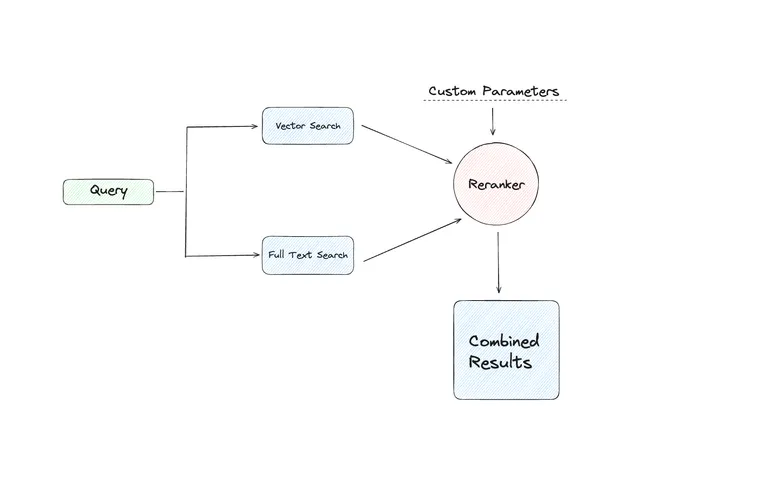
Have you ever thought about how search engines find exactly what you're looking for? They usually use a mix of looking for specific words and understanding the meaning behind them. This is called a hybrid search. Now, let's see how we can make a simple way to find documents using this mix.
Understanding BM25:
BM25 is a ranking algorithm used in information retrieval systems to estimate the relevance of documents to a given search query.
- What it does: It looks at how often your search words appear in a document and considers the document length to provide the most relevant results.
- Why it’s useful: It’s perfect for sorting through huge collections of documents, like a digital library, without bias towards longer documents or overused words.
Key elements of BM25:
- Term Frequency (TF): This counts how many times your search terms appear in a document.
- Inverse Document Frequency (IDF): This gives more importance to rare terms, making sure common words don’t dominate.
- Document Length Normalization: This ensures longer documents don’t unfairly dominate the results.
- Query Term Saturation: This stops excessively repeated terms from skewing the results.
Overall
score(d, q) = ∑(tf(i, d) * idf(i) * (k1 + 1)) / (tf(i, d) + k1 * (1 - b + b * (dl / avgdl)))
When is BM25/ Keyword search Ideal?
- Large Document Collections: Perfect for big databases where you need to sort through lots of information.
- Preventing Bias: Great for balancing term frequency and document length.
- General Information Retrieval: Useful in various search scenarios, offering a mix of simplicity and effectiveness.
Practical Application: Building a Hybrid Search System
Imagine you’re crafting a search system for a large digital library. You want it not only to find documents with specific keywords but also to grasp the context and semantics behind each query. Here’s how:
- Step 1: BM25 quickly fetches documents with the search keywords.
- Step 2: VectorDB digs deeper to find contextually related documents.
- Step 3: The Ensemble Retriever runs both systems, combines their findings, and reranks the results to present a nuanced and comprehensive set of documents to the user.
What Exactly is Hybrid Search?
Hybrid search can be imagined as a magnifying glass that doesn’t just look at the surface but delves deeper. It’s a two-pronged approach:
- Keyword Search: This is the age-old method we’re most familiar with. Input a word or a phrase, and this search hones in on those exact terms or closely related ones in the database or document collection.
- Vector Search: Unlike its counterpart, vector search isn’t content with mere words. It works using semantic meaning, aiming to discern the query’s underlying context or meaning. This ensures that even if your words don’t match a document exactly if the meaning is relevant, it’ll be fetched.
Follow along with Google Colab


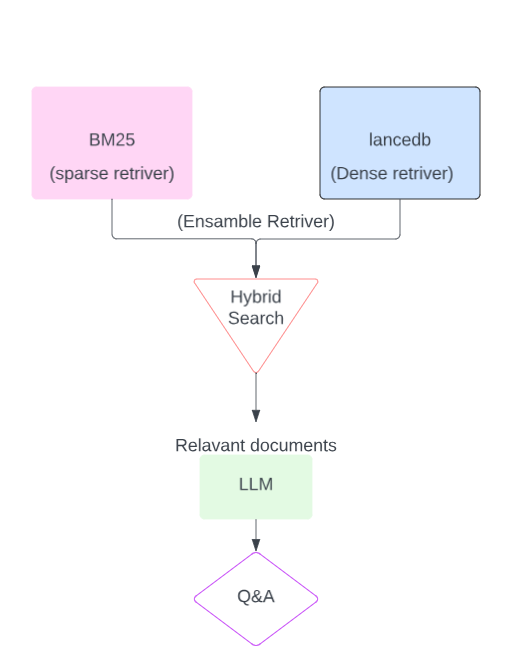
Let’s get to the code snippets. Here we’ll use langchain with LanceDB vector store
# example of using bm25 & lancedb -hybrid serch
from langchain.vectorstores import LanceDB
import lancedb
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.schema import Document
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.document_loaders import PyPDFLoader
# Initialize embeddings
embedding = OpenAIEmbeddings()and load a single PDF.
# load single pdf
loader = PyPDFLoader("/content/Food_and_Nutrition.pdf")
pages = loader.load_and_split()Create BM25 sparse keyword matching retriever
# Initialize the BM25 retriever
bm25_retriever = BM25Retriever.from_documents(pages)
bm25_retriever.k = 2 # Retrieve top 2 resultsCreate a LanceDB vector store for dense semantic search/retrieval.
db = lancedb.connect('/tmp/lancedb')
table = db.create_table("pandas_docs", data=[
{"vector": embedding.embed_query("Hello World"), "text": "Hello World", "id": "1"}
], mode="overwrite")
# Initialize LanceDB retriever
docsearch = LanceDB.from_documents(pages, embedding, connection=table)
retriever_lancedb = docsearch.as_retriever(search_kwargs={"k": 2})Now ensemble both retrievers, here you can assign the weightage to it.
# Initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, retriever_lancedb],
weights=[0.4, 0.6])
# Example customer query
query = "which food needed for building strong bones and teeth ?
which Vitamin & minerals importat for this?"
# Retrieve relevant documents/products
docs = ensemble_retriever.get_relevant_documents(query)Using an ensemble retriever, it's trying to search each word in documents, such as strong bones & teeth as well as also searching using lancedb which will find the most similar documents based on similarity.
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(openai_api_key="sk-yourapikey")
#if you want to use opensource models such as lama,mistral check this
# https://github.com/lancedb/vectordb-recipes/blob/main/tutorials/chatbot_using_Llama2_&_lanceDB
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=ensemble_retriever)
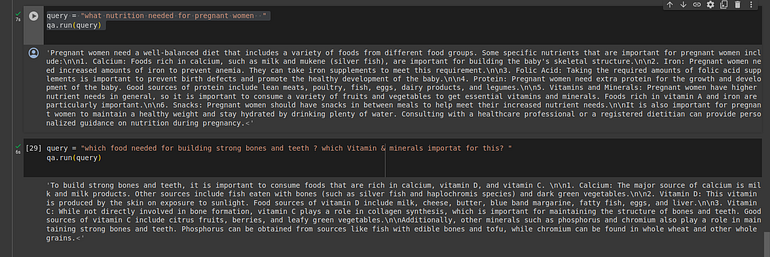
query = "what nutrition needed for pregnant women "
qa.run(query)again, here it's searching the keyword — “ nutrition pregnant women” in the database using bm25 & returning the best matching results & similarly, at the same time, we are using lancedb for this. this is how it's more powerful to extract text.

below are answers from the traditional rag, you can check this in our repo the answers may vary based on different parameters, models, etc.
you can try this on Google Colab with your PDF & use case. This is how you can use hybrid search to improve your search quality.
Explore More with Our Resources
Discover the full potential of hybrid search and beyond in our lancedb repository, offering a setup-free, persisted vectordb that scales on on-disk storage. For a deep dive into applied GenAI and vectordb applications, examples, and tutorials, don’t miss our vectordb-recipes. From advanced RAG methods like Flare, Rerank, and HyDE to practical use cases, our resources are designed to inspire your next project.