
by Akash A. Desai
Welcome to our deep dive into Forward-Looking Active Retrieval Augmented Generation (FLARE), an innovative approach enhancing the accuracy and reliability of large language models (LLMs). we’ll explore how FLARE tackles the challenge of hallucination in LLMs, especially in complex, long-form content generation tasks.
Hallucination in LLMs refers to generating incorrect or baseless content. This issue becomes more pronounced in tasks involving extensive outputs, such as long-form question answering, open-domain summarization, and Chain of Thought reasoning. FLARE aims to mitigate these inaccuracies by integrating external, verified information during the generation process.
What is FLARE:
FLARE stands for Forward-Looking Active Retrieval Augmented Generation. It’s a methodology that supplements LLMs by actively incorporating external information as the model generates content. This process significantly reduces the risk of hallucination, ensuring the content is continuously checked and supported by external data.
Traditional Retrieval-Augmented Generation In traditional retrieval-augmented generation models, the approach is generally to perform a single retrieval at the beginning of the generation process. This method involves taking an initial query, for instance, “Summarize the Wikipedia page for Narendra Modi,” and retrieving relevant documents based on this query. The model then uses these documents to generate content. This approach, however, has its limitations, especially when dealing with long and complex texts.
Limitations of Traditional Methods:
- Single Retrieval: Once the initial documents are retrieved, the model continues to generate content based solely on this initial information.
- Absence of Flexibility: As the generation progresses, the model doesn’t update or retrieve new information to adapt to the evolving context of the generated content.
- Potential for outdated or Incomplete information: If new information becomes relevant as the text progresses, the model may not capture this due to its reliance on the initially retrieved documents.
- Multiple Retrievals: Utilise past context to retrieve additional information at a fixed interval. means every 10 words or 1 sentence They are going to retrieve doesn't matter if you want to retrieve it or not.
FLARE’s Methodology:
Multiple Retrievals: Instead of a fixed retrieval, FLARE uses multiple retrievals at different intervals & knows when to retrieve & what to retrieve.
when to retrieve: When LLM lacks the required knowledge & LLM generates low-probability tokens.
What to retrieve: it will consider what LLM intends to generate in the future.
Understanding FLARE’s Iterative Generation Process:
FLARE operates by iteratively generating a temporary next sentence, using it as a query to retrieve relevant documents, if they contain low-probability tokens, and regenerates the next sentence until reaches the end of the overall generation
There are two types of FLARE:
- FLARE Instruct: This mode prompts the model to generate specific queries for information retrieval. The model pauses generation, retrieves the necessary data, and then resumes, integrating the new information. let's understand this in the figure
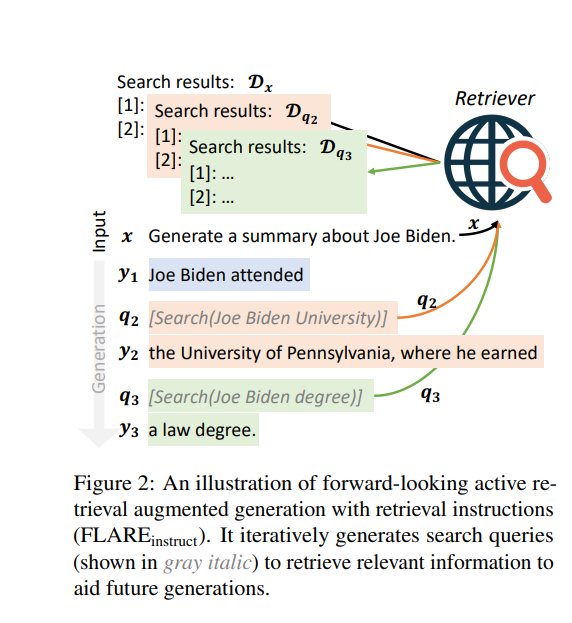
Imagine a scenario where an AI model is tasked with generating a summary about Joe Biden, prompted by a user’s input query. Here’s how the process unfolds
- User Query: The task begins with the user’s request: “Generate a summary about Joe Biden.”
- Initial Sentence Generation: The model starts crafting the content, generating an opening line like, “Joe Biden attended.”
- Focused Search Initiation: At this juncture, the model activates a search query, “[Search(Joe Biden University)].”
- Pausing and Searching: The content generation is temporarily paused. The model then deep dives into searching about “Joe Biden University.”
- Retrieval and Integration: Next, the model communicates with the retriever to fetch relevant data for “Joe Biden University.” It effectively retrieves and integrates information such as, “the University of Pennsylvania, where he earned.”
- Continued Search and Update: The process doesn’t stop here. The model again launches a search, this time with “[Search(Joe Biden degree)].” Following the same protocol, it retrieves and integrates new data, such as information about his law degree.
This iterative process, blending generation and retrieval, ensures that the AI model produces a well-informed and accurate summary, dynamically incorporating relevant and up-to-date information. This is how FLARE instruct is working.
now let's understand FLARE Direct
- FLARE Direct: Here, the model uses the generated content as a direct query for retrieval when it encounters tokens with low confidence. Let’s delve into this with an example:
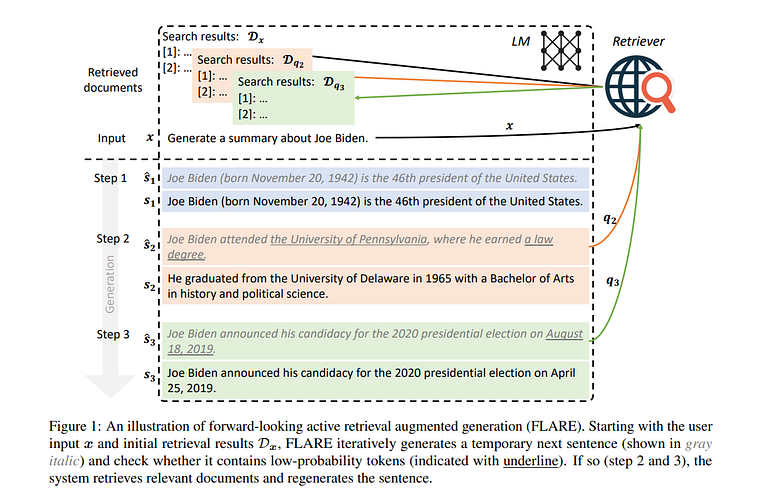
1. Initiating the Query: We start with a language model input: “Generate a summary about Joe Biden.”
- The model generates a response.

3. If the generated sentence is accurate and has high confidence, it is accepted as a correct sentence.

4. let’s say the model produces a sentence but with some low confidence (elements are highlighted) “the University of Pennsylvania” and “a law degree.” The model has very low confidence for these lines

now there are two methods to handle this issue
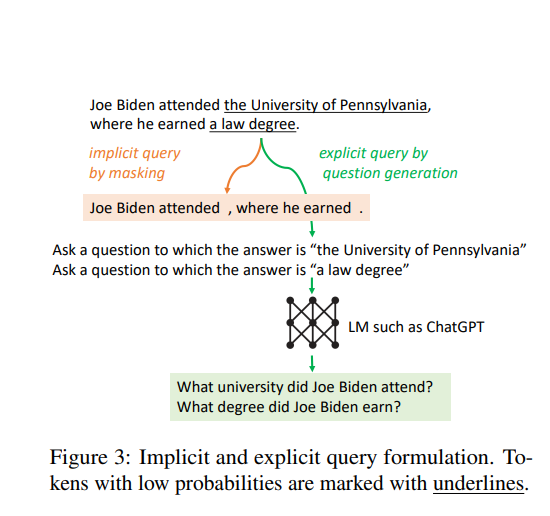
Addressing Low Confidence Information: To rectify or verify low-confidence information, FLARE Direct employs two approaches:
- Implicit Query by Masking (Highlighted in Orange): This involves identifying keywords or phrases in the sentence, such as “Joe Biden attended” and “where he earned.” The model then searches these key terms in its database (vectorDB) to retrieve relevant and accurate information.
- Explicit Query by Question Generation (Highlighted in Green): Here, the model is prompted to formulate specific questions related to the input query. Examples might include: “What university did Joe Biden attend?” and “What degree did Joe Biden earn?” These questions are then used to extract relevant data from the database, ensuring the information’s accuracy and relevance.
By employing these methods, FLARE Direct effectively refines and verifies the content, enhancing the accuracy and reliability of the generated summary.
To set up this chain, we will need three things:
- An LLM to generate the answer
- An LLM to generate hypothetical questions to use in retrieval
- A retriever to use to look up answers for
We need the LLM we use to produce answers to return log probabilities so we can detect uncertain tokens. Because of this, we STRONGLY suggest using the OpenAI wrapper (Note: not the ChatOpenAI wrapper, as it does not return log probabilities).
We can use any LLM to generate hypothetical questions for retrieval. In this notebook, we'll opt for ChatOpenAI since it's fast and cost-effective.
let's do some Hands-On coding
Below is the code for Gradio, you can run it on a local system. We are using arvixloader questions, so you can ask quetions to paper directly
Here is an example https://arxiv.org/pdf/2305.06983.pdf.
You need to pass this number to query 2305.06983 and then you can ask any questions based on the paper.
Other important parameters to understand:
max_generation_len: The maximum number of tokens to generate before stopping to check if any are uncertainmin_prob: Any tokens generated with probability below this will be considered uncertain
from langchain import PromptTemplate, LLMChain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import LanceDB
from langchain.document_loaders import ArxivLoader
from langchain.chains import FlareChain
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
import os
import gradio as gr
import lancedb
from io import BytesIO
from langchain.llms import OpenAI
import getpass
# pass your api key
os.environ["OPENAI_API_KEY"] = "sk-yourapikeyforopenai"
llm = OpenAI()
os.environ["OPENAI_API_KEY"] = "sk-yourapikeyforopenai"
llm = OpenAI()
model_name = "BAAI/bge-large-en"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
# here is example https://arxiv.org/pdf/2305.06983.pdf
# you need to pass this number to query 2305.06983
# fetch docs from arxiv, in this case it's the FLARE paper
docs = ArxivLoader(query="2305.06983", load_max_docs=2).load()
# instantiate text splitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=150)
# split the document into chunks
doc_chunks = text_splitter.split_documents(docs)
# lancedb vectordb
db = lancedb.connect('/tmp/lancedb')
table = db.create_table("documentsai", data=[
{"vector": embeddings.embed_query("Hello World"), "text": "Hello World", "id": "1"}
], mode="overwrite")
vector_store = LanceDB.from_documents(doc_chunks, embeddings, connection=table)
vector_store_retriever = vector_store.as_retriever()
flare = FlareChain.from_llm(
llm=llm,
retriever=vector_store_retriever,
max_generation_len=300,
min_prob=0.45
)
# Define a function to generate FLARE output based on user input
def generate_flare_output(input_text):
output = flare.run(input_text)
return output
input = gr.Text(
label="Prompt",
show_label=False,
max_lines=1,
placeholder="Enter your prompt",
container=False,
)
iface = gr.Interface(fn=generate_flare_output,
inputs=input,
outputs="text",
title="My AI bot",
description="FLARE implementation with lancedb & bge embedding.",
allow_screenshot=False,
allow_flagging=False
)
iface.launch(debug=True)
Summary
FLARE, short for Forward-Looking Active Retrieval Augmented Generation, improves Large Language Models (LLMs) by actively incorporating external information to minimize false information in content creation. It outperforms conventional models by dynamically retrieving information from multiple sources and adjusting to changing contexts. FLARE Instruct and FLARE Direct demonstrate their ability to produce more precise and trustworthy content. The blog also discusses key implementation details and real-world uses utilizing LanceDB and vector databases.
Explore the full potential of this cutting-edge technology by visiting the vector-recipes. It’s filled with real-world examples, use cases, and recipes to inspire your next project. We hope you found this journey both informative and inspiring. Cheers!