
A lot has happened in the last few months in AI. Let's look at what's new with document retrieval.

Late Interaction
Retrieval models rely on embedding similarity between query and corpus(documents)
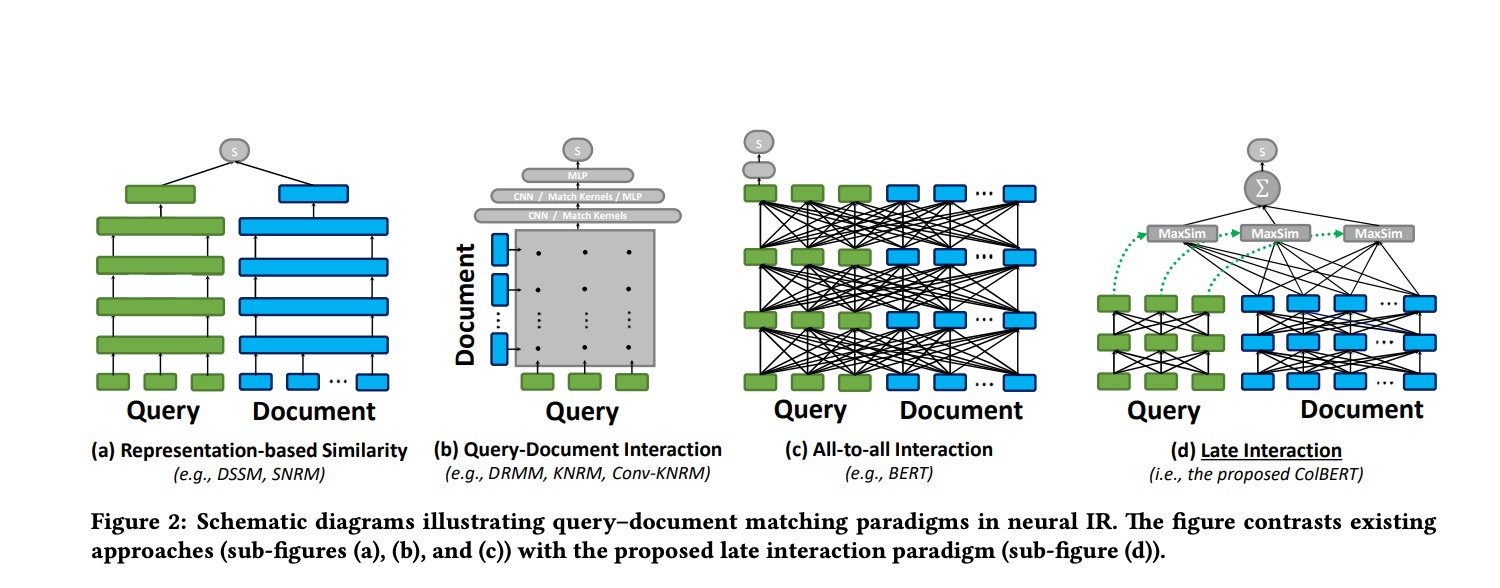
Representation-focused rankers independently compute an embedding for q and another for d and estimate relevance as a single similarity score between two vectors. Think of cosine similarity on bi-encoder outputs of doc and query.
Query-Document rankers Instead of summarizing q and d into individual embeddings, these rankers model word- and phrase-level relationships across q and d and match them using a deep neural network (e.g., with CNNs/MLPs). In the simplest case, they feed the neural network an interaction matrix that reflects the similarity between every pair of words across q and d.
All-to-all Interaction rankers is a more powerful interaction-based paradigm, which models the interactions between words within as well as across q and d at the same time, as in BERT’s transformer architecture. While interaction-based models tend to be superior for IR tasks, a representation-focused model—by isolating the computations among q and d—makes it possible to precompute document representations, greatly reducing the computational load per query.
Late interaction rankers offer a new architecture where every query embedding interacts with all document embeddings via a MaxSim operator, which computes maximum similarity (e.g., cosine similarity), and the scalar outputs of these operators are summed across query terms. This paradigm allows ColBERT to exploit deep LM-based representations while shifting the cost of encoding documents offline and amortizing the cost of encoding the query once across all ranked documents.
ColBert creates a vector index of all documents in the corpus offline, then computes the MaxSim during the query time.
Late interaction + VLMs = Vision retriever!
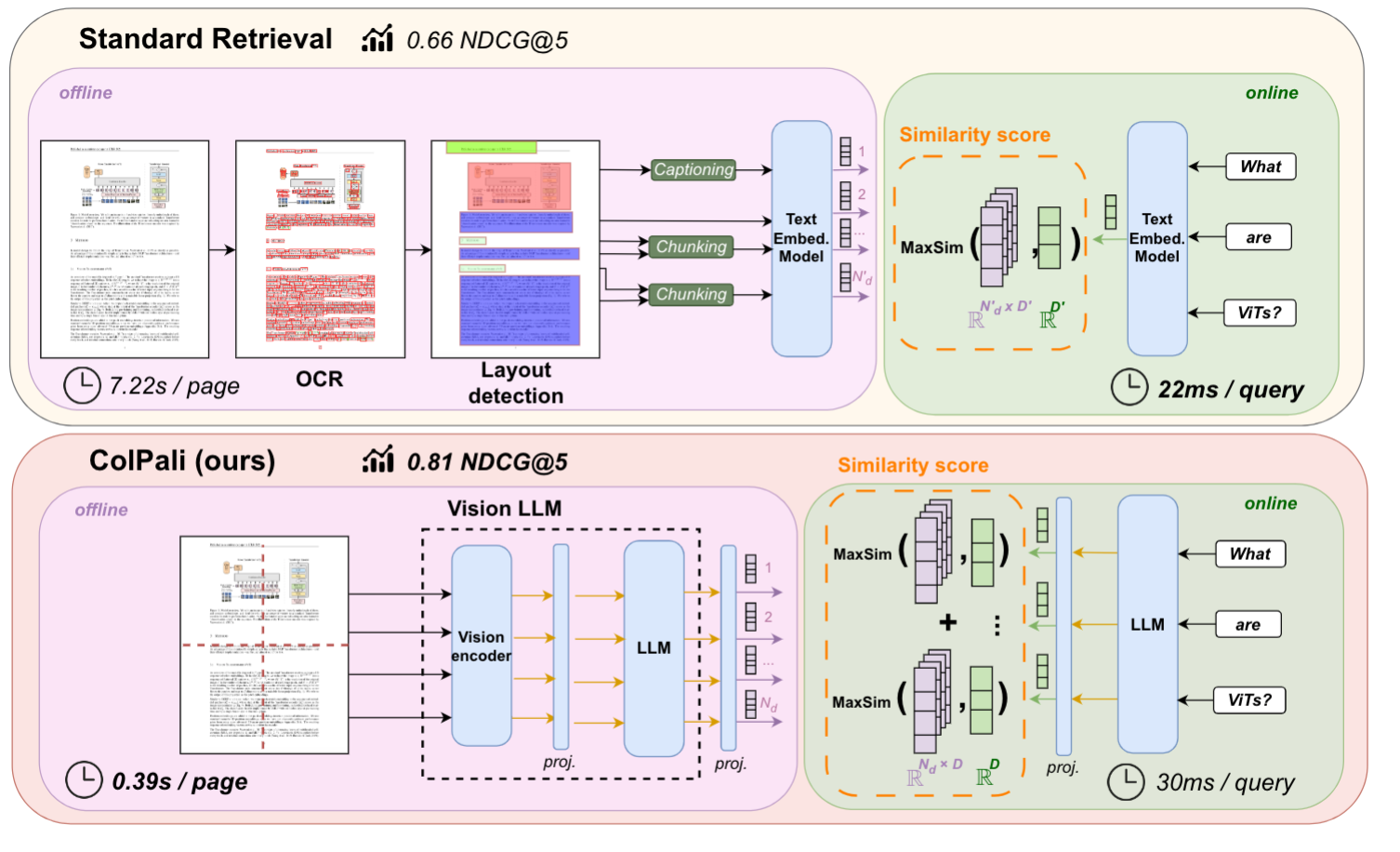
ColPali is a visual retriever model that combines the following:
- PaliGemma - A VLM combines SigLIP-So400m/14 vision encoder and Gemma-2B language model. It also introduces projection layers to map language model inputs to 128-dim vectors
- A late interaction mechanism based on ColBert
Like ColBert, ColPali works in 2 phases:
Offline:
- Each document input is processed through the vision encoder and in patches. Each patch is then passed through the projection layer to get its vector representation.
- Then these vectors are stored as multi-vector representations of the documents for retrieval at the query time
- Each document is divided into 1030 patches with each patch resulting in a 128-dim vector.
Online:
- At query time, the user input is encoded using a language model
- Using the late interaction mechanism, MaxSims are calculated between query and already embedding document patches.
- The similarity score of each patch is summer across the pages & the top K pages with maximum similarity score are returned as the final result
Let's try it out!
In this example, we'll make retrieval challenging by ingesting documents of very different genres:
- Investor relations/ Financial reports of Q2 2024 from:
- Apple
- Amazon
- Meta
- Alphabet
- Netflix
- Starbucks
- Naturo Volume 72
- Arabian Nights
- Children's short story collection.
- InraRed Cloud report
- Short Stories for Children by Cuentos para la clase de Inglés
You can also run it yourself in this colab walkthrough. The code is based on original work by Kyryl Truskovskyi which can be found here

Need for an efficient retriever.
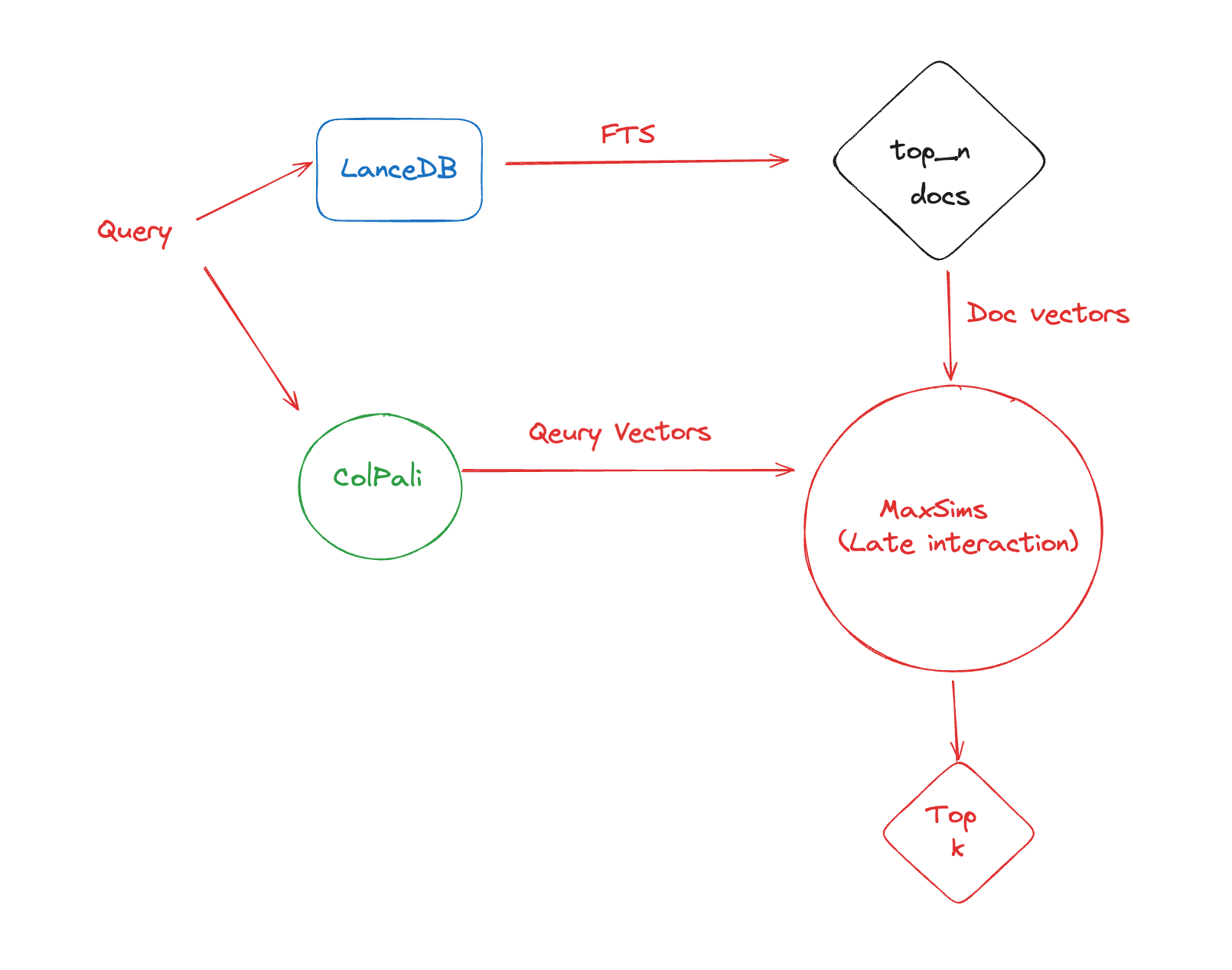
In this pipeline, building an efficient retriever is of utmost importance as each query is compared to each document, which is stored in patches. Moreover, efficiently storing and retrieving the document images allows us to store the data and metadata in the same place to retrieve it when passing it on to the generator in case of a RAG setting. Efficient multi-modal data storage and retrieval is where LanceDB shines. It offers strong compute-storage separation, providing fast random access for retrieval while being persisted in storage.
The codebase is a derivative work on vision-retriever. It adds support for better ingestion through batch iterators which allows ingesting large datasets into Lance without running out of memory, meaning you can store your documents, vectors, and metadata in the same place without running OOM and also get fast retrieval and added features that we'll see next.
Searching for relevant docs
Let's take a look at some of the query and retrieved document pairs to get an idea of ColPali's performance.
Retrieving the docs from the table and then performing MaxSims operation on them with a query will look something like this with LanceDB:
from colpali_engine.trainer.retrieval_evaluator import CustomEvaluator
def search(query: str, model, processor, top_k: int = 3):
qs = get_query_embedding(query=query, model=model, processor=processor)
# Retrieve all documents
r = table.search().limit(None).to_list()
def process_patch_embeddings(x):
patches = np.reshape(x['page_embedding_flatten'], x['page_embedding_shape'])
return torch.from_numpy(patches).to(torch.bfloat16)
all_pages_embeddings = [process_patch_embeddings(x) for x in r]
retriever_evaluator = CustomEvaluator(is_multi_vector=True)
scores = retriever_evaluator.evaluate_colbert([qs["embeddings"]], all_pages_embeddings)
top_k_indices = torch.topk(scores, k=top_k, dim=1).indices
results = []
for idx in top_k_indices[0]:
page = r[idx]
pil_image = base64_to_pil(page["image"])
result = {"name": page["name"], "page_idx": page["page_idx"], "pil_image": pil_image}
results.append(result)
return resultsThe device used for this experiment:
- GPU - Nvidia V100 16GB
- RAM - 30GB
Total documents pages ingested - 556
Retrieval
In this section, we'll see:
- Performance of ColPali in retrieving the correct document. In this case, it'll use MaxSim operation across ALL ingested document pages.
- Optimizing lookup time by reducing search space using LanceDB FTS ( ColPali as a FTS reranker )
- Optimizing lookup time by reducing search space using LanceDB Semantic search ( ColPali as a vector search reranker )
- First, we'll ask a question about the trends in model training costs. This should be covered in the infraRed cloud report doc.
query = "How do model training costs change over time?"
def search()
search_result = search(query=query, model=colpali, processor=processor, top_k=3)
search_result["image"][0]Time taken - 34 seconds
It got the exact doc that describes the training cost trend as a graph. This is especially interesting because we've ingested many documents from similar genres (financial reports of big tech and other organizations). Any decent VLM can interpret this to form a final response if it's an RAG setting.
While late interaction with ColPali allows you to compute the document patch-embedding offline ahead of query time, it still needs to perform MaxSim operation to calculate the similarity between a query and ALL documents, which is an expensive operation. As the number of documents grows, the total time taken will also increase proportionally. Of course, using a more powerful GPU will result in better performance but it'll still be relative.
Let's take a look at another example and then move on to some optimizations that can allow this workflow to be used in a real-world setting.
query = "What did the queen ask her magic mirror everyday?"Time taken - 30.50 seconds

Again, it got to the exact page where the evil queen from snow white asks the given question to her magic mirror.
Limitations
Using ColPali as a 1-step vision retriever greatly simplifies the process of document retrieval but without any additional optimizations, as the document index grows, the retrieval operation at query time will keep getting expensive. Let us now look at some ways to speed up retrieval by reducing the search space.
ColPali MaxSims as a Reranking step
There are a couple of hacks that can be used to reduce the search space by filtering out some results.
- If text field is available
In case you're able to extract the text from the pdf ( Here we're not referring to OCR. Some pdf encodings allow reading text directly from the file), you can create an FTS index on the text column to try and reduce the search space. This will effectively make the ColPali MaxSims operation a reranking step for FTS. In this example, we'll get the top 100 FTS matches, which brings down the search space to about 1/5th.
This is how the implementation would look like
def search(query: str, table_name: str, model, processor, db_path: str = "lancedb", top_k: int = 3, fts=False, limit=None):
qs = get_query_embedding(query=query, model=model, processor=processor)
# Search over all dataset
if fts:
# set 100 as the max limit if filtering / reducing
# search space
limit = limit or 100
r = table.search(query, query_type="fts").limit(limit)
else:
r = table.search().limit(limit)
r = r.to_list()
...
# Same as described above
...
return resultsLet's take a look at the result of the 2nd query.
query = "What did the queen ask her magic mirror everyday?"Time taken - 6.30 seconds

We get the expected result with the latency reduced to about 1/5th.
- Reducing the search space using a similarity search
A vision retriever pipeline ideally shouldn't be dependent on being able to parse the text from the documents as it defeats the purpose of being a 1-shot retrieval method.
Hypothesis
Remember, 128 dim vector projections are derived from the language model part of ColPali. Although query dim (in this case 25x128) isn't the same as the doc path embedding dim (1030x128). However because these are the representations of the same model, they might be able to capture the similarity between the query and the doc patches. So we can flatten them out, zero pad the query embeddings to match the doc patch embeddings, and run vector search to filter out the top_k and reduce the search space for ColPali MaxSims reranking.
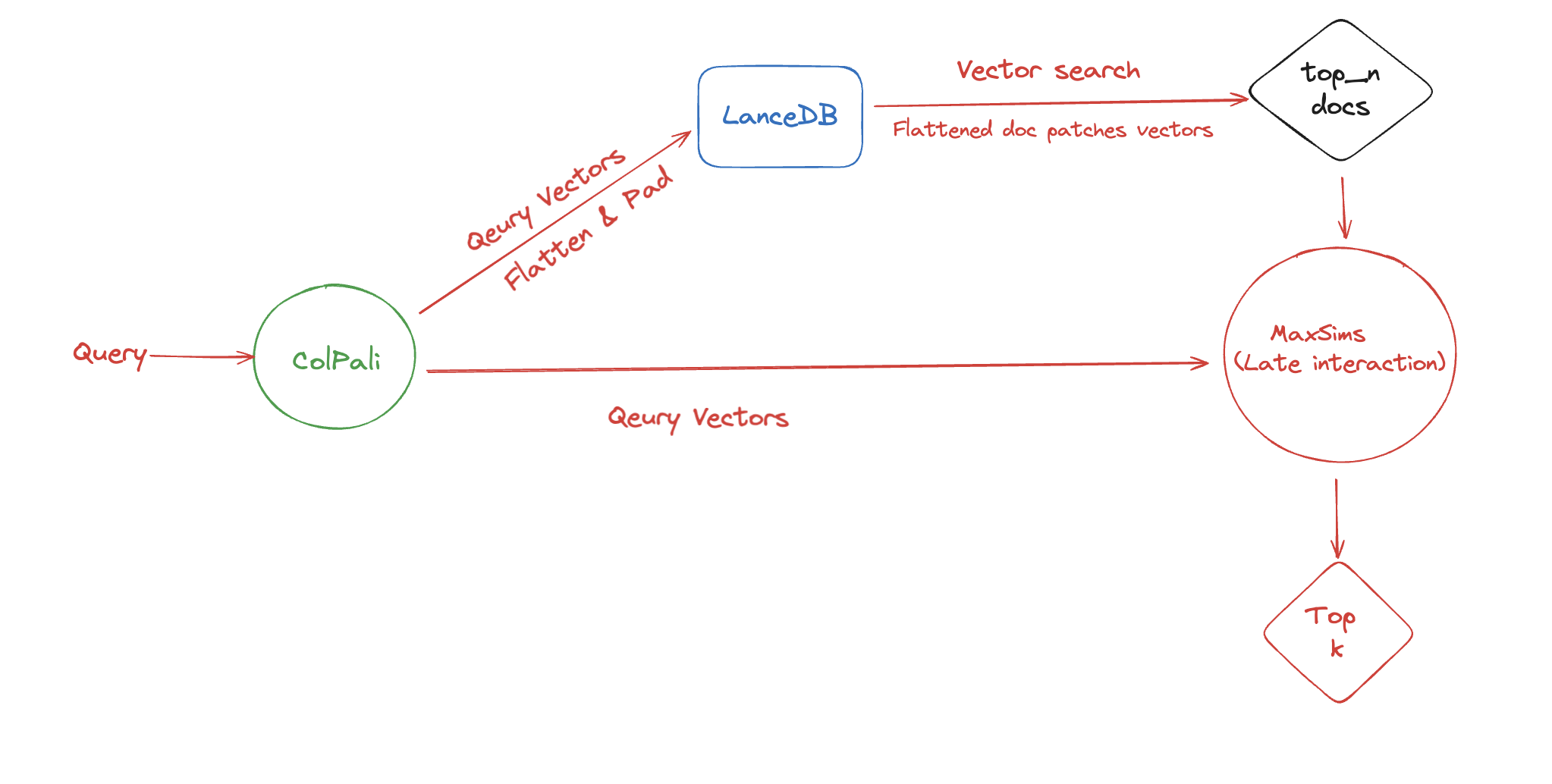
This'll look something like this:
def search(query: str, model, processor, top_k: int = 3, fts=False, vector=False, limit=None):
qs = get_query_embedding(query=query, model=model, processor=processor)
# Search over all dataset
if vector and fts:
raise ValueError("can't filter using both fts and vector")
if fts:
limit = limit or 100
r = table.search(query, query_type="fts").limit(limit)
elif vector:
limit = limit or 100
vec_q = flatten_and_zero_pad(qs["embeddings"],table.to_pandas()["page_embedding_flatten"][0].shape[0])
r = table.search(vec_q.float().numpy(), query_type="vector").limit(limit)
else:
r = table.search().limit(limit)
if where:
r = r.where(where)
r = r.to_list()
...
# Same as before
...
return results
Results:
Let's try the previous query and then a new one:
query = "What did the queen ask her magic mirror everyday?"Time taken = ~6 seconds

Let's run a couple of new tests and also verify the results are the same with and without pre-filtering with vector search.
Now, let's a question from one of the stories from the Arabian Nights, where a lady scatters some water around in a lake and the fishes turn into humans. Let's see if it can find that document.
Time taken ~ 6 seconds
query = "How did the fish become men, women, and children"
It does find the exact document!
Other strategies for reducing the search space
There are more obvious ways of reducing the search space with some prior information. For example, if you already know the document from which the query is requested, you can simply use filters.
Also, with a little bit of more processing on the offline indexing side, you classify the document genre and add that as another property when ingesting the docs.
The challenge of large-scale vision retrieval
ColPali is definitely a step function change in the document retrieval process. It greatly simplifies the process of indexing documents. OCR is a complex modeling challenge and can be a point of failure on its own. Chunking and embedding the texts from the OCR model again is another hyper-parameter to take care of. There are dedicated tools to analyze the visual layout of the contents of docs for better retrieval. ColPali as a vision retriever allows the elimination of these individual, error-prone methods while still being relatively efficient.
But making vision retrieval work on a large scale requires more than just a traditional vector index. Because of the high dimensionality of patch embeddings (1030x128), creating a vector index across a large-scale dataset is not feasible for an in-memory DB. Moreover, reducing search space by using BM25/FTS or efficient filtering, storing and retrieving actual image data is also required.
LanceDB shines when it comes to large-scale multi-modal applications. LanceDB is fundamentally different from other vector databases in that it is built on top of Lance, an open-source columnar data format designed for performant ML workloads and fast random access.
- Due to the design of Lance, LanceDB's indexing philosophy adopts a primarily disk-based indexing philosophy. It can also simply store and retrieve objects so you can have your vectors, metadata, as well patch-leveldataset files in the same place.
- Comes with native support for FTS and semantic search which allows efficient retrieval for multi-modal datasets as we've seen in this blog.
Future work
Vision retrieval with VLMs is a new retrieval technique and experiment results still pouring in. Multi-vector patch-level embeddings can capture document visual layout and semantic meaning of the text but indexing large vectors can be an expensive operations. In this blog, we've seen some methods of reducing the search space to speed up the retrieval process. Some other ways to optimize this would be the binarization of document embeddings to reduce the dimensionality of the vectors by 26 to 32 times for efficient storage and faster search, as covered in this detailed blog post by Jo from Vespa - https://blog.vespa.ai/retrieval-with-vision-language-models-colpali/
Try out this example -

Or others on vectorDB recipes.