
Reranking is a process of re-arranging the results of a retriever based on some metric that can be independent of the retrieval scores. In this blog, we'll see how you can use LanceDB to use any of the popular reranking techniques including the new cohere reranker-V3 along with some results.
Reranking in LanceDB
LanceDB comes with built-in support for reranking across all search types - vector, full-text and hybrid search. Using a reranker is as simple as initializing a reranker object and passing that on to the query builder. Here's a simple example using the cohere reranker
import lancedb
from lancedb.rerankers import CohereReranker
from lancedb.pydantic import LanceModel, Vector
from lancedb.embeddings import get_registry
db = lancedb.connect("~/tmp/db")
embedding_fcn = get_registry().get("huggingface").create()
class Schema(LanceModel):
text: str = embedding_fcn.SourceField()
vector: Vector(embedding_fcn.ndims()) = embedding_fcn.VectorField()
tbl = db.create_table("tbl_example", schema=Schema)
tbl.add([ {"text": "hey"}, {"text": "bye"}, {"text": "hello"}, {"text": "goodbye"}])
reranker = CohereReranker(api_key="...") # Requires cohere API key
With this setup, you can now use this reranker for reranking results of any search type.
# Reranking Vector Search
tbl.search("hey").rerank(reranker=reranker).to_pandas()
# Reranking Full-Text Search
tbl.create_fts_index("text") # Create FTS index
tbl.search("bye", query_type="fts").rerank(reranker=reranker).to_pandas()
# Reranking Hybrid Search
tbl.search("bye", query_type="hybrid").rerank(reranker=reranker).to_pandas()
Benchmarking Cohere Reranker
In this test, we want to test the retrieval performance of rerankers. The baseline used will be the vector only search. We'll also use colbert-v2 model as reranker to add to the comparison. Note, this is different from colbert toolkit that implements its own searching and indexing algorithm.
Full code can be found here
 lancedb
lancedbEvaluation metric
Here we are not evaluating a RAG. Our tests are limited to testing the quality of the retriever. So, we'll devise a simple metric that just measures the hit-rate of a retriever, which is a simplified version of recall@k or mAP.
# Contains only relevant snippets
def evaluate(
docs,
dataset,
embed_model=None,
reranker=None,
top_k=5,
query_type="auto",
):
# Create vector store from docs
tbl = vector_store._connection.open_table(vector_store.table_name)
eval_results = []
for idx in tqdm(range(len(datasets))):
query = ds['query'][idx]
reference_context = ds['reference_contexts'][idx]
try:
if reranker is None: # vector only search
rs = tbl.search(query, query_type="vector").to_pandas()
elif query_type == "auto": # Hybrid search
rs = tbl.search(query, query_type="hybrid").rerank(reranker=reranker).to_pandas()
elif query_type == "vector": # vector search with reranker
rs = tbl.search(query, query_type="vector").rerank(reranker=reranker).limit(top_k*2).to_pandas() # Overfetch for vector only reranking
except Exception as e:
print(f'Error with query: {idx} {e}')
continue
retrieved_texts = rs['text'].tolist()[:top_k]
expected_text = reference_context[0]
is_hit = expected_text in retrieved_texts # assume 1 relevant doc
eval_result = {
'is_hit': is_hit,
'retrieved': retrieved_texts,
'expected': expected_text,
'query': query,
}
eval_results.append(eval_result)
return pd.DataFrame(eval_results)['is_hit'].mean()Here, we are over-fetching results in case of vector only search results if a reranker is applied, i.e, we fetch 2*K results in this case. This is done to make sure reranker has some effect as we take the top K results after reranking. In this experiment, k is 5.
With this evaluation function, let's test rerankers across different datasets and embedding functions.
Benchmarking on real datasets
First dataset that we'll be using is Uber 10K dataset that contains more than 800 query-and -ontext pairs based on Uber's 2021 SEC filing. This dataset can be dowloaded and loaded from llama-index as follows:
!llamaindex-cli download-llamadataset Uber10KDataset2021 --download-dir ./data
from llama_index.core import SimpleDirectoryReader
from llama_index.core.llama_dataset import LabelledRagDataset
rag_dataset = LabelledRagDataset.from_json("./data/rag_dataset.json")
documents = SimpleDirectoryReader(input_dir="./data/source_files").load_data()Here `documents` contains the text to be ingested in the vector dataset and rag_dataset contains query and context pairs.
The 2nd dataset used is Evaluating LLM Survey Paper Dataset
The script calculates the evaluation score for each of these rerankers with other params remaining constant:
datasets = [ "Uber10Kdataset2021", "LLMevalData" ]
embed_models = {
"bge": HuggingFaceEmbedding(model_name="BAAI/bge-large-en-v1.5")
"colbert": HuggingFaceEmbedding(model_name="colbert-ir/colbertv2.0")
}
rerankers = {
"Vector-baseline": None,
"cohere-v2": CohereReranker(),
"cohere-v3": CohereReranker(model_name="rerank-english-v3.0"),
"ColbertReranker": ColbertReranker(),
}Results
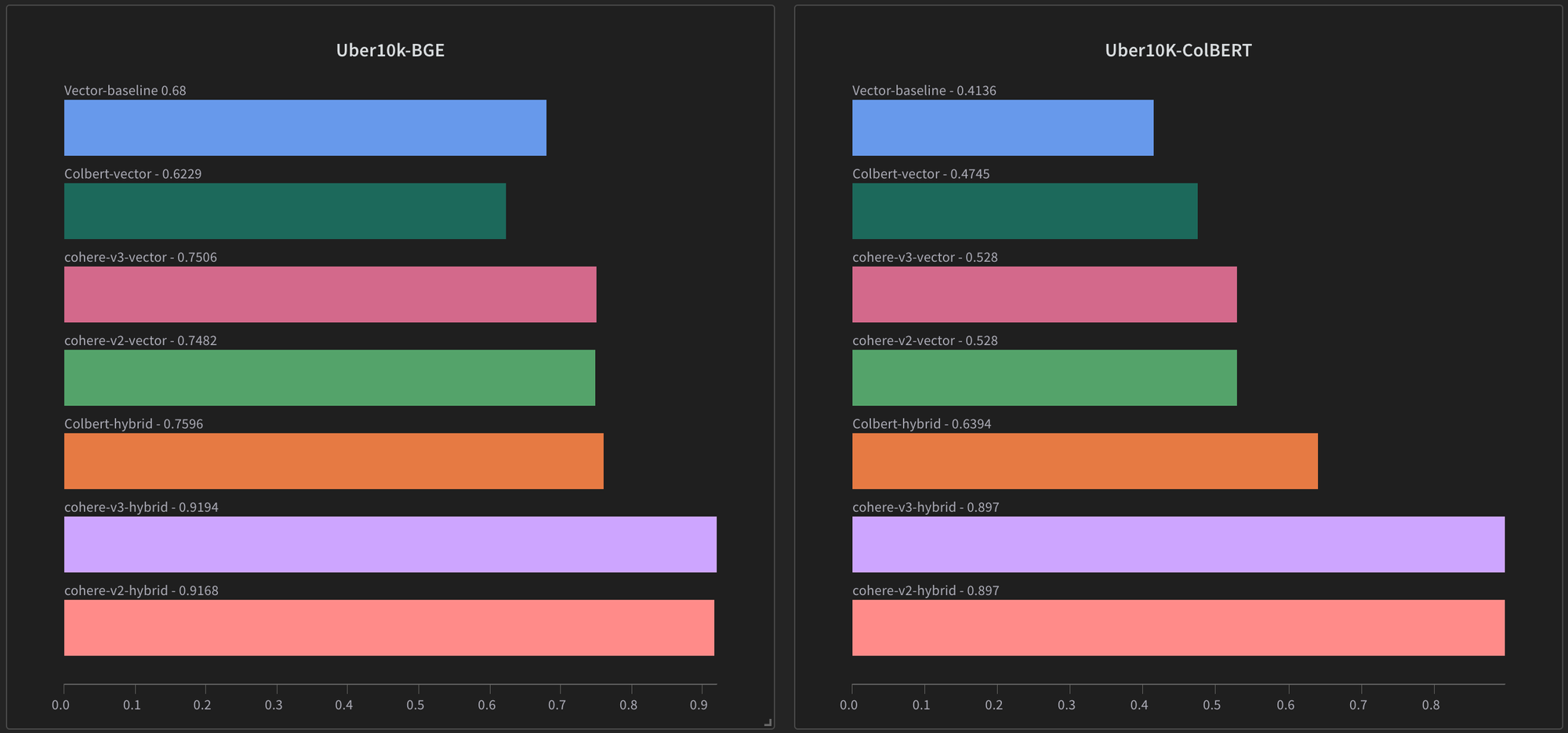
Overall the results are similar in case of both embedders, except ColBERT model used both as embedder and reranker seems to work slightly better when compared with the baseline. Cohere rerankers stand out here in terms of accuracy as they get the highest score. Simply by reranking over-fetched vector search results, it gets around 8% and 11% performance increase for BGE and ColBERT embedding function respectively.
Next up is hybrid search with ColBERT reranker which is expected. But hybrid search with Cohere reranker again stands out in both cases as it achieves more than 90%. That is approximately 23% and 49% improvement on the w.r.t the 2 embedding functions.
One thing that can be noticed here is that in terms of accuracy, the performance improvement of Cohere reranker-v3 over v2 is negligible. But because both the numbers are around 90%, this might not be the best dataset to measure Cohere v3 and v2 rerankers.
LLM Survey Paper Dataset
The results on this dataset are pretty much the same as the previous one. Cohere Reranker performs the best in case of both ColBERT and BGE embedding models. And ColBERT Reranker used with ColBERT embedding function performs slightly better than the baseline.
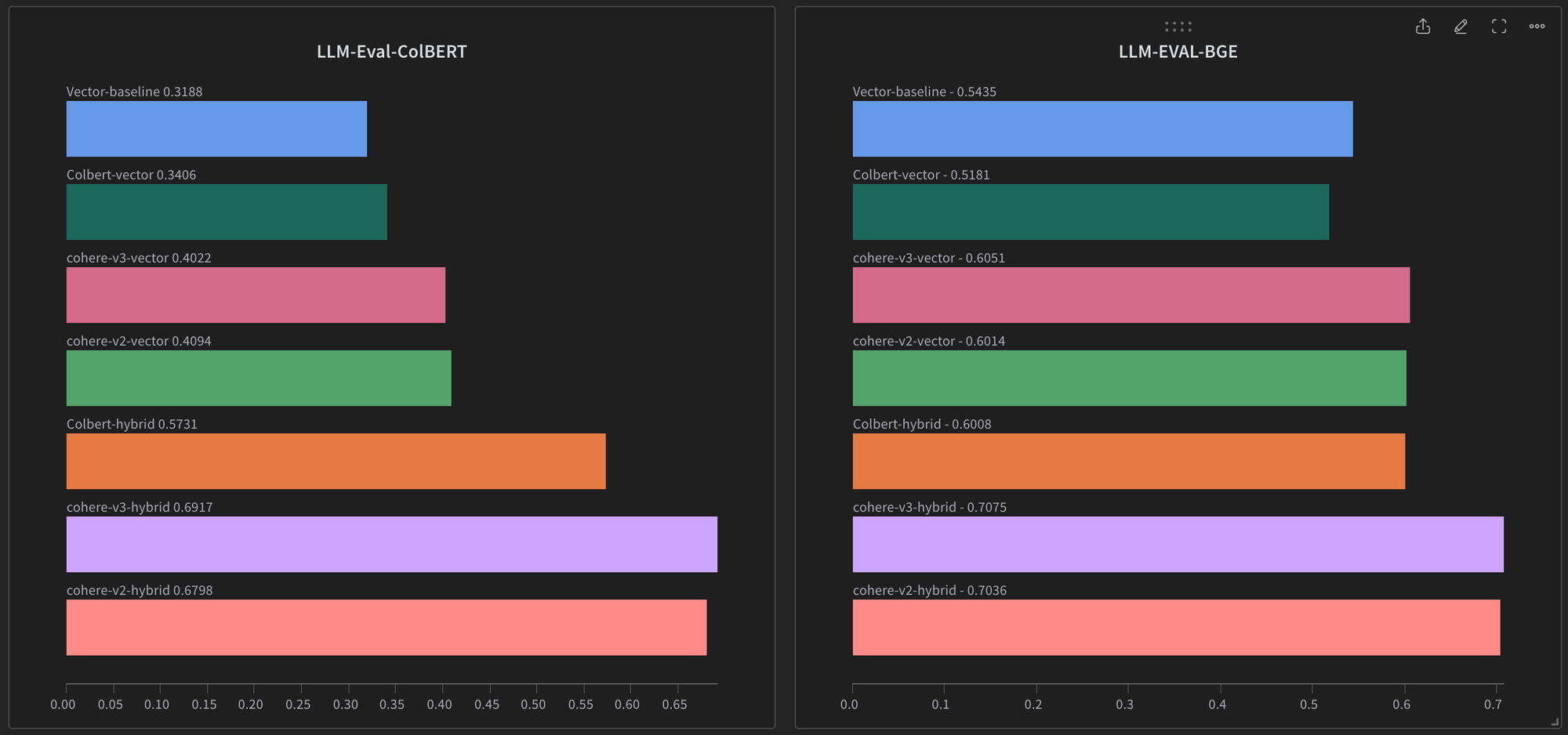
Cohere reranker v2 itself seems to reach the upper limit of retrieval accuracy in both the datasets so the improvement with v3 isn't all that noticeable. This might start to matter more on specific types of datasets. For example, on cohere's announcement blog, rerankers are compared on semi-structured JSON data and searching algorithm used is BM25 (full-text search in LanceDB) and not vector search. In those settings, rerank-v3 model shows significant improvements when compared with v2. These benchmarks are beyond the scope of this blog, but something that we plan to explore in the future.
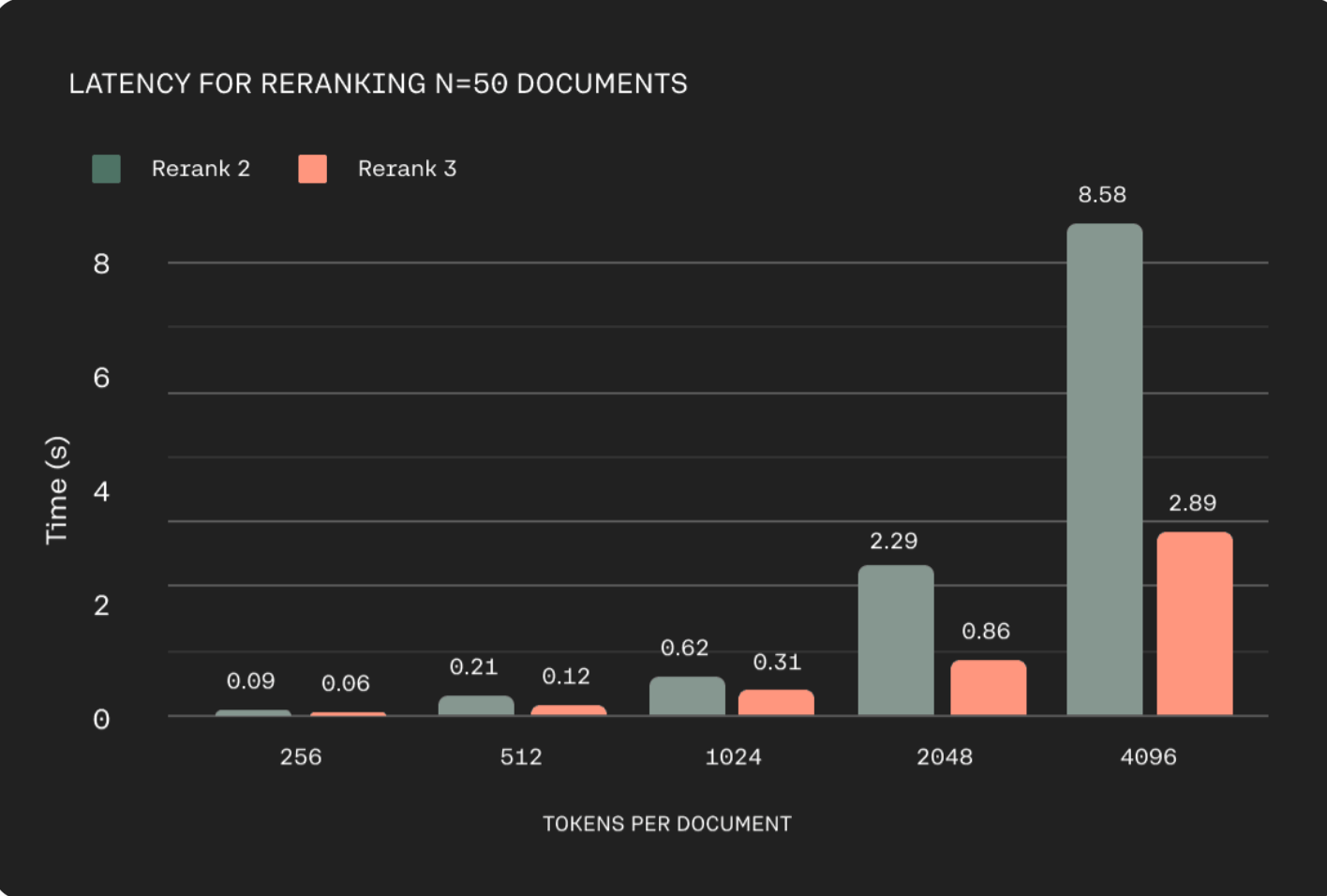
Apart from accuracy, rerank-v3 model API is also supposed to be much faster v2. Here's a comparison chart from Cohere's blog linked above:
Conclusion
This blog covers LanceDB's reranker API that allows you to plug in popular or custom reranking methods in your retrieval pipelines across all query types. In this part, we show the results of a couple of datasets but based on other similar datasets, cohere reranker performed the best across all of them. It beats every reranker including cross-encoders, linear combination, etc. across different embedding models. In the next parts, we'll cover more advanced datasets like structured and semi-structured retrieval to see if the the results change.
Drop us a 🌟
lancedblancedb