by Kaushal Choudhary
One of the most exciting areas of research in deep learning currently is multi-modality and its applications. Kick-started by open sourcing of the CLIP model by OpenAI, multi-modal capabilities have evolved rapidly over the span of last couple of years. This primer covers 3 multi-modal applications built using CLIP powered by LanceDB as vector store.
- Multi-Modal Search using CLIP and LanceDB
- Turning that into Gradio application
- Multi-Modal Video Search

Overview
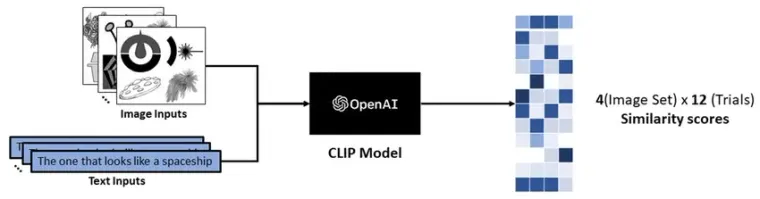
In the above picture you can see the CLIP model(Contrastive Language-Image Pre-Training), which is trained on humongous corpus of image-text pairs. This is model on which we are going to focus on this blog.
So, let’s jump right to Code.
First, we will discuss about the Multi-Modal Search using CLIP.
We will be using keywords, SQL commands and Embeddings to search the most relevant image.
Notebook Walk through
Example I : Multi-Modal Search
Follow this Colab along.
Let’s dive right into the code.
This will help you understand CLIP model even better.
We will be using the Animals dataset from Huggingface.
Here we are loading the CLIP model from GitHub, unlike using Huggingface transformers from before.
%pip install pillow datasets lancedb
%pip install git+https://github.com/openai/CLIP.gitLoading the dataset
dataset = load_dataset("CVdatasets/ImageNet15_animals_unbalanced_aug1", split="train")The dataset only labels the images with numbers, which is not very easy to understand for us. So, we will create an enum to map the numbers with class names.
#creating a class to map all the classes
class Animal(Enum):
italian_greyhound = 0
coyote = 1
beagle = 2
rottweiler = 3
hyena = 4
greater_swiss_mountain_dog = 5
Triceratops = 6
french_bulldog = 7
red_wolf = 8
egyption_cat = 9
chihuahua = 10
irish_terrier = 11
tiger_cat = 12
white_wolf = 13
timber_wolf = 14
print(dataset[0])
print(Animal(dataset[0]['labels']).name)We will be using 32 bit precision pretrained ViT (vision transformer) from CLIP.
import clip
import torch
#use GPU if available
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)We are going to create a image embedding function here, so it can be fed into LanceDB. Also, we want the embeddings to be a standard list, so we are converting the Tensor array into Numpy array and then list.
We are using the encode_image function here to embed the image.
# embed the image
def embed(img):
image = preprocess(img).unsqueeze(0).to(device)
embs = model.encode_image(image)
return embs.detach().cpu().numpy()[0].tolist()We are going to create a PyArrow schema and enter the data into LanceDB.
# define a schema for the lancedb table
schema = pa.schema(
[
pa.field("vector", pa.list_(pa.float32(), 512)),
pa.field("id", pa.int32()),
pa.field("label", pa.int32()),
])
tbl = db.create_table("animal_images", schema=schema)Let’s append the data to the table.
import pyarrow as pa
#create the db with defined schema
db = lancedb.connect('./data/tables')
schema = pa.schema(
[
pa.field("vector", pa.list_(pa.float32(), 512)),
pa.field("id", pa.int32()),
pa.field("label", pa.int32()),
])
tbl = db.create_table("animal_images", schema=schema, mode="overwrite")
#append the data into the table
data = []
for i in tqdm(range(1, len(dataset))):
data.append({'vector': embed(dataset[i]['img']), 'id': i, 'label': dataset[i]['labels']})
tbl.add(data)
#converting to pandas for better visibility
tbl.to_pandas()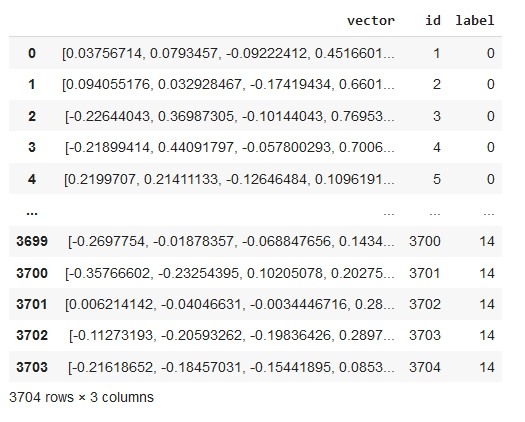
Now to test the image search, a good practice would be to check with the validation set first.
#load the dataset
test = load_dataset("CVdatasets/ImageNet15_animals_unbalanced_aug1", split="validation")#display the data along with length
print(len(test))
print(test[100])
print(Animal(test[100]['labels']).name)
test[100]['img']the results should be something like this:
To search the table, we can use this way
- Embed the image(s) we want
- Calling the search function
- Returning a Pandas DataFrame.
embs = embed(test[100]['img'])
#search the db after embedding the question(image)
res = tbl.search(embs).limit(1).to_df()
res
We can also put everything into a function for easier inference.
#creating an image search function
def image_search(id):
print(Animal(test[id]['labels']).name)
display(test[id]['img'])
res = tbl.search(embed(test[id]['img'])).limit(5).to_df()
print(res)
for i in range(5):
print(Animal(res['label'][i]).name)
data_id = int(res['id'][i])
display(dataset[data_id]['img'])Great Job! If you have come this far, I would like to congratulate you on your patience and dedication. Now, it gets just better.
We can begin the multi-modal text search.
We will use encode_text function here instead of encode_image.
#text embedding function
def embed_txt(txt):
text = clip.tokenize([txt]).to(device)
embs = model.encode_text(text)
return embs.detach().cpu().numpy()[0].tolist()
#check the length of the embedded text
len(embed_txt("Black and white dog"))Searching the table
#search through the database
res = tbl.search(embed_txt("a french_bulldog ")).limit(1).to_df()
res
print(Animal(res['label'][0]).name)
data_id = int(res['id'][0])
display(dataset[data_id]['img'])
Again, let’s combine everything into a function.
#making a text_search function to streamline the process
def text_search(text):
res = tbl.search(embed_txt(text)).limit(5).to_df()
print(res)
for i in range(len(res)):
print(Animal(res['label'][i]).name)
data_id = int(res['id'][i])
display(dataset[data_id]['img'])Great, we have used CLIP model for SQL, keyword, image and text search.
Example II : Multi-Modal Search using CLIP
Follow along with this Colab.
Loading the data. We will use diffusiondb data already stored in a S3 bucket.
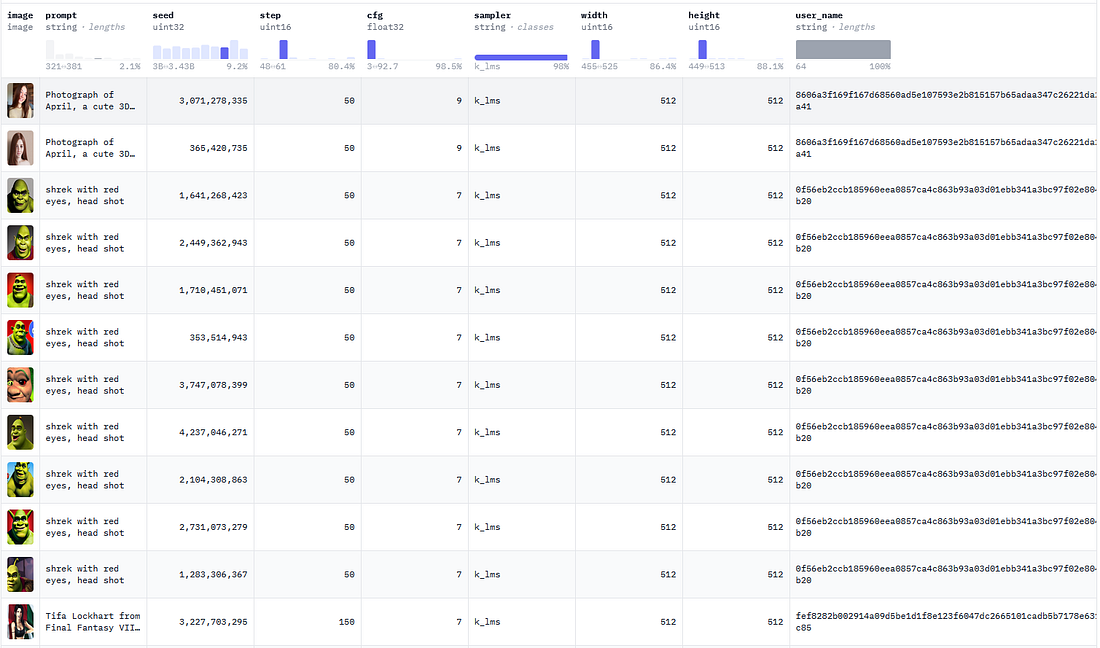
!wget https://eto-public.s3.us-west-2.amazonaws.com/datasets/diffusiondb_lance.tar.gz
!tar -xvf diffusiondb_lance.tar.gz
!mv diffusiondb_test rawdata.lanceCreate and open the LanceDB table.
import pyarrow.compute as pc
import lance
db = lancedb.connect("~/datasets/demo")
if "diffusiondb" in db.table_names():
tbl= db.open_table("diffusiondb")
else:
# First data processing and full-text-search index
data = lance.dataset("rawdata.lance/diffusiondb_test").to_table()
# remove null prompts
tbl = db.create_table("diffusiondb", data.filter(~pc.field("prompt").is_null()), mode="overwrite")
tbl.create_fts_index(["prompt"])Creating the CLIP Embeddings, for the text. If you want to know more about embeddings, you can read more about them here.
from transformers import CLIPModel, CLIPProcessor, CLIPTokenizerFast
MODEL_ID = "openai/clip-vit-base-patch32"
tokenizer = CLIPTokenizerFast.from_pretrained(MODEL_ID)
model = CLIPModel.from_pretrained(MODEL_ID)
processor = CLIPProcessor.from_pretrained(MODEL_ID)
Crea
def embed_func(query):
inputs = tokenizer([query], padding=True, return_tensors="pt")
text_features = model.get_text_features(**inputs)
return text_features.detach().numpy()[0]Let’s see the schema, and the data inside the LanceDB table.
tbl.schema
tbl.to_pandas().head()
Now, to properly visualize our embeddings and data, we will create a Gradio Interface. Let’s build some utility search functions beforehand.
#find the image vectors from the database
def find_image_vectors(query):
emb = embed_func(query)
code = (
"import lancedb\n"
"db = lancedb.connect('~/datasets/demo')\n"
"tbl = db.open_table('diffusiondb')\n\n"
f"embedding = embed_func('{query}')\n"
"tbl.search(embedding).limit(9).to_df()"
)
return (_extract(tbl.search(emb).limit(9).to_df()), code)
#find the image keywords
def find_image_keywords(query):
code = (
"import lancedb\n"
"db = lancedb.connect('~/datasets/demo')\n"
"tbl = db.open_table('diffusiondb')\n\n"
f"tbl.search('{query}').limit(9).to_df()"
)
return (_extract(tbl.search(query).limit(9).to_df()), code)
#using SQL style commands to find the image
def find_image_sql(query):
code = (
"import lancedb\n"
"import duckdb\n"
"db = lancedb.connect('~/datasets/demo')\n"
"tbl = db.open_table('diffusiondb')\n\n"
"diffusiondb = tbl.to_lance()\n"
f"duckdb.sql('{query}').to_df()"
)
diffusiondb = tbl.to_lance()
return (_extract(duckdb.sql(query).to_df()), code)
#extract the image
def _extract(df):
image_col = "image"
return [(PIL.Image.open(io.BytesIO(row[image_col])), row["prompt"]) for _, row in df.iterrows()]Let’s set up the Gradio Interface.
import gradio as gr
#gradio block
with gr.Blocks() as demo:
with gr.Row():
with gr.Tab("Embeddings"):
vector_query = gr.Textbox(value="portraits of a person", show_label=False)
b1 = gr.Button("Submit")
with gr.Tab("Keywords"):
keyword_query = gr.Textbox(value="ninja turtle", show_label=False)
b2 = gr.Button("Submit")
with gr.Tab("SQL"):
sql_query = gr.Textbox(value="SELECT * from diffusiondb WHERE image_nsfw >= 2 LIMIT 9", show_label=False)
b3 = gr.Button("Submit")
with gr.Row():
code = gr.Code(label="Code", language="python")
with gr.Row():
gallery = gr.Gallery(
label="Found images", show_label=False, elem_id="gallery"
).style(columns=[3], rows=[3], object_fit="contain", height="auto")
b1.click(find_image_vectors, inputs=vector_query, outputs=[gallery, code])
b2.click(find_image_keywords, inputs=keyword_query, outputs=[gallery, code])
b3.click(find_image_sql, inputs=sql_query, outputs=[gallery, code])
demo.launch()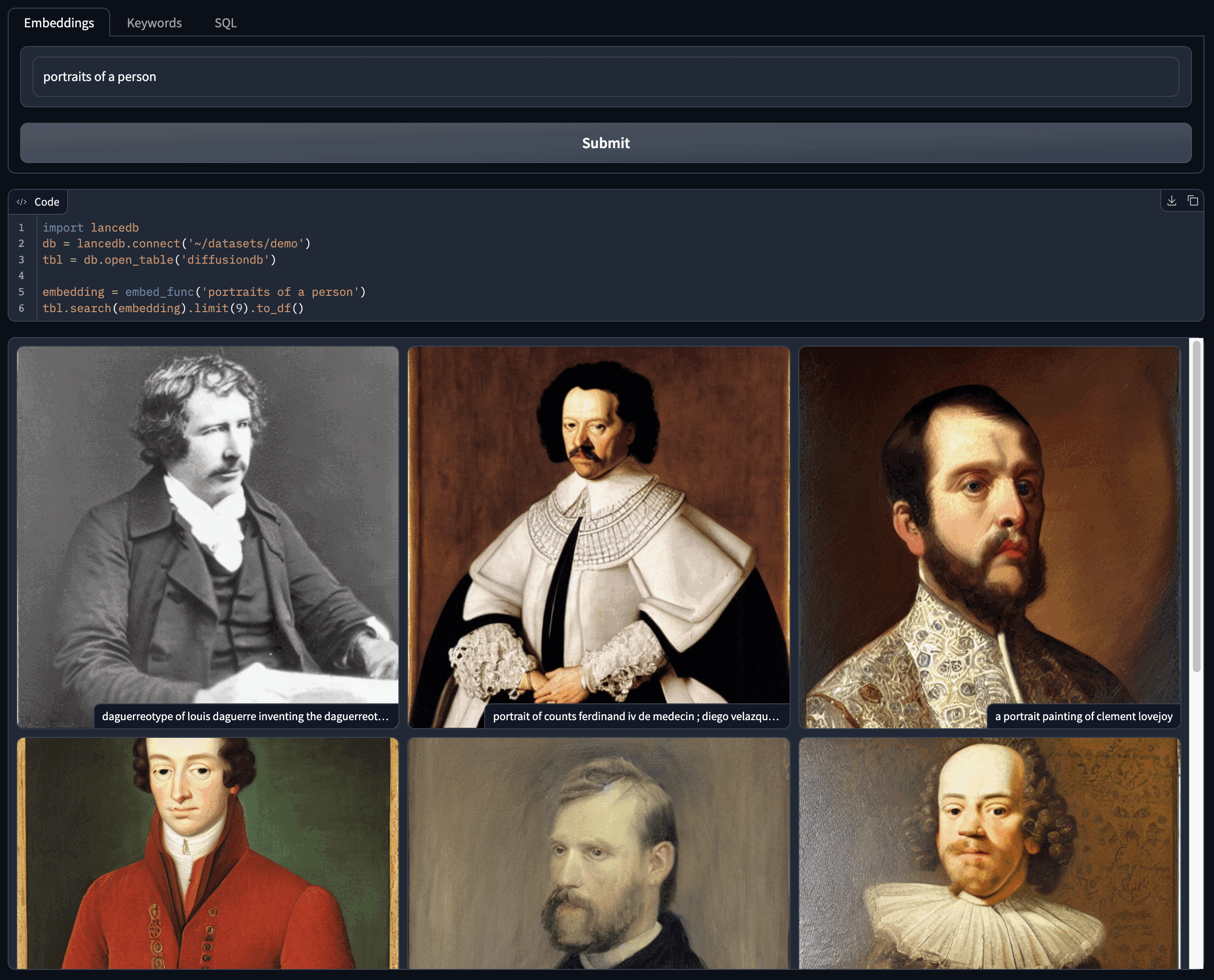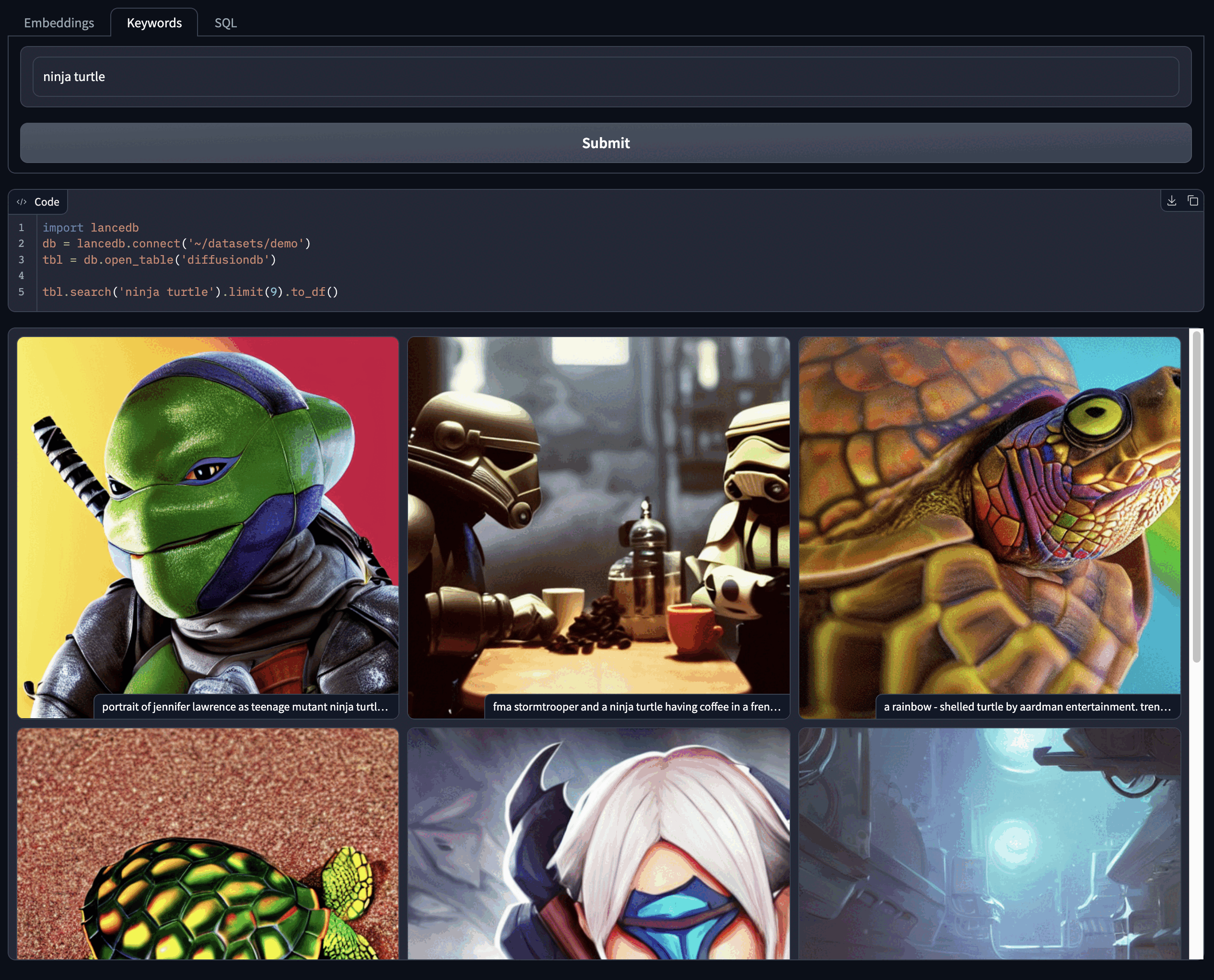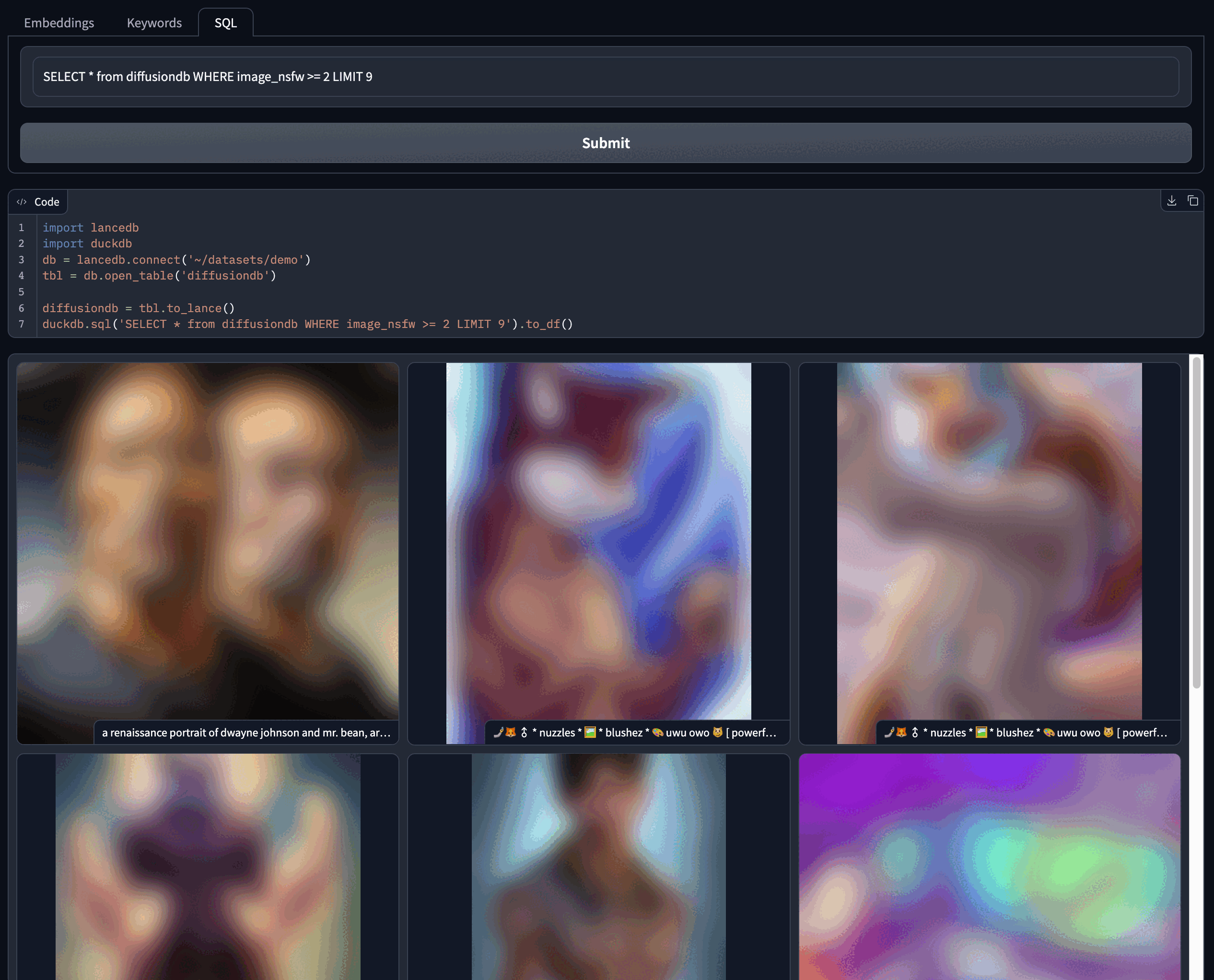
We can also search through Image and Text.
Example III : Multi-Modal Video Search
We will now use it to search videos.
For brevity, I’m going to focus on the essential part here.
So, kindly follow along this Colab for full exposure.
We have already made a tar file consisting the data in Lance Format.
#getting the data
!wget https://vectordb-recipes.s3.us-west-2.amazonaws.com/multimodal_video_lance.tar.gz
!tar -xvf multimodal_video_lance.tar.gz
!mkdir -p data/video-lancedb
!mv multimodal_video.lance data/video-lancedb/Create the Table
#intialize the db and open a table
db = lancedb.connect("data/video-lancedb")
tbl = db.open_table("multimodal_video")CLIP model with tokenizer, processor, and the embedding function
from transformers import CLIPModel, CLIPProcessor, CLIPTokenizerFast
MODEL_ID = "openai/clip-vit-base-patch32"
#load the tokenizer and processor for CLIP model
tokenizer = CLIPTokenizerFast.from_pretrained(MODEL_ID)
model = CLIPModel.from_pretrained(MODEL_ID)
processor = CLIPProcessor.from_pretrained(MODEL_ID)
#embedding function for the query
def embed_func(query):
inputs = tokenizer([query], padding=True, return_tensors="pt")
text_features = model.get_text_features(**inputs)
return text_features.detach().numpy()[0]We will be using Gradio, so let’s define some search utility functions beforehand.
#function to find the vectors most relevant to a video
def find_video_vectors(query):
emb = embed_func(query)
code = (
"import lancedb\n"
"db = lancedb.connect('data/video-lancedb')\n"
"tbl = db.open_table('multimodal_video')\n\n"
f"embedding = embed_func('{query}')\n"
"tbl.search(embedding).limit(9).to_df()"
)
return (_extract(tbl.search(emb).limit(9).to_df()), code)
#function to find the search for the video keywords from lancedb
def find_video_keywords(query):
code = (
"import lancedb\n"
"db = lancedb.connect('data/video-lancedb')\n"
"tbl = db.open_table('multimodal_video')\n\n"
f"tbl.search('{query}').limit(9).to_df()"
)
return (_extract(tbl.search(query).limit(9).to_df()), code)
#create a SQL command to retrieve the video from the db
def find_video_sql(query):
code = (
"import lancedb\n"
"import duckdb\n"
"db = lancedb.connect('data/video-lancedb')\n"
"tbl = db.open_table('multimodal_video')\n\n"
"videos = tbl.to_lance()\n"
f"duckdb.sql('{query}').to_df()"
)
videos = tbl.to_lance()
return (_extract(duckdb.sql(query).to_df()), code)
#extract the video from the df
def _extract(df):
video_id_col = "video_id"
start_time_col = "start_time"
grid_html = '<div style="display: grid; grid-template-columns: repeat(3, 1fr); grid-gap: 20px;">'
for _, row in df.iterrows():
iframe_code = f'<iframe width="100%" height="315" src="https://www.youtube.com/embed/{row[video_id_col]}?start={str(row[start_time_col])}" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>'
grid_html += f'<div style="width: 100%;">{iframe_code}</div>'
grid_html += '</div>'
return grid_htmlSetting up the Gradio Interface
import gradio as gr
#gradio block
with gr.Blocks() as demo:
gr.Markdown('''
# Multimodal video search using CLIP and LanceDB
We used LanceDB to store frames every thirty seconds and the title of 13000+ videos, 5 random from each top category from the Youtube 8M dataset.
Then, we used the CLIP model to embed frames and titles together. With LanceDB, we can perform embedding, keyword, and SQL search on these videos.
''')
with gr.Row():
with gr.Tab("Embeddings"):
vector_query = gr.Textbox(value="retro gaming", show_label=False)
b1 = gr.Button("Submit")
with gr.Tab("Keywords"):
keyword_query = gr.Textbox(value="ninja turtles", show_label=False)
b2 = gr.Button("Submit")
with gr.Tab("SQL"):
sql_query = gr.Textbox(value="SELECT DISTINCT video_id, * from videos WHERE start_time > 0 LIMIT 9", show_label=False)
b3 = gr.Button("Submit")
with gr.Row():
code = gr.Code(label="Code", language="python")
with gr.Row():
gallery = gr.HTML()
b1.click(find_video_vectors, inputs=vector_query, outputs=[gallery, code])
b2.click(find_video_keywords, inputs=keyword_query, outputs=[gallery, code])
b3.click(find_video_sql, inputs=sql_query, outputs=[gallery, code])
demo.launch()
Phew, that was a long learning session. Hope you guys were as excited as I was while writing this.
Visit our GitHub and if you wish to learn more about LanceDB python and Typescript library.
For more such applied GenAI and VectorDB applications, examples and tutorials visit VectorDB-Recipes.
Lastly, for more information and updates, follow our LinkedIn and Twitter.