by Rob Meng
Tantivy is a highly performant full text search library written in Rust. The python version of tantivy powers the full-text search (FTS) feature in LanceDB.
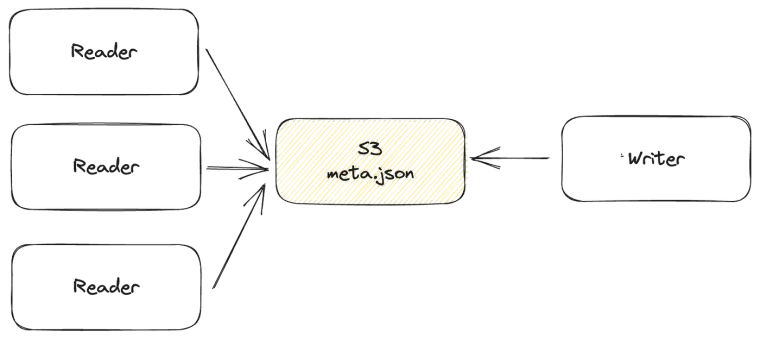
However, vanilla tantivy only supports building and searching index against a local directory. This is a problem for LanceDB Cloud, because we want to store data in and serve data from S3. In this article we will walk through the engineering challenges we encountered in making tantivy s3-compatible.
The work described in this article has been made available as OSS in this repo.
Note: this implementation depends on certain implementation details of tantivy, which could limit upgrade compatibility in the future.
Engineering Challenges
We ran into quite a few challenges during implementation, the most notable ones are:
- How can we ensure a distributed reader doesn’t read a dirty
meta.jsonfile? - Index build became incredibly slow with our first naive implementation.
- Index search also became slow with the naive implementation.
Implementing Copy on Write (CoW) for Tantivy
[!!!WARNING!!!]: While tantivy is unlikely to make major changes to its meta.json file or committing strategy anytime soon, this implementation relies on the fact that meta.json is the single source of truth for an index’s content. If meta.json no longer is the source of truth to an index, this implement would break and potentially cause data corruption.
The goal is to enable multiple distributed readers to read from the same index while making sure a writer can update the index without interrupptin the readers. This would allow us to run multiple LanceDB Cloud query node instances against the same FTS index.

Since there is only one meta.json file, the following could happen
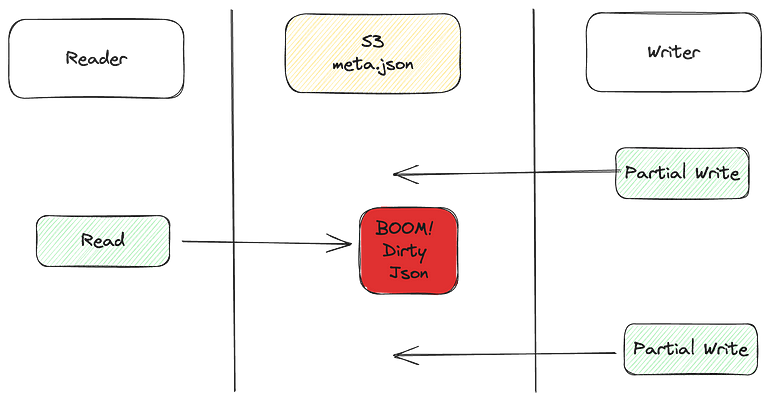
To avoid readers from reading partially written meta.json file, we decided to implement a CoW meta.json file. What does that mean? See this diagram.
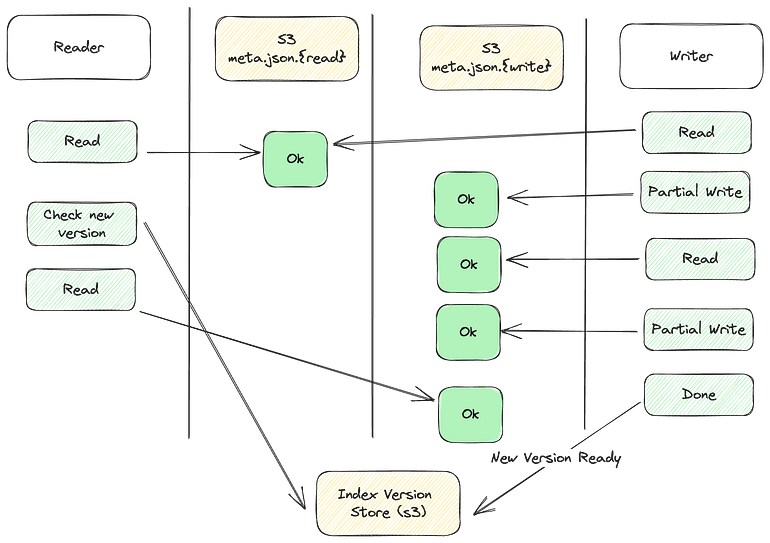
Read Path

On read path, we asynchronously check the latest version of the index. In the diagram above, we use a S3 file, updated by writer, to indicate the latest version of the an index. When a version change is detected, the reader switches to the new version.
Write Path
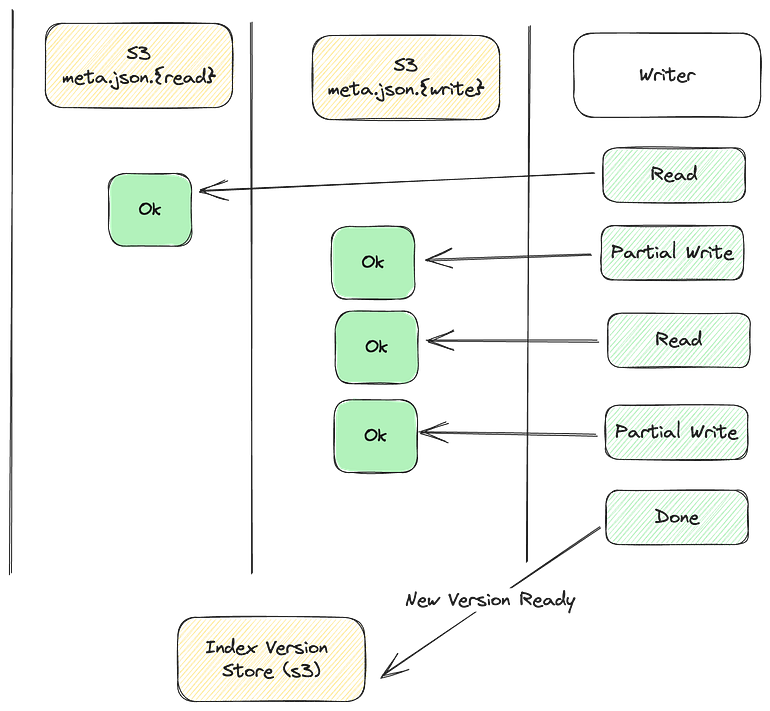
On the write path, we read from meta.json.{read}before the first write happens. This is because meta.json.{write} doesn’t exist yet. However, after the write, reads are routed to meta.json.{write} , as we have copied the file on write. Finally, when index update is complete, the writer updates the version file in s3.
With the above mechanism, we are able to guarantee that distributed readers can will only see immutable and complete meta.json files.
We will cover challenges with indexing and search latency in the next part of this series.