
An untold story about how we make LanceDB vector search fast.
In January, the engineering team here at Eto made the decision to rewrite the Lance columnar format in Rust. While this decision may seem like the usual “Rewrite-X-In-Rust” trend, there is an untold story behind it: Our goal was to achieve excellent performance in the recently announced SSD-resilient vector search in LanceDB. Rust’s native code-generation, great toolchain for performance tuning ( cargo asm / cargo flamegraph ), as well as the vast amount of first-class CPU intrinsics/SIMD support in the standard library (std::arch ), heavily influenced our decision.
The most fundamental query in vector search is “finding K-nearest-neighbors (KNN) in a high-dimensional vector space”. To execute this search, the distances between vectors must be computed. In this article, we will use the classic Euclidean Distance (L2) as an example. Other popular distance measures include Cosine Distance, Dot Product, and Hamming Distance.
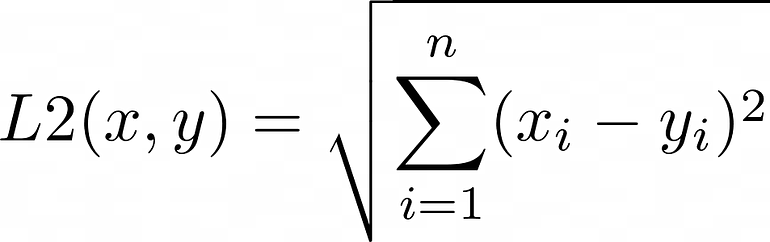
First attempt: Naive Implementation and Let Compiler do it
L2 distance is quite straightforward to implement in Rust.
pub fn l2(x: &[f32], y: &[f32]) -> f32 {
x.iter()
.zip(y.iter())
.map(|(a, b)| (a - b).powi(2))
.sum::<f32>()
}Computing L2 between one query vector (1024 dimension) to 1 million vectors takes 1.25s on a AWS Compute Optimized Instance(C6in.4xlarge).
Rust compiler rustc (1.68)does a pretty decent code-generation for the above code, as shown in the Compiler Explorer with RUSTFLAGS=-C opt-level=3 -C target-cpu=icelake-server -C target-feature=+avx2: loop-unrolling is kicked in:
/// RUSTFLAGS="-C opt-level=3 -C target-cpu=icelake-server"
...
.LBB0_5:
vmovss xmm1, dword ptr [rdi + 4*rsi]
vmovss xmm2, dword ptr [rdi + 4*rsi + 4]
vsubss xmm1, xmm1, dword ptr [rdx + 4*rsi]
vmulss xmm1, xmm1, xmm1
vaddss xmm0, xmm0, xmm1
vsubss xmm1, xmm2, dword ptr [rdx + 4*rsi + 4]
vmulss xmm1, xmm1, xmm1
vaddss xmm0, xmm0, xmm1
vmovss xmm1, dword ptr [rdi + 4*rsi + 8]
vsubss xmm1, xmm1, dword ptr [rdx + 4*rsi + 8]
vmulss xmm1, xmm1, xmm1
vaddss xmm0, xmm0, xmm1
vmovss xmm1, dword ptr [rdi + 4*rsi + 12]
vsubss xmm1, xmm1, dword ptr [rdx + 4*rsi + 12]
vmulss xmm1, xmm1, xmm1
vaddss xmm0, xmm0, xmm1
vmovss xmm1, dword ptr [rdi + 4*rsi + 16]
vsubss xmm1, xmm1, dword ptr [rdx + 4*rsi + 16]
vmulss xmm1, xmm1, xmm1
vaddss xmm0, xmm0, xmm1
vmovss xmm1, dword ptr [rdi + 4*rsi + 20]
vsubss xmm1, xmm1, dword ptr [rdx + 4*rsi + 20]
vmulss xmm1, xmm1, xmm1
vaddss xmm0, xmm0, xmm1
vmovss xmm1, dword ptr [rdi + 4*rsi + 24]
vsubss xmm1, xmm1, dword ptr [rdx + 4*rsi + 24]
vmulss xmm1, xmm1, xmm1
vaddss xmm0, xmm0, xmm1
vmovss xmm1, dword ptr [rdi + 4*rsi + 28]
lea rax, [rsi + 8]
vsubss xmm1, xmm1, dword ptr [rdx + 4*rsi + 28]
vmulss xmm1, xmm1, xmm1
vaddss xmm0, xmm0, xmm1
mov rsi, rax
cmp rcx, rax
jne .LBB0_5
...People often say, “let the compiler optimize the code for you”. Unfortunately, vsubss/vaddss/vmulss are the scalar instructions on X86_64. It appears that LLVM does not auto-vectorization the loop. It has been discovered that it would be quite challenging for LLVM/GCC to vectorize loops without a static length at compiling time. But our vector index MUST support any dimension of user vectors, did we just leave some performance on the table?
Second Attempt: Arrow Compute Kernel
LanceDB is built on top of Apache Arrow (Rust), can we do better by using Arrow compute kernels directly?
// RUSTFLAGS="-C target-cpu=native -C target-feature=+avx2"
// Use arrow arith kernels.
use arrow_arith::arithmetic::{multiply, subtract};
use arrow_arith::arity::binary;
#[inline]
fn l2_arrow_1(x: &Float32Array, y: &Float32Array) -> f32 {
let s = subtract(x, y).unwrap();
let m = multiply(&s, &s).unwrap();
sum(&m).unwrap()
}
#[inline]
fn l2_arrow_2(x: &Float32Array, y: &Float32Array) -> f32 {
let m: Float32Array = binary(x, y, |a, b| (a - b).powi(2)).unwrap();
sum(&m).unwrap()
}Running on the same c6in.4xlarge machine with RUSTFLAGS=”-C target-cpu=native -C target-feature=+avx2” , we got 2.81s and 2.16s respectively. Surprisingly, using arrow compute kernel is slower than our naive implementation. The reason being that, unlike the native L2 function that has zero memory allocation and only scan x and y once, which only invalid the L1 cache when it is absolutely necessary. l2_arrow_1 requires scanning over x, y, m, sarray once, invaliding L1/L2 cache twice, and two extra memory allocations for s and m. l2_arrow_2 scans x, yonce, thus better cache behavior, and only requires one extra memory allocation.
Third Attempt: BLAS to rescue?
Many scientific computing libraries are using BLAS underneath to accelerate the matrix / vector compute. LanceDB actually uses BLAS in some places too!
Especially, numpy is well-regard as well-optimized for linear algebra algorithms. We use Numpy + Intel MKL, one of the fastest BLAS library out there to benchmark BLAS performance.
>>> import numpy as np
>>> np.show_config()
blas_armpl_info:
NOT AVAILABLE
blas_mkl_info:
libraries = ['mkl_rt', 'pthread']
library_dirs = ['/home/ubuntu/miniconda3/envs/np-mkl/lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['/home/ubuntu/miniconda3/envs/np-mkl/include']
blas_opt_info:
libraries = ['mkl_rt', 'pthread']
library_dirs = ['/home/ubuntu/miniconda3/envs/np-mkl/lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['/home/ubuntu/miniconda3/envs/np-mkl/include']
lapack_armpl_info:
NOT AVAILABLE
lapack_mkl_info:
libraries = ['mkl_rt', 'pthread']
library_dirs = ['/home/ubuntu/miniconda3/envs/np-mkl/lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['/home/ubuntu/miniconda3/envs/np-mkl/include']
lapack_opt_info:
libraries = ['mkl_rt', 'pthread']
library_dirs = ['/home/ubuntu/miniconda3/envs/np-mkl/lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['/home/ubuntu/miniconda3/envs/np-mkl/include']
Supported SIMD extensions in this NumPy install:
baseline = SSE,SSE2,SSE3
found = SSSE3,SSE41,POPCNT,SSE42,AVX,F16C,FMA3,AVX2,AVX512F,AVX512CD,AVX512_SKX,AVX512_CLX,AVX512_CNL,AVX512_ICL
not found = AVX512_KNL,AVX512_KNMRunning a simple python script on the same AWS c6in instance takes 5.498s
import numpy as np
import time
x = np.random.random((1, 1024))
y = np.random.random((1024*1024, 1024))
total = 10
start = time.time()
for i in range(total):
d = np.linalg.norm(y - x, axis=1)
print("time: {}s".format((time.time() - start) / total))Last Attempt: Can we squeeze every penny out of a Modern CPU?
Our philosophy of building a LanceDB serverless Vector DB is to fully utilize modern hardware capabilities.
Modern CPUs are extraordinarily capable. We strongly believe that we can do better to utilize CPU.
We re-write the L2 distance computation using Intel AVX-2 instructions in std::arch::x86_64
use std::arch::x86_64::*;
#[inline]
pub(crate) fn l2_f32(from: &[f32], to: &[f32]) -> f32 {
unsafe {
// Get the potion of the vector that is aligned to 32 bytes.
let len = from.len() / 8 * 8;
let mut sums = _mm256_setzero_ps();
for i in (0..len).step_by(8) {
let left = _mm256_loadu_ps(from.as_ptr().add(i));
let right = _mm256_loadu_ps(to.as_ptr().add(i));
let sub = _mm256_sub_ps(left, right);
// sum = sub * sub + sum
sums = _mm256_fmadd_ps(sub, sub, sums);
}
// Shift and add vector, until only 1 value left.
// sums = [x0-x7], shift = [x4-x7]
let mut shift = _mm256_permute2f128_ps(sums, sums, 1);
// [x0+x4, x1+x5, ..]
sums = _mm256_add_ps(sums, shift);
shift = _mm256_permute_ps(sums, 14);
sums = _mm256_add_ps(sums, shift);
sums = _mm256_hadd_ps(sums, sums);
let mut results: [f32; 8] = [0f32; 8];
_mm256_storeu_ps(results.as_mut_ptr(), sums);
// Remaining unaligned values
results[0] += l2_scalar(&from[len..], &to[len..]);
results[0]
}
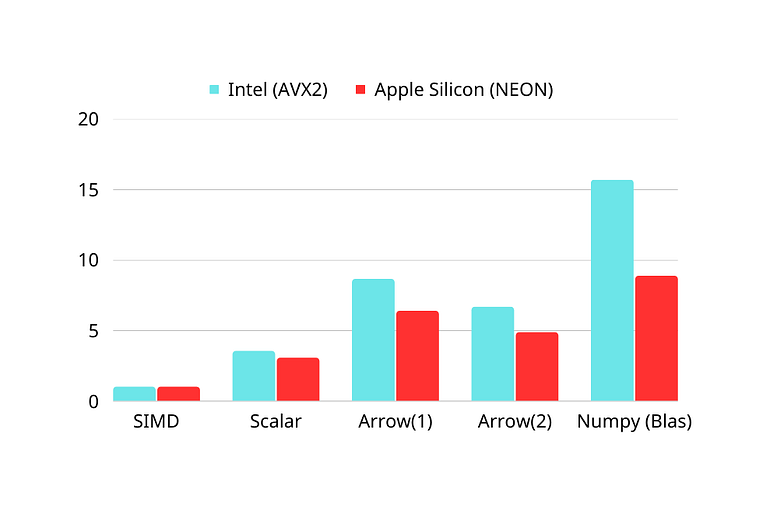
}This time, it only takes 0.325s to compute L2 distances over 1 million vectors, a 350% speed up to the closest alternatives!
We do not forget you, Apple Silicon!
Our team shares a love for Apple Silicon M1/M2 MacBooks. We are committed to making LanceDB the best-in-class performance option on the machines we use every single day.
Apple M1/M2 chips are based on Arm aarch64 architecture, with NEON instructions. Unfortunately, Arm Scalable Vector Extension (SVE) is not available on these chips yet. So, we have only implemented the NEON version of L2 distance.
use std::arch::aarch64::*;
#[inline]
pub(crate) fn l2_f32(from: &[f32], to: &[f32]) -> f32 {
unsafe {
let len = from.len() / 4 * 4;
let buf = [0.0_f32; 4];
let mut sum = vld1q_f32(buf.as_ptr());
for i in (0..len).step_by(4) {
let left = vld1q_f32(from.as_ptr().add(i));
let right = vld1q_f32(to.as_ptr().add(i));
let sub = vsubq_f32(left, right);
sum = vfmaq_f32(sum, sub, sub);
}
let mut sum = vaddvq_f32(sum);
sum += l2_scalar(&from[len..], &to[len..]);
sum
}
}This NEON-accelerate L2 implementation only takes 0.299s to compute 1 million distances on a M2 Max MacBook Pro.
For the sake of completeness in benchmarking, we also ran the same numpy script on a Macbook Pro using the Apple Accelerate Framework for BLAS. We’ve seen similar 3–15x speed ups by manually tuning the SIMD instructions across the CPU architectures ( x86_64 and apple-silicon (aarch64) ).
What will the future of LanceDB look like
Even though we’ve already significantly accelerated vector computations using our SIMD implementation, there’s still much more we can do to make LanceDB run even faster:
- Add AVX-512 routines for widen bit-width vectorization.
- Support
bf16, f64floats vectors. - CUDA and Apple Silicon GPU acceleration.
- Improve PQ / OPQ code cache efficiency.
Once the std::simd / portable SIMD project is available in stable Rust, we would definitely migrate to use std::simd for simplicity.
Additionally, because LanceDB is an SSD-resilient and serverless Vector Database, there are many more I/O path optimizations that can be done specially for NVME SSDs.
The rich Rust ecosystem gives us enormous power to write cross-platform hardware-accelerate with ease, would especially thank the Rust community in:
std::arch::{x86_64, aarch64}covers majority of our use cases in the stable Rust toolchain.cargo bench+pprof(https://github.com/tikv/pprof-rs) make benchmarks easy to maintain and inspect. It is the foundation of our continuous benchmarking effort.cargo asm(https://github.com/pacak/cargo-show-asm) to check the code-generation on bothx86_64andaarch64CPUs, so we can check whether auto-vectorization and other compiler optimizations are active.Compiler Explorer(https://godbolt.org/) is another tool for us to understand compiler optimizations better.cargo flamegraph(https://github.com/flamegraph-rs/flamegraph) makes it super easy to work withflamegraph. If you have usedflamegraph.plin C/C++ project before , I am sure you will appreciateflamegraph-rsproject sincerely.
Give LanceDB a try!
If you like the idea of LanceDB , you can try it today by simply pip install lancedb . And please gives us a 🌟 on our Github Repo!