A couple of weeks ago, OpenAI launched their new and most performant embedding models with higher multilingual performance and new parameters to control the overall size, updated moderation models, API usage management tools, and reduced pricing for GPT-3.5 Turbo.
Embeddings are numeric representations of content, such as text or code. This helps machine learning models understand semantic relationships with data points and perform similarity-based retrieval. Embeddings are used in knowledge retrieval tasks, especially in Retrieval Augmented Generation (RAG) for systems like ChatGPT, Bard, and other related tasks.
The newly launched OpenAI's Embedding models text-embedding-3-small and text-embedding-3-large, have generated considerable interest due to their higher multilingual performance and new parameter dimensions to control the overall size of embeddings. text-embedding-3-small returns embeddings of 1536-dimensional vector size same as older embedding model text-embedding-ada-002 and text-embedding-3-large returns embeddings of 3072-dimensional vector size.
We’ll see performance improvement with and without dimensionality reduction features.
The latest embedding model text-embedding-3-smallis highly efficient and represents a significant improvement compared to its predecessor, the text-embedding-ada-002 model released in December 2022.
Performance Increase
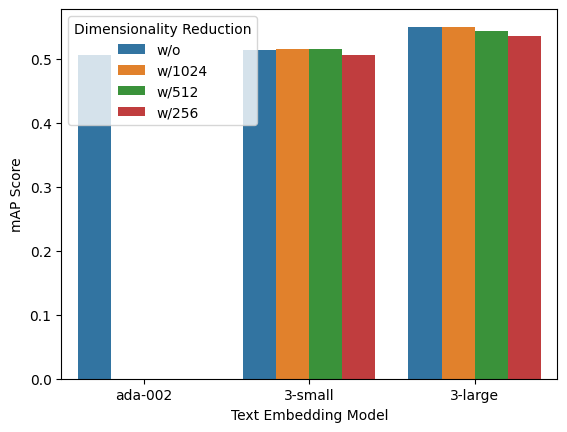
While Comparing text-embedding-ada-002 to text-embedding-3-small, the average score on a commonly used benchmark for English tasks (MTEB) using the StackOverflowDupQuestions task shows an increase from 50.5% to 51.4%.
Native support for Dimensionality Reduction
Using larger embeddings and storing them in a vector store for retrieval generally costs more and consumes more computing, memory, and storage than smaller embeddings.
Length of embeddings (by omitting specific numbers from the end of the sequence) without compromising their ability to represent concepts. This can be performed by utilizing the dimensions API parameter. In the MTEB benchmark, an text-embedding-3-large embedding can be reduced to a size of 256 and still exhibit performance compared to an text-embedding-ada-002 embedding with a size of 1536.
Here are the Results of the MTEB benchmark on the StackOverflowDupQuestions task.
OpenAI Embedding Models with LanceDB

The new OpenAI embedding models work well with LanceDB. Combining these developer-friendly embedding models with LanceDB’s vector database is excellent for tasks like Semantic Search, Knowledge Retrieval, and many other applications.
OpenAI embeddings function can be called via LanceDB while creating a table that implicitly converts text into OpenAI embeddings and adds them in the table in the following way using Python, which gives the flexibility to use the vectorized text across all sessions.
import lancedb
from lancedb.embeddings import EmbeddingFunctionRegistry
db = lancedb.connect("/tmp/db")
registry = EmbeddingFunctionRegistry.get_instance(name="text-embedding-3-small")
func = registry.get("openai").create()
class Words(LanceModel):
text: str = func.SourceField()
vector: Vector(func.ndims()) = func.VectorField()
table = db.create_table("words", schema=Words)
table.add(
[
{"text": "hello world"}
{"text": "goodbye world"}
]
)
query = "greetings"
actual = table.search(query).limit(1).to_pydantic(Words)[0]
print(actual.text)
The OpenAI embedding function is already ingested in the table. It doesn’t require loading it again while adding text to the table.
table = db.open_table("words")
# Automatically vectorized text across all sessions
table.add(
[{"text": "changing world"}])
query = "world"
result = table.search(query).limit(1).to_pydantic(Words)[0]
print(result.text)Conclusion
This was a short intro to new OpenAI embedding models and how LanceDB’s Embedding API simplifies working with embedding functions. Check out other interesting blogs and solutions on vectordb-recipes.