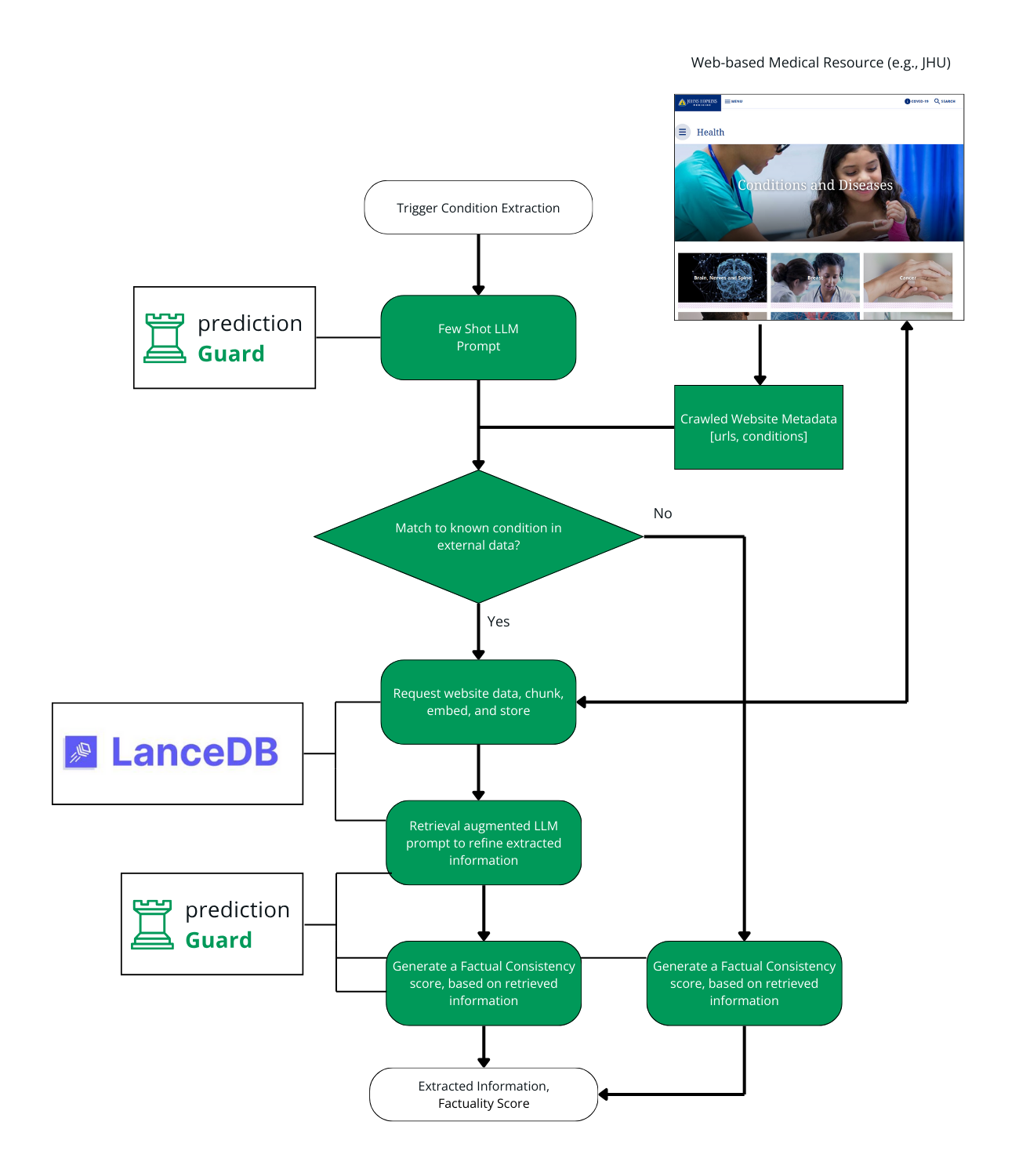
This two-step, hybrid methodology, which the Emory students call “condition-based RAG”, has the following benefits:
- Reduction in the burden to embed a vast knowledge base up-front. The fuzzy matching to relevant URLs is extremely efficient and allows relevant documents to gradually be parsed, chunked, embedded, and added to LanceDB.
- Integration of new data sources over time without any model re-training or batch updates to the vector database. New URLs can be scraped and added to the “stable” of reference documents over time, and they will be parsed and embedded as they are needed.
In the end, the above-described system resulted in a top 5 score in the Kaggle leaderboard for the Data4Good competition, with a Word Error Rate (WER) of around 0.5. The students estimate that at this error rate, such a system could save hours of administrative work every week for healthcare workers. This translates to freeing up more physician availability for clinically important activities like examining patients, making diagnoses, formulating treatment plans, etc.
They envision applying this in a human-in-the-loop manner. Specifically, the team envisions combining the retrieval augmented output with a factual consistency score from Prediction Guard. This is calculated by comparing a reference text (e.g., one retrieved from LanceDB) with the generated form field to check for inaccuracies. Low-scoring results can be prioritized for human review, such that human annotators can focus their efforts on suspect answers from the LLM-based system.
Key Takeaways
Retrieval has proved to be one of the most applied mechanisms for those building and deploying LLM-based applications. It provides a way for you to combine your data with LLMs (something that almost everyone wants to do) and build cool “chat-with-your-data” bots. However, the work by this team from Emory demonstrates that retrieval can also be used in a variety of interesting ways in the context of domain-specific information retrieval.
If you are trying to extract domain-specific information from unstructured data, consider leveraging external data sources that provide expertly curated information about the domain. You can match queries to this external data to provide context within your information extraction pipelines. In cases where data privacy is a concern, self-hosting a vector database can be easy using LanceDB as an embedded option with on-disk storage.
Also, think about combining the outputs of these pipelines with other kinds of evaluations (e.g., factual consistency) that are grounded in the retrieved information. The built-in factual consistency check in Prediction Guard provides an easy-to-access and scalable solution that is already integrated with a privacy-conserving LLM API.
Learn more here:
- Prediction Guard: https://www.predictionguard.com/
- RAG starter tutorial with Prediction Guard: https://docs.predictionguard.com/usingllms/augmentation#retrieval-augmentated-generation-rag
- Data4Good: https://business.purdue.edu/events/data4good/
- LanceDB: https://lancedb.com/