Improved Contextual Retrieval over large Documents for RAG applications
The pronoun is the King (or Queen), and so is the Context. I hope the previous line gave you the gist that, given the right context, you can use your brain or LLM more effectively to produce even better outcomes. In terms of RAG pipelines that we know and use, there are some inherent issues for long documents, especially Context loss.
Let's take the example of a long document where the first paragraph talks about Messi, Football, Barca, and a lot of things. The second paragraph talks in pronouns about Messi's unmatched numbers and the third paragraph, it's all about the club's stats using "it", "them" etc. We make the chunks out of documents, embed each of those as usual, and search.
Issue? Given a query:
How many years did Messi play for Barca?
How do you think the chunks would come out? There could be a sentence somewhere "He was creating history there for 18 Years". Since there is no direct info and relation given within consecutive sentences, trust me, there's going to be a lot of problems getting the right context as these things are spanning over multiple paragraphs and our traditional RAG won't be able to make a relation for "he" "Messi" "them". Solution?
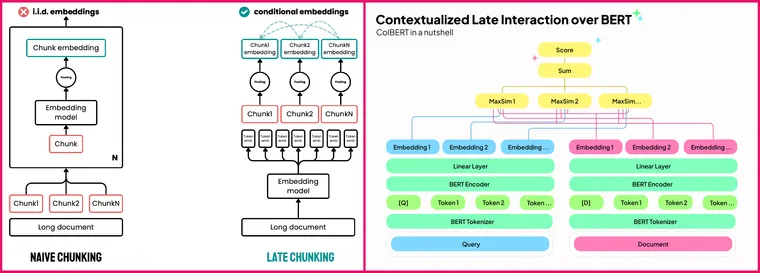
ColBERT: Late Interaction
Don't get confused by the Late Chunking topic in this blog. In this idea, what we do is:
- Pass the Whole Document to the Model
- Get
Token Embeddingfor each token - Similarly, get Token Embedding for each token in the query
- Take the maximum similarity between each token of query to the document
- Add those and retrieve
Nice and easy but with a twist here. You see, in the Vanilla model if there are 10 chunks for a document and the model embedding size is 512, we'll get num_chunks x 512 what you search for 1x512 query vector. If we see the same thing here in Colbert, it becomes num_document_tokens x 512 for document and then you do the maximum similarity with num_query_token x 512 and then do the final retrieval.
Two problems arise:
- Huge space requirement for saving the vectors for each token in the document
- Computational Overhead for getting the similarity
So what now?
Late Chunking

Researchers from Jina AI published a paper that seems to be the middle ground for both issues. The idea is simple:
- Take ANY model which is capable of doing Mean Pooling and (preferable) having a longer context window
- Make the chunks out of the text and record their starting and ending boundaries in the original document (Like in Vanilla Chunking)
- Pass the WHOLE document to the model and get the Token Embeddings (Like in Colbert)
- Now split and group those tokens according to the chunk they belong to. Easy to do as you already know the start and end boundaries of a chunk.
- Pool the embedding from each group to make 1 vector per Chunk (Like Vanilla Chunking)
Now think within a larger frame. The model knows the whole document and creates the embedding thinking of each word and line in context. So if a word Chunk-i is being referenced indirectly Chunk-j then the semantic meaning is already preserved in both so it gets the Colbert properties and the size is similar to the vanilla Chunking.
Let's see that in action with a live example


!pip install transformers datasets einops lancedb sentence-transformers -qqfrom transformers import AutoModel
from transformers import AutoTokenizer
import pandas as pd
import lancedb
pd.set_option('max_colwidth', 200)
# Any model which supports mean pooling can be used here. However, models with a large maximum context-length are preferred
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
def chunk_by_sentences(input_text: str, tokenizer: callable):
"""
Split the input text into sentences using the tokenizer
args:
input_text: The text snippet to split into sentences
tokenizer: The tokenizer to use
return: A tuple containing the list of text chunks and their corresponding token spans
"""
inputs = tokenizer(input_text, return_tensors='pt', return_offsets_mapping=True)
punctuation_mark_id = tokenizer.convert_tokens_to_ids('.')
sep_id = tokenizer.convert_tokens_to_ids('[SEP]')
token_offsets = inputs['offset_mapping'][0]
token_ids = inputs['input_ids'][0]
chunk_positions = [
(i, int(start + 1))
for i, (token_id, (start, end)) in enumerate(zip(token_ids, token_offsets))
if token_id == punctuation_mark_id
and (
token_offsets[i + 1][0] - token_offsets[i][1] > 0
or token_ids[i + 1] == sep_id
)
]
chunks = [
input_text[x[1] : y[1]]
for x, y in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)
]
span_annotations = [
(x[0], y[0]) for (x, y) in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)
]
return chunks, span_annotations
# -------------------------------
def late_chunking(model_output, span_annotation: list, max_length=None):
token_embeddings = model_output[0]
outputs = []
for embeddings, annotations in zip(token_embeddings, span_annotation):
if (
max_length is not None
): # remove annotations which go bejond the max-length of the model
annotations = [
(start, min(end, max_length - 1))
for (start, end) in annotations
if start < (max_length - 1)
]
pooled_embeddings = [
embeddings[start:end].sum(dim=0) / (end - start)
for start, end in annotations
if (end - start) >= 1
]
pooled_embeddings = [
embedding.detach().cpu().numpy() for embedding in pooled_embeddings
]
outputs.append(pooled_embeddings)
return outputsLet's create a dummy example by using indirect references
Germany is known for it's automative industry, jevlin throwers, football teams and a lot more things from the history. It's Capital is Berlin and is pronounced as 'ber-liin' in German. The capital is the largest city of Germany, both by area and by population. Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. The city is also one of the states of Germany, and is the third smallest state in the country in terms of area.
This one has 5 Chunks:
- "Germany is known for it's automative industry, jevlin throwers, football teams and a lot more things from the history."
- " It's Capital is Berlin and is pronounced as 'ber-liin' in German."
- " The capital is the largest city of Germany, both by area and by population."
- " Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits."
- " The city is also one of the states of Germany, and is the third smallest state in the country in terms of area."
Let's create both Vanilla and Late Chunking Table Embeddings
db = lancedb.connect("./db")
vanilla_chunk_embeddings = model.encode(chunks)
vanilla_data = []
for index, chunk in enumerate(chunks):
vanilla_data.append(
{ "text": chunk,
"vector": vanilla_chunk_embeddings[index],
}
)
vanilla_table = db.create_table("vanilla_table", data=vanilla_data)
# -------------------------------
inputs = tokenizer(dummy_long_document, return_tensors='pt')
model_output = model(**inputs)
late_chunk_embeddings = late_chunking(model_output, [span_annotations])[0]
late_chunk_data = []
for index, chunk in enumerate(chunks):
late_chunk_data.append(
{ "text": chunk,
"vector": late_chunk_embeddings[index],
}
)
late_chunk_table = db.create_table("late_chunk_table", data=late_chunk_data)Now let's take 3 Queries that test the idea to the core:
QUERY_EMBED_1 = model.encode('What are some of the attributes about the capital of a country whose Oktoberfest is famous?')
QUERY_EMBED_2 = model.encode('What are some of the attributes about capital of Germany?')
QUERY_EMBED_3 = model.encode('What are some of the attributes about Berlin?')
METRIC = "cosine" # "cosine" "l2" "dot"Want to get surprised?
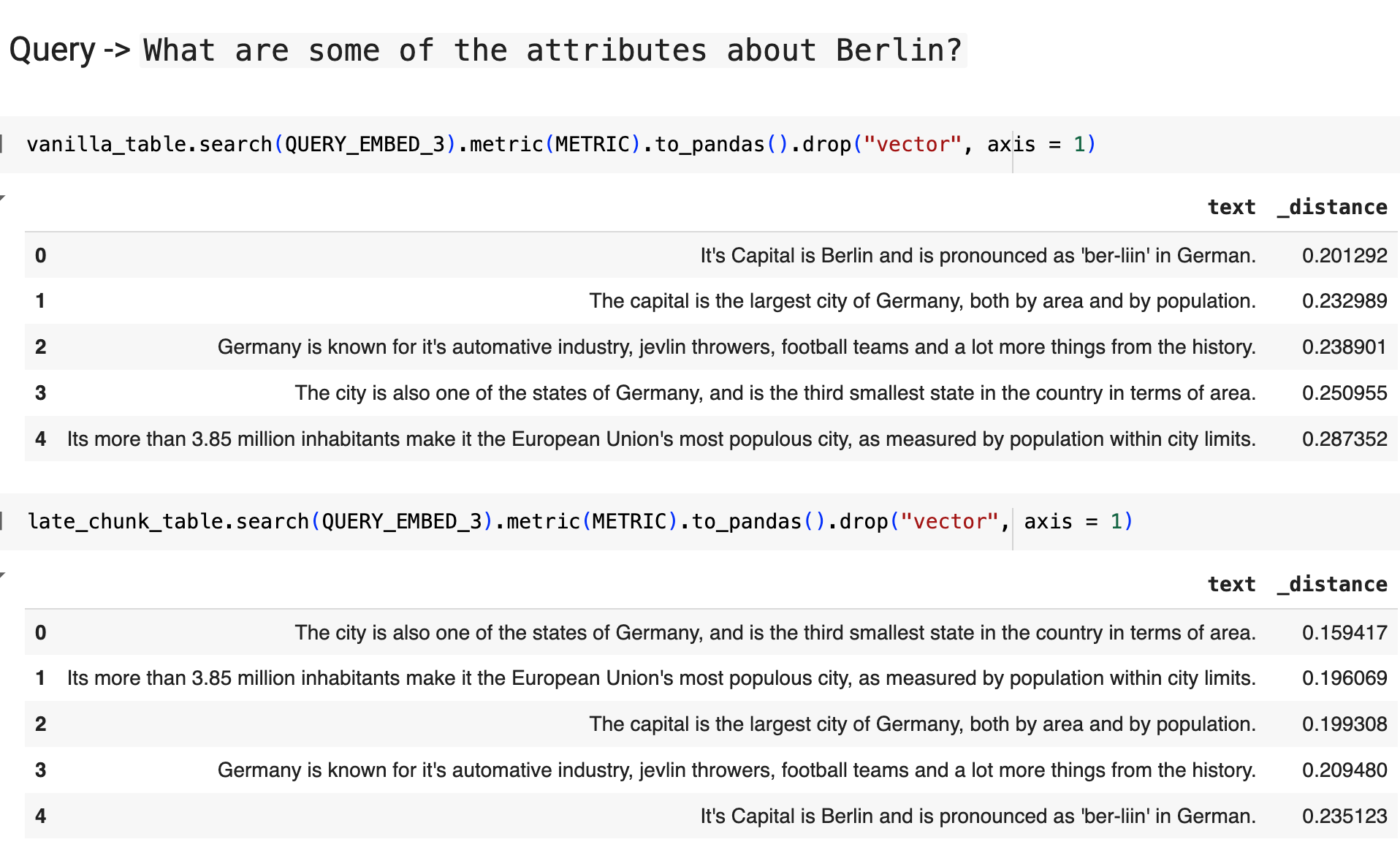
Did you notice something?
You see, in the Vanilla Chunking, in the 3rd query where Berlin is explicitly mentioned, the naive (Vanilla) chunking gave Top-3 results where there are no real specifications mentioned about Berlin BUT only the word is used.
But when you look at the Late chunking, Top-3 results are specifically about the specifications even though the word is out of scope.
Also, the main thing to look at is the cosine similarity where in the Naive chunking, the chunk:
Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.
is having last place with a distance 0.28 is very relevant to the query and for a turn of surprise, it has more distance than the chunk:
Germany is known for it's automative industry, jevlin throwers, football teams and a lot more things from the history
which has a distance of 0.23
On the other hand, Late Chunking gave reasonable distances and rankings. Also, the distance for the best result is far off in the distance (0.2) while in the Late chunking, the minimum distance is (0.15).
Conclusion
From the results of the above queries, It is understood that Late chunking inherently tends to work as a semantic reranker.