
Retrieval is a key component of any type of recommender system, including RAG. The quality of responses generated by chatbot can only be as good as the retrieved context. In this blog, we'll see how you can go about improving retrieval performance of limit our discussion to vectorDB-based retrievers.
There are various ways which you can go about improving the retrieval performance of vectorDB-based retriever but they can often end up disrupting the existing setup in place. For example, if the first thing you want to try to improve your retriever is change the chunking strategy, you'll need to re-ingest the entire dataset. Same goes if you want to change the embedding model. So, its always better to try simpler & faster to implement solutions before jumping to modelling or chunking. LanceDB comes with built-in APIs to streamline these experiments. Let's get started.
Experiment setup
We'll start off by selecting 2 dataset and set a baseline for the retrieval performance - SQuAD and a synthetic dataset generated from LLama2 review paper. The metric used here will be hit-rate @ top-5
Setting up the embedding model
Throughout this experiment the embedding model used will be BAAI/bge-small-en-v1.5 . With LanceDB embedding API, you can setup the tables to automatically embed your dataset and queries in the background, abstracting away the modelling details.
import lancedb
from lancedb.embeddings import get_registry
from lancedb.pydantic import Vector, LanceModel
model = get_registry().get("sentence-transformers").create(name="BAAI/bge-small-en-v1.5")
class Schema(LanceModel):
text: str = model.SourceField()
vector: Vector(model.ndims()) = model.VectorField()
# vector field is automatically generated
db = lancedb.connect("~/db")
table = db.create_table("table", schema=Schema)
data = [{"text": "data"}, {"text": "dddadata}, ...]
table.add(data)
table.search("query")
The baseline
| Dataset | Query Type | Reranker | Hit Rate |
|---|---|---|---|
| SQuAD | vector | 81.322 | |
| FTS | 83.509 | ||
| LLama2-review | vector | 58.63 | |
| FTS | 59.54 |
Reranking results
In the context of search, reranking means reordering the search results returned by a search algorithm based on some criteria. This can be useful when the initial ranking of the search results is not satisfactory or when the user has provided additional information that can be used to improve the ranking of the search results.
LanceDB Reranking API
LanceDB comes with some built-in rerankers. To use a reranker, you need to create an instance of the reranker and pass it to the rerank method of the query builder.
from lancedb.rerankers import ColbertReranker
colbert = ColbertReranker()
table.search("query").rerank(reranker=colbert) # reranker vector search
table.search("query", query_type="fts").rerank(reranker=colbert)
Reranking models used
The rerankers used in this experiment are all available out of the box with LanceDB. These are a mix of open-source and proprietary API-based models.
- Cross Encoder - This uses open source cross encoder architecture for generating similarity scores of query-context pairs for reranking. The model used is
cross-encoder/ms-marco-TinyBERT-L-6. This model was trained on the MS Marco Passage Ranking task. - Cohere - This uses API-based proprietary reranking model by Cohere. The model used here is
rerank-english-v2.0 - ColBERT - ColBERT relies on fine-grained contextual late interaction: it encodes each passage into a matrix of token-level embeddings. Then at search time, it embeds every query into another matrix and efficiently finds passages that contextually match the query using scalable vector-similarity operators. This experiment uses
colbert-v2models with approx ~110M params - AnswerDotAi Colbertv1 - This model builds upon the JaColBERTv2.5 recipe and has just 33 million parameters, meaning it’s able to search through hundreds of thousands of documents in milliseconds, on CPU. With its very small parameter count, it demonstrates that there’s a lot of retrieval performance to be squeezed out of creative approaches, such as multi-vector models, with low parameter counts, which are better suited to a lot of uses than gigantic 7-billion parameter embedders. Learn more about this in the AnswerDotAI announcement blog.
Reranked vector and FTS results
| Dataset | Query Type | Reranker | Hit Rate |
|---|---|---|---|
| SQuAD | vector | CrossEncoder | 85.22 |
| vector | ColBERT | 85.49 | |
| vector | Answerdotai ColBERT | 85.95 | |
| vector | Cohere | 86.09 | |
| FTS | 83.509 | ||
| FTS | CrossEncoder | 86.73 | |
| FTS | ColBERT | 86.74 | |
| FTS | Answerdotai ColBERT | 87.24 | |
| FTS | Cohere | 87.72 | |
| LLama2-review | vector | CrossEncoder | 62.27 |
| vector | ColBERT | 62.72 | |
| vector | Answerdotai ColBERT | 65.45 | |
| vector | Cohere | 66.80 | |
| FTS | 59.54 | ||
| FTS | CrossEncoder | 60.90 | |
| FTS | ColBERT | 64.54 | |
| FTS | Answerdotai ColBERT | 65.00 | |
| FTS | Cohere | 67.27 |
Note: In case of vector and FTS only search, the results were over-fetched by a factor of 2 for reranking and then the top-k( top-5 ) results were taken. This is needed as there is only one result set, unlike hybrid search where there are result sets from both vector and FTS. Without over-fetching, reranking would not have any effect.
Hybrid Search
Hybrid search is broad term that refers to a search algorithm that combines multiple search techniques. You can perform hybrid search in LanceDB by combining the results of semantic and full-text search via a reranking algorithm of your choice.
LanceDB hybrid search with custom Reranking
table.search("query", query_type="hybrid") # uses Liner combination reranker
table.search("query", query_type="hybrid").rerank(reranker=colbert)Hybrid search with reranking results
| Dataset | Query Type | Reranker | Hit Rate |
|---|---|---|---|
| SQuAD | Hybrid | LinearCombination | 88.42 |
| Hybrid | Reciprocal Rank Fusion | 89.81 | |
| Hybrid | CrossEncoder | 91.51 | |
| Hybrid | ColBERT | 91.53 | |
| Hybrid | Answerdotai ColBERT | 92.26 | |
| Hybrid | Cohere | 92.35 | |
| LLama2-review | Hybrid | LinearCombination | 62.27 |
| Hybrid | Reciprocal Rank Fusion | 66.36 | |
| Hybrid | CrossEncoder | 65.45 | |
| Hybrid | ColBERT | 70.90 | |
| Hybrid | Answerdotai ColBERT | 70.90 | |
| Hybrid | Cohere | 75.00 |
Full benchmark
| Dataset | Query Type | Reranker | Hit Rate |
|---|---|---|---|
| SQuAD | vector | 81.322 | |
| vector | CrossEncoder | 85.22 | |
| vector | ColBERT | 85.49 | |
| vector | Answerdotai ColBERT | 85.95 | |
| vector | Cohere | 86.09 | |
| FTS | 83.509 | ||
| FTS | CrossEncoder | 86.73 | |
| FTS | ColBERT | 86.74 | |
| FTS | Answerdotai ColBERT | 87.24 | |
| FTS | Cohere | 87.72 | |
| Hybrid | LinearCombination | 88.42 | |
| Hybrid | Reciprocal Rank Fusion | 89.81 | |
| Hybrid | CrossEncoder | 91.51 | |
| Hybrid | ColBERT | 91.53 | |
| Hybrid | Answerdotai ColBERT | 92.26 | |
| Hybrid | Cohere | 92.35 |
| Dataset | Query Type | Reranker | Hit Rate |
|---|---|---|---|
| LLama2-review | vector | 58.63 | |
| vector | CrossEncoder | 62.27 | |
| vector | ColBERT | 62.72 | |
| vector | Answerdotai ColBERT | 65.45 | |
| vector | Cohere | 66.80 | |
| FTS | 59.54 | ||
| FTS | CrossEncoder | 60.90 | |
| FTS | ColBERT | 64.54 | |
| FTS | Answerdotai ColBERT | 65.00 | |
| FTS | Cohere | 67.27 | |
| Hybrid | LinearCombination | 62.27 | |
| Hybrid | Reciprocal Rank Fusion | 66.36 | |
| Hybrid | CrossEncoder | 65.45 | |
| Hybrid | ColBERT | 70.90 | |
| Hybrid | Answerdotai ColBERT | 70.90 | |
| Hybrid | Cohere | 75.00 |
SQuAD
Baseline: Vector Search - 81.322
Best result: Hybrid search with Cohere reranker - 92.35
Llama-2-review
Baseline: Vector Search - 58.63
Best result: Hybrid search with Cohere reranker - 75.00
Most rerankers ended up improving the result with Cohere leading the pack. The highlight here would be AnswerDotAi ColBERT-small-v1 as it performs almost as good as Cohere reranker, which has been by far the best reranker across all our tests. Also, is more than 3x smaller than ColBERT-v2 so it can be run locally on CPU.
Conclusion
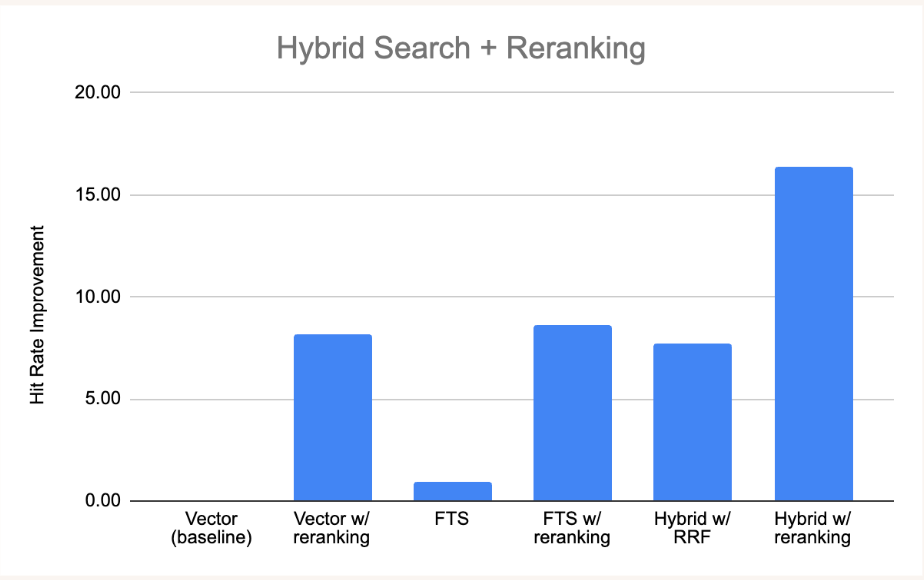
Our experiments on the SQuAD and Llama2-review datasets demonstrated significant improvements in model performance using these techniques. Specifically, we observed an 11% increase in accuracy on SQuAD (from 81.22% to 92.35%) and a 16% increase in hit-rate on Llama2-review (from 58.63% to 75.00%). These methods are particularly effective in scenarios where a slight increase in query latency is acceptable, as they offer substantial gains in accuracy without sacrificing too much speed.
This study exclusively explored techniques to optimize the retriever's performance without requiring a complete dataset re-ingestion. These methods represent the most straightforward approaches to enhance accuracy. Reranker models, often overlooked due to their substantial latency during queries, are becoming more viable with the emergence of smaller, on-device models that can significantly reduce query time.
future work
A comprehensive evaluation of reranker performance would require a careful consideration of the trade-off between accuracy and latency. We intend to investigate this aspect in future studies. It's important to note that direct comparisons can be challenging, as some of the most effective rerankers are API-based, and their latency can fluctuate due to network factors.
Another important direction is evaluating other methods of improving retrieval performance like - fine-tuning embedding models, choosing the best embedding model architectures depending on the dataset types, the effect choosing various chunking techniques & other best practices involved. These methods are generally more disruptive compared to reranking & hybrid search, as they require complete data re-ingestion, but are useful in cases where low latency at query time is critical.
References
The benchmarking code was based on Ragged repo, that contains a bunch of utility functions for ingesting and evaluating retrievers.
 lancedb
lancedbIt allows you to simply run evaluations across multiple query-types, rerankers and embedding models powered by LanceDB. For example this is the evaluation code for SQuAD data with linear combination reranker.
from ragged.dataset import CSVDataset, SquadDataset
from ragged.rag import llamaIndexRAG
from ragged.metrics.retriever.hit_rate import HitRate
from lancedb.rerankers import LinearCombinationReranker
from ragged.search_utils import QueryType
import wandb
dataset = SquadDataset()
reranker = LinearCombinationReranker()
hit_rate = HitRate(dataset, embedding_registry_id="sentence-transformers", embed_model_kwarg={"name": "BAAI/bge-small-en-v1.5", "device": "cuda"})
query_types = [QueryType.HYBRID, QueryType.RERANK_VECTOR, QueryType.RERANK_FTS]
run = wandb.init(project="ragged_bench", name=f"linearcombination")
for query_type in query_types:
hr = hit_rate.evaluate(5, query_type=query_type, use_existing_table=use_existing_table)
run.log({f"{query_type}": hr.model_dump()[f"{query_type}"]})
wandb.finish()Note: The hit-rate eval in ragged, discards failed queries. So evaluation results with other implementations might be different. The purpose of this evaluation is to just show performance gains on a standard metrics that remains constant for all evaluations.
The llama2-review synthetic dataset was generated from llama-2-paper dataset on LLamahub using the datagen utils in ragged:
from ragged.dataset.gen.gen_retrieval_data import gen_query_context_dataset
fragged.dataset.gen.llm_calls import OpenAIInferenceClient
clinet = OpenAIInferenceClient()
df = gen_query_context_dataset(directory="data/source_files", inference_client=clinet)
print(df.head())
# save the dataframe
df.to_csv("data.csv")The public W&B dashboards for both these experiments can be found here.
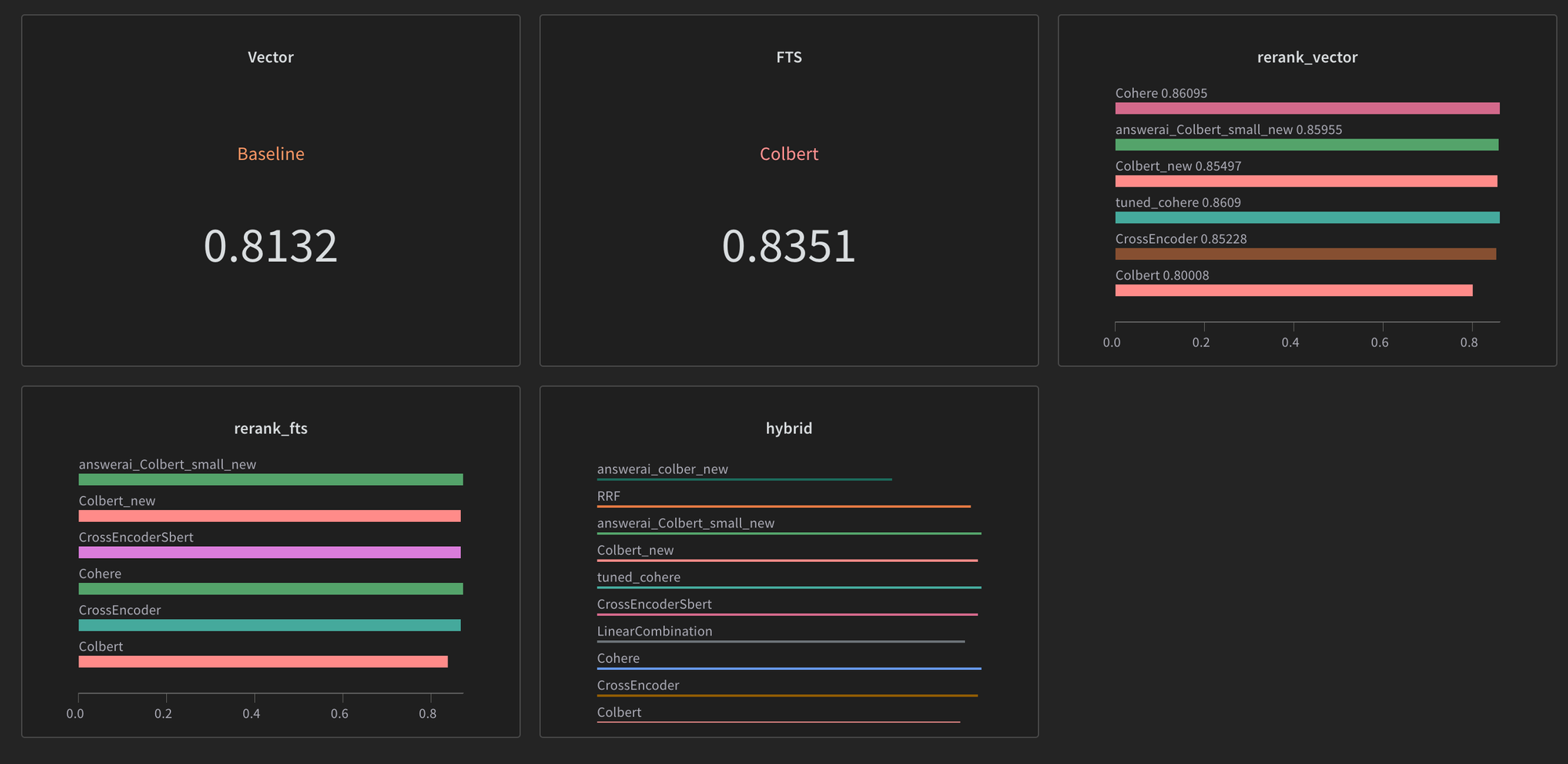
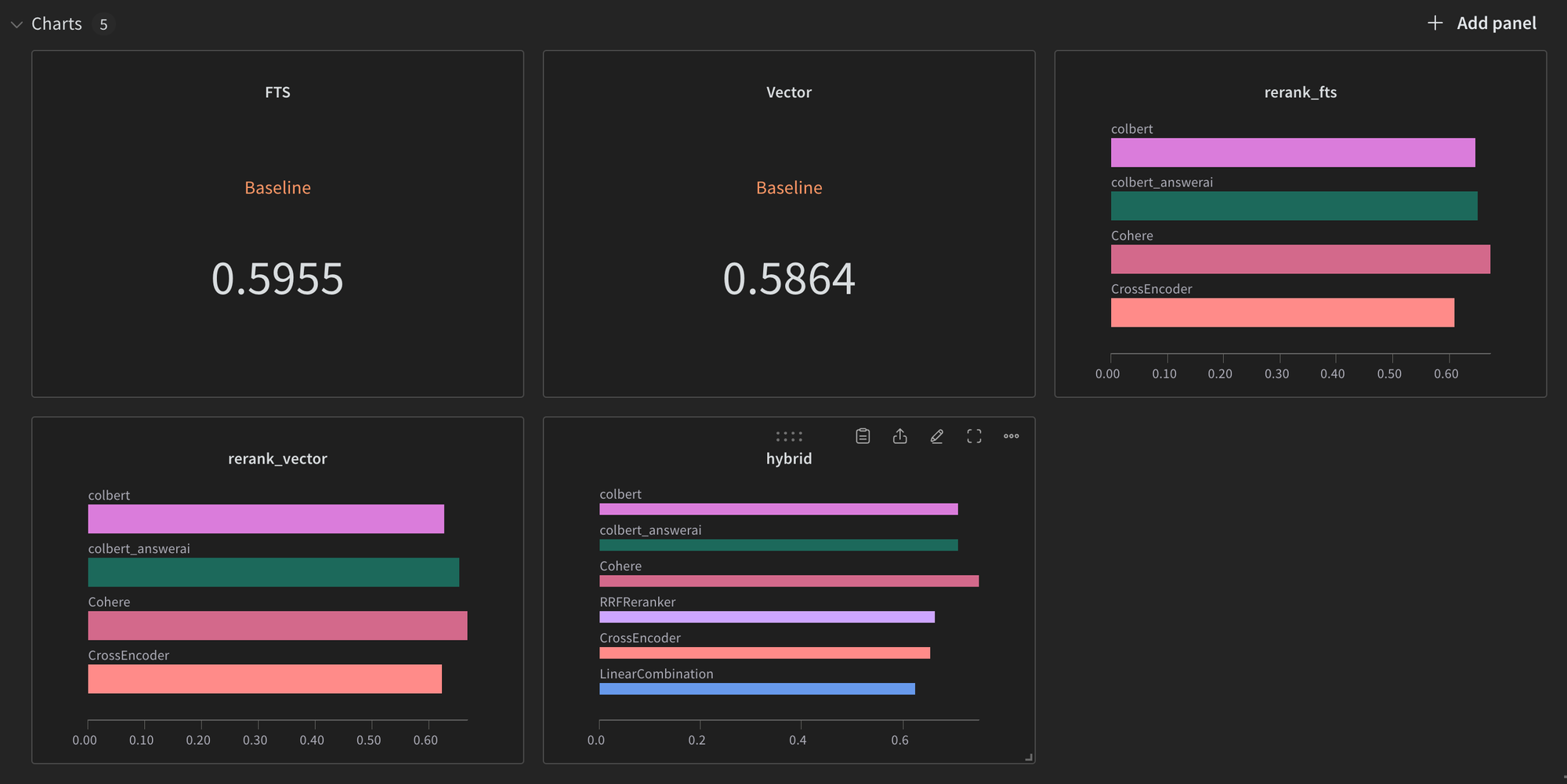
Useful Links
- AnswerDotAI Colbert-small-v1 announcement blog, HF hub
- LanceDB Hybrid search & Reranking
- LanceDB embedding API