
A Practical Guide to Fine-Tuning LLM using QLora
Conducting inference with large language models (LLMs) demands significant GPU power and memory resources, which can be prohibitively expensive. To enhance inference performance and speed, it is imperative to explore lightweight LLM models. Researchers have developed a few techniques. In this blog, we’ll delve into these essential concepts that enable cost-effective and resource-efficient deployment of LLMs.
What is Instruction Fine-Tuning?
Instruction fine-tuning is a critical technique that empowers large language models (LLMs) to follow specific instructions effectively. When we begin with a base model, pre-trained on an immense corpus of worldly knowledge, it boasts extensive knowledge but might not always comprehend and respond to specific prompts or queries. In essence, it requires fine-tuning to tailor its behavior.
When Does Instruction Fine-Tuning Work?
Instruction fine-tuning shines in specific scenarios:
- Precision Tasks: When precision in responses is paramount, such as classifying, summarizing, or translating content, instruction fine-tuning significantly enhances accuracy.
- Complex Tasks: For intricate tasks involving multiple steps or nuanced understanding, instruction fine-tuning equips the model to generate meaningful outputs.
- Domain-Specific Tasks: In specialized domains, instruction fine-tuning enables the model to adapt to unique language and context.
- Tasks Requiring Improved Accuracy: When base model responses require refinement for higher accuracy, instruction fine-tuning becomes invaluable.
When Might Instruction Fine-Tuning Fall Short?
Despite its advantages, instruction fine-tuning may face challenges in specific situations:
- Smaller Models: Instruction fine-tuning can be tough for smaller LLMs with fewer parameters, impacting performance.
- Limited Space in Prompts: Long examples or instructions in prompts may reduce space for essential context.
- High Memory and Compute Demands: Full fine-tuning, and updating all model weights, needs significant memory and computation, which may not work in resource-limited setups.
Mitigating Catastrophic Forgetting in Fine-Tuning
While instruction fine-tuning is a potent tool for boosting LLM performance, it’s crucial to address a potential challenge called catastrophic forgetting. This issue can affect the model’s ability to generalize to other tasks, necessitating strategies to minimize its impact.
When Does Catastrophic Forgetting Occur?
Catastrophic forgetting usually arises during fine-tuning when an LLM is optimized for a single task, potentially erasing or degrading its prior capabilities. For example, fine-tuning a sentiment analysis task may lead the model to struggle with tasks it previously excelled at, like named entity recognition.
Options to Address Catastrophic Forgetting: To mitigate or prevent catastrophic forgetting, consider these approaches:
1. Task-Specific Multitask Fine-Tuning: When aiming to preserve a model’s multitask capabilities and prevent catastrophic forgetting, you can opt for task-specific multitask fine-tuning. This approach involves fine-tuning multiple tasks simultaneously, ensuring the model maintains its versatility. However, it comes with a requirement for a substantial dataset containing examples across various tasks.
i) Single Task Fine-Tuning Example: Imagine you have a base model and a specific task, such as sentiment analysis. Single-task fine-tuning involves optimizing the model exclusively for this task, resulting in improved performance in sentiment analysis. However, this process may lead to forgetting other tasks it previously excelled in.
ii)Multitask Fine-Tuning Example — FLAN-T5: FLAN-T5 serves as an excellent example of multitask fine-tuning. It’s a multitask fine-tuned version of the T5 foundation model. FLAN-T5 has been trained on a diverse range of datasets and tasks, encompassing 473 datasets across 146 task categories. This extensive multitask fine-tuning equips FLAN-T5 to excel in various tasks simultaneously, making it a versatile and capable model.
2. Parameter Efficient Fine-Tuning (PEFT): PEFT offers a more memory-efficient alternative to full fine-tuning. It preserves most of the original LLM’s weights while training only a small number of task-specific adapter layers and parameters. We’ll explore PEFT further in this blog series.
Parameter Efficient Fine-Tuning (PEFT): Making LLMs More Efficient
Training large language models (LLMs) is a computational behemoth. Full fine-tuning, where all model weights are updated during supervised learning, demands immense memory capacity, including storage for model weights, optimizer states, gradients, forward activations, and temporary memory throughout the training process. This memory load can swiftly surpass what’s feasible on consumer hardware.
In contrast, parameter-efficient fine-tuning (PEFT) methods offer an elegant solution. PEFT strategically targets only a fraction of the model’s parameters for modification, significantly reducing memory requirements. Here’s why PEFT matters:
- Focused Parameter Updates: PEFT targets specific model parameters, reducing memory load.
- Memory Efficiency: PEFT keeps most LLM weights frozen, using only a fraction of the original model’s parameters, making it suitable for limited hardware.
- Catastrophic Forgetting Mitigation: PEFT minimizes the risk of catastrophic forgetting.
- Adaptation to Multiple Tasks: PEFT efficiently adapts to various tasks without significant storage demands.
PEFT Methods:
- Selective Methods: Fine-tune a subset of LLM parameters, offering a balance between parameter efficiency and computational cost.
- Reparameterization Methods: Reduce trainable parameters by creating new low-rank transformations of existing LLM weights, we can use LoRA, QLora methods
- Additive Methods: Keep original LLM weights frozen and introduce new trainable components, such as adapter layers or soft prompt methods.
Stay tuned as we explore specific PEFT techniques like prompt tuning and LoRA to understand how they reduce memory requirements during LLM fine-tuning.
Now we’ll delve into specific PEFT techniques QLora, a deeper understanding of how these methods reduce memory requirements during LLM fine-tuning
LoRA (Low-rank Adaptation): Reducing Memory for LLM Fine-Tuning
Low-rank Adaptation, or LoRA, is a parameter-efficient fine-tuning technique categorized under re-parameterization methods. LoRA aims to drastically cut down the number of trainable parameters while fine-tuning large language models (LLMs). Here’s a closer look at how LoRA works:
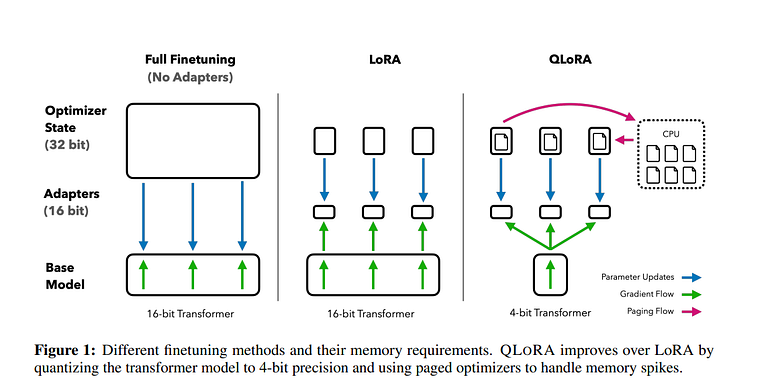
Understanding the Transformer Architecture: To appreciate LoRA, let’s revisit the fundamental architecture of a transformer model. The transformer architecture consists of an encoder and/or decoder part, each containing self-attention and feedforward networks. These components have weights that are initially learned during pre-training.
Reducing Parameters with LoRA: LoRA employs a smart strategy — that freezes all the original model parameters and introduces a pair of rank decomposition matrices alongside the existing weights. The key steps in LoRA are as follows:
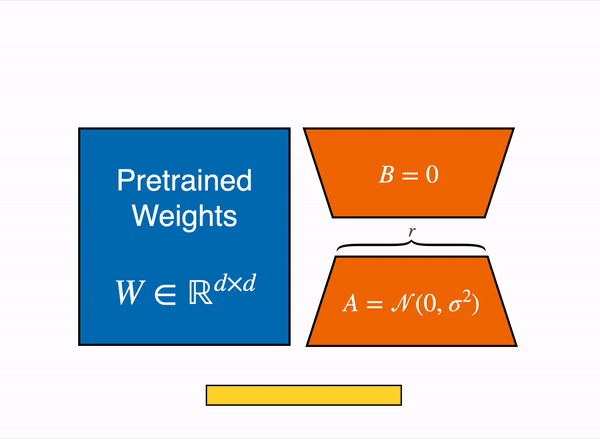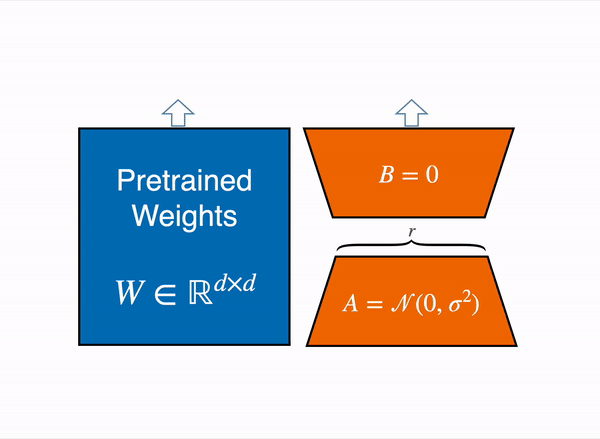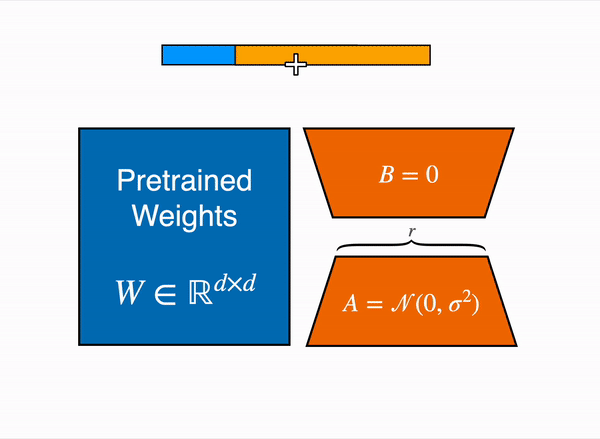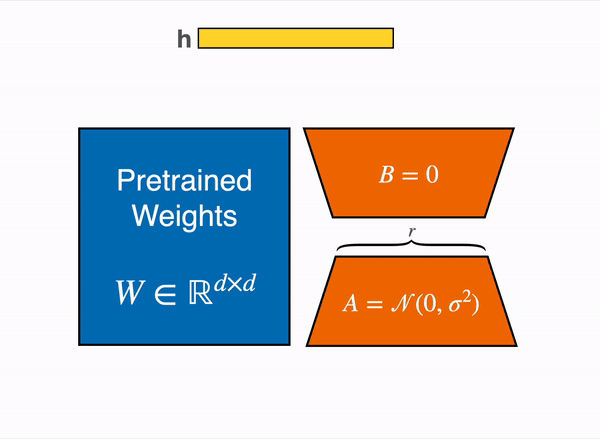
- Low-Rank Matrices: LoRA introduces two low-rank matrices, Matrix A and Matrix B, alongside the original LLM weights.
- Matrix Dimensions: The dimensions of these smaller matrices are carefully set so that their product results in a matrix of the same dimensions as the weights they’re modifying.
- Training Low-Rank Matrices: During fine-tuning, you keep the original LLM weights frozen while training Matrix A and Matrix B using supervised learning, a process you’re already familiar with.
- Inference: For inference, you multiply the two low-rank matrices together to create a matrix with the same dimensions as the frozen weights. You then add this new matrix to the original weights and replace them in the model.
- Significant Parameter Reduction: One of LoRA’s remarkable features is its ability to substantially reduce the number of trainable parameters. To put this into perspective, let’s consider an example based on the transformer architecture’s dimensions. A typical weights matrix in a transformer has 32,768 trainable parameters. If you apply LoRA with a rank of eight, you will train two small rank decomposition matrices. Matrix A with dimensions 8 by 64 results in 512 trainable parameters, while Matrix B with dimensions 512 by 8 amounts to 4,096 trainable parameters. In total, you’re training just 4,608 parameters, which is an 86% reduction compared to the original.
Due to its parameter efficiency, LoRA can often be executed on a single GPU, eliminating the need for an extensive distributed GPU cluster. The memory required to store LoRA matrices is minimal, enabling fine-tuning for numerous tasks without the burden of storing multiple full-size LLM versions.
LoRA Performance: LoRA’s efficiency doesn’t come at the cost of performance. While the reduction in parameters might lead to slightly lower performance gains compared to full fine-tuning, LoRA still delivers impressive results, especially when compared to the base LLM model.
In practice, LoRA is an invaluable tool for efficiently fine-tuning LLMs and adapting them to specific tasks without overwhelming computational and memory resources. It strikes a balance between parameter efficiency and performance, making it a go-to technique for many natural language processing applications.
But wait, there’s a game-changer on the horizon — QLoRA.
What Is QLoRA?
QLoRA, which stands for Quantized Low-rank Adaptation, takes fine-tuning to the next level. It empowers you to fine-tune LLMs on a single GPU, pushing the boundaries of what’s possible. How does QLoRA differ from LoRA?
The paper introduces QLoRA, an efficient fine-tuning method that enables the training of a 65-billion-parameter language model on a single 48GB GPU while maintaining good performance. QLoRA leverages 4-bit quantization and Low-Rank Adapters (LoRA) to achieve this. The authors’ best model family, named Guanaco, outperforms previously released models on the Vicuna benchmark, reaching 99.3% of ChatGPT’s performance with just 24 hours of fine-tuning on a single GPU.
Key innovations in QLoRA include the use of a 4-bit NormalFloat (NF4) data type for normally distributed weights, double quantization to reduce memory usage, and paged optimizers to manage memory spikes. They fine-tune over 1,000 models using QLoRA and analyze instruction following and chatbot performance across various datasets, model types (LLaMA, T5), and scales (33B and 65B parameters).
Results show that QLoRA fine-tuning with a small high-quality dataset achieves state-of-the-art results, even with smaller models compared to previous state-of-the-art models. The paper also discusses chatbot performance, highlighting that GPT-4 evaluations can be a cost-effective alternative to human evaluation. Additionally, the authors question the reliability of current chatbot benchmarks for evaluating chatbot performance and present a comparative analysis between Guanaco and ChatGPT.
The authors have made their models and code, including CUDA kernels for 4-bit training, available to the public.
The QLoRA Advantage
QLoRA introduces innovative techniques that set it apart: Certainly, here’s a concise summary of QLORA’s key innovations:
QLora’s Memory-Efficient Innovations:
- 4-bit NormalFloat: QLORA introduces a quantization data type optimized for normally distributed data, achieving efficient compression with minimal information loss.
- Double Quantization: This technique quantizes the quantization constants, saving an average of about 0.37 bits per parameter, leading to significant memory savings in large models.
- Paged Optimizers: QLORA uses NVIDIA unified memory to tackle memory spikes during training, especially when processing long sequences, making it feasible to train large models without running into memory limitations.
These innovations collectively enable more efficient and memory-friendly training of large-scale language models, making QLORA a groundbreaking approach for AI research and development
Getting Hands-On with QLORA: Implementation and Fine-Tuning
Enough theory; it’s time to roll up our sleeves and dive into the exciting world of QLORA. In this hands-on session, we’ll walk through the steps to fine-tune a model using QLORA and save it in a quantized form. To achieve this, we’ll rely on two powerful libraries: Transformers and Bits & Bytes. These libraries are the cornerstone of implementing QLoRA, a remarkable evolution of the Low-Rank Adapter (LoRA) technique, supercharged with quantization.
But before we embark on this coding adventure, let’s make sure we have all the essential libraries in place. So, fasten your seatbelts as we take the first steps towards unleashing the full potential of QLORA in your AI projects.”
Library Setup:
To work with QLORA, we’ll use two essential libraries:
- Transformers: This library is crucial for handling pre-trained language models, including QLORA, and facilitates fine-tuning and deployment.
- Bits & Bytes: This is the core of QLORA’s functionality. It seamlessly integrates QLORA with Transformers, simplifying the process.
Additionally, we’ll harness the power of Hugging Face Accelerate, a library that optimizes training for large language models, ensuring faster and more efficient results.
!pip install -q -U trl transformers accelerate git+https://github.com/huggingface/peft.git
!pip install -q datasets bitsandbytes einops wandb
!pip install -Uqqq pip --progress-bar off
!pip install -qqq bitsandbytes==0.39.0 --progress-bar off
!pip install -qqq torch==2.0.1 --progress-bar off
!pip install -qqq -U git+https://github.com/huggingface/transformers.git@e03a9cc --progress-bar off
!pip install -qqq -U git+https://github.com/huggingface/peft.git@42a184f --progress-bar off
!pip install -qqq -U git+https://github.com/huggingface/accelerate.git@c9fbb71 --progress-bar off
!pip install -qqq datasets==2.12.0 --progress-bar off
!pip install -qqq loralib==0.1.1 --progress-bar off
!pip install -qqq einops==0.6.1 --progress-bar offimport json
import os
from pprint import pprint
import bitsandbytes as bnb
import pandas as pd
import torch
import torch.nn as nn
import transformers
from datasets import load_dataset
from huggingface_hub import notebook_login
from peft import (
LoraConfig,
PeftConfig,
PeftModel,
get_peft_model,
prepare_model_for_kbit_training,
)
from transformers import (
AutoConfig,
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
)We must include our Hugging Face token, ensure that it’s in write mode, and ultimately, use it to upload our model weights to the Hugging Face platform.
notebook_login()Download the sample dataset of e-commerce faq & we will finetune using this dataset
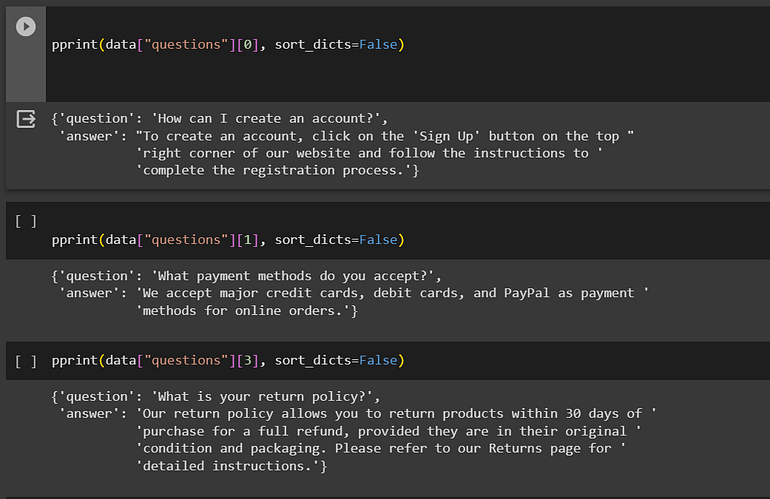
!gdown 1tiAscG941evQS8RzjznoPu8meu4unw5ACheck the few samples of data. we are using pprint library
pprint(data["questions"][0], sort_dicts=False)below is a data format of our FAQ-based dataset.
This structured dataset provides answers to common queries, ensuring a seamless shopping experience for our valued customers. & we are fine-tuning the model based on this data.
with open("dataset.json", "w") as f:
json.dump(data["questions"], f)Model selection
In our current approach, we have implemented a sharded model TinyPixel/Llama-2–7B-bf16-sharded which involves dividing a large neural network model into multiple smaller pieces, typically more than 14 pieces in our case. This sharding strategy has proven to be highly beneficial when combined with the ‘accelerate’ framework
When a model is sharded, each shard represents a portion of the overall model’s parameters. Accelerate can then efficiently manage these shards by distributing them across various parts of the memory, including GPU memory and CPU memory. This dynamic allocation of shards allows us to work with very large models without requiring an excessive amount of memory
MODEL_NAME = "TinyPixel/Llama-2-7B-bf16-sharded"Now, let’s explore the advanced usage of 4-bit quantization, a technique that can further optimize our model. Before diving in, let’s understand the key parameters and how to use them.
In our code, we make use of the BitsAndBytesConfig from the 'transformers' library and pass it as an argument to the quantization_config when calling from_pretrained. Don't forget to set load_in_4bit = True when using BitsAndBytesConfig.
Compute Data Type: By default, the compute data type used during computation is float32. However, you can change it to bf16 (bfloat16) for faster processing. For example, you might want to use bf16 it for computations while keeping hidden states in float32.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16, # Change this dtype for speedups.
)The 4-bit integration supports two quantization types: FP4 and NF4. FP4 stands for Fixed Point 4, while NF4 stands for Normal Float 4. The latter is introduced in the QLoRA paper. You can switch between these two types using the bnb_4bit_quant_type parameter. By default, FP4 quantization is used.
Finally, we load our model and tokenizer with these configurations:
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
trust_remote_code=True,
quantization_config=bnb_config,
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
tokenizer.pad_token = tokenizer.eos_token
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)This code snippet enables gradient checkpointing to reduce memory usage during training and then preparing the model for quantization
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)LoraConfig allows you to control how LoRA is applied to the base model through the following parameters:
from peft import LoraConfig, get_peft_model
lora_alpha = 16
lora_dropout = 0.1
lora_r = 64
config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
print_trainable_parameters(model)below are the hyperparameters we can choose; you can always do the experiments & select the best
generation_config = model.generation_config
generation_config.max_new_tokens = 80 # maxium no of token in output will get
generation_config.temperature = 0.7
generation_config.top_p = 0.7
generation_config.num_return_sequences = 1
generation_config.pad_token_id = tokenizer.eos_token_id
generation_config.eos_token_id = tokenizer.eos_token_id%%time
# Specify the target device for model execution, typically a GPU.
device = "cuda:0"
# Tokenize the input prompt and move it to the specified device.
encoding = tokenizer(prompt, return_tensors="pt").to(device)
# Run model inference in evaluation mode (inference_mode) for efficiency.
with torch.inference_mode():
outputs = model.generate(
input_ids=encoding.input_ids,
attention_mask=encoding.attention_mask,
generation_config=generation_config,
)
# Decode the generated output and print it, excluding special tokens.
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Now we can prepare prompts for text-generation tasks
def generate_prompt(data_point):
return f"""
: {data_point["question"]}
: {data_point["answer"]}
""".strip()
def generate_and_tokenize_prompt(data_point):
full_prompt = generate_prompt(data_point)
tokenized_full_prompt = tokenizer(full_prompt, padding=True, truncation=True)
return tokenized_full_prompt
data = data["train"].shuffle().map(generate_and_tokenize_prompt)create an output folder for saving all experiments
OUTPUT_DIR = "experiments"we are using TensorBoard for tracking our experiments.
%load_ext tensorboard
%tensorboard --logdir experiments/runsBelow are several training parameters. To explore all of them, please refer to the BitsAndBytesConfig
training_args = transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
num_train_epochs=1,
learning_rate=2e-4,
fp16=True,
save_total_limit=3,
logging_steps=1,
output_dir=OUTPUT_DIR,
max_steps=80,
optim="paged_adamw_8bit",
lr_scheduler_type="cosine",
warmup_ratio=0.05,
report_to="tensorboard",
)
trainer = transformers.Trainer(
model=model,
train_dataset=data,
args=training_args,
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False
trainer.train()
Trained model for a few epochs. now save the trained model
model.save_pretrained("trained-lama_model")now we are pushing our weights to Huggingface hub, so later we can use these weights for fine-tuning use your own directory name to push it into your HF repo.
model.push_to_hub(
"akashAD/Llama2-7b-qlora-chat-support-bot-faq", use_auth_token=True
)load the trained model
PEFT_MODEL = "akashAD/Llama2-7b-qlora-chat-support-bot-faq"
config = PeftConfig.from_pretrained(PEFT_MODEL)
model = AutoModelForCausalLM.from_pretrained(
config.base_model_name_or_path,
return_dict=True,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
tokenizer.pad_token = tokenizer.eos_token
model = PeftModel.from_pretrained(model, PEFT_MODEL)below are some experimental hyperparameters you can play with it to get the best results
generation_config = model.generation_config
generation_config.max_new_tokens = 50
generation_config.temperature = 0.3
generation_config.top_p = 0.7
generation_config.num_return_sequences = 1
generation_config.pad_token_id = tokenizer.eos_token_id
generation_config.eos_token_id = tokenizer.eos_token_id%%time
prompt = f"""
: How can I create an account?
:
""".strip()
encoding = tokenizer(prompt, return_tensors="pt").to(DEVICE)
with torch.inference_mode():
outputs = model.generate(
input_ids=encoding.input_ids,
attention_mask=encoding.attention_mask,
generation_config=generation_config,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))The below code utilizes our model to generate text responses from user questions, streamlining conversational AI interactions
def generate_response(question: str) -> str:
prompt = f"""
: {question}
:
""".strip()
encoding = tokenizer(prompt, return_tensors="pt").to(DEVICE)
with torch.inference_mode():
outputs = model.generate(
input_ids=encoding.input_ids,
attention_mask=encoding.attention_mask,
generation_config=generation_config,
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
assistant_start = ":"
response_start = response.find(assistant_start)
return response[response_start + len(assistant_start) :].strip()now let us ask questions to our model
prompt = "Can I return a product if it was a clearance or final sale item?"
print(generate_response(prompt))prompt = "What happens when I return a clearance item?"
print(generate_response(prompt))That's it; you can try to play with these hyperparameters to achieve better results.
Feel free to explore the power of LLMs on your own data with this Colab notebook
Summary
This blog explores instruction fine-tuning and mitigating catastrophic forgetting in large language models (LLMs). It covers how instruction fine-tuning improves LLMs for precision tasks but may face challenges with smaller models and resource constraints.
To tackle catastrophic forgetting, strategies like task-specific multitask fine-tuning and parameter-efficient fine-tuning (PEFT) are discussed, with a focus on PEFT’s memory efficiency.
The blog introduces LoRA (Low-rank Adaptation), a parameter-efficient fine-tuning technique, and QLoRA (Quantized Low-rank Adaptation), which enhances LoRA. It explains their benefits and differences.
A hands-on QLoRA implementation is demonstrated using Transformers and Bits & Bytes libraries, including model selection and training. Lastly, we covered saving and sharing trained models on the Hugging Face Hub and provided instructions for model loading and text generation tasks.
Stay tuned for upcoming blogs as we delve deeper into the world of Large Language Models (LLMs). Your support is greatly appreciated — leave a like if you found our exploration enlightening!
For a deeper dive into cutting-edge technology, explore the vector-recipes repository, brimming with real-world examples, use cases, and recipes to ignite your next project. We trust you found this journey informative and inspiring. Cheers!