Sentiment Analysis also known as Opinion Mining is a NLP technique that is used to analyze texts for polarity, from positive to negative. It helps businesses to monitor customer feedback, product reputation, and social media sentiment.
For example, “I love this product” would have a high positive score, while “This is the worst service ever” would have a low negative score. Sentiment analysis can also detect emotions, sarcasm, and context in text, making it more accurate and near to human intelligence.
Methods of Sentiment Analysis
- Rule-based: This method performs sentiment analysis based on a set of manually crafted rules.
- Automatic: This method relies on ML/NLP techniques to learn from data.
- Hybrid: This approach combines both rule-based and automatic approaches.
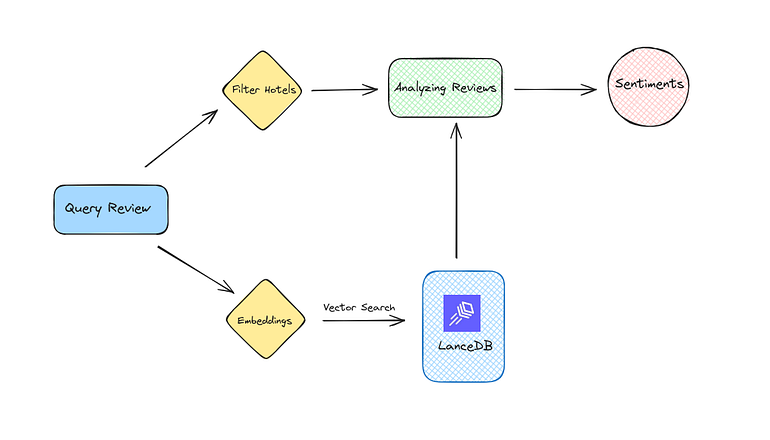
In this Blog, We’ll see an example to analyze sentiments toward the Hotel Industry and understand Customer Perception and Potential areas that need improvement. To do this, we will:
1. Generate Sentiment labels and scores using BERT models based on customer reviews.
2. Store them in a LanceDB table with metadata and their embeddings of customer reviews.
3. Query the LanceDB table on selected areas and understand customer opinions.
You can check out the attached Google Colab where you can find all codes and easy-to-quick-start steps.
Implementation
In the Implementation section, we see the step-by-step implementation of NER on the Medium dataset. We are starting with the first step of loading the hotel reviews dataset from huggingface.
from datasets import load_dataset
# load the dataset and convert to pandas dataframe
df = load_dataset(
"ashraq/hotel-reviews",
split="train"
).to_pandas()Once a dataset is loading, we’ll preprocess a loaded dataset, which will take only 1000 characters from the reviews.
# keep only the first 1000 characters from the reviews
df["review"] = df["review"].str[:1000]
# glimpse the dataset
df.head()These are basic preprocessing steps that I have performed, you can apply them further according to your datasets.
Now, we’ll initialize the Sentiment Analysis Model, we’ll use a RoBERTa or DistilBERT model fine-tuned for sentiment analysis to analyze the hotel reviews from the HuggingFace model hub
# set device to GPU if available
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# @title Select Sentiment Analysis Model and run this cell
model_id = "cardiffnlp/twitter-roberta-base-sentiment" # @param {type:"string"}
select_model = 'cardiffnlp/twitter-roberta-base-sentiment' # @param ["cardiffnlp/twitter-roberta-base-sentiment", "lxyuan/distilbert-base-multilingual-cased-sentiments-student"]
model_id = select_model
print("Selected Model: ", model_id)This code will create a dropdown in Google Colab from there you can select RoBERT or DistilBERT which sentiment analysis model you want to use for creating a sentiment analysis pipeline.
from transformers import (
pipeline,
AutoTokenizer,
AutoModelForSequenceClassification
)
# load the model from huggingface
model = AutoModelForSequenceClassification.from_pretrained(
model_id,
num_labels=3
)
# load the tokenizer from huggingface
tokenizer = AutoTokenizer.from_pretrained(model_id)
# load the tokenizer and model into a sentiment analysis pipeline
nlp = pipeline(
"sentiment-analysis",
model=model,
tokenizer=tokenizer,
device=device
)The sentiment analysis model returns LABEL_0 for negative, LABEL_1 for neutral and LABEL_2 for positive labels. We can add them to a dictionary to easily access them when showing the results.
labels = {
"LABEL_0": "negative",
"LABEL_1": "neutral",
"LABEL_2": "positive"
}Now we’ll test the sentiment analysis pipeline that we created using the BERT model
# view review number 241
test_review = df["review"][241]
test_reviewThis will output a review
Room was small for a superior room and poorly lit especially as
it was an inside room and overlooked the inside wall of the hotel
No view therefore needed better lighting within Restaurant tables
were not well laid and had to go searching for cutlery at breakfast # get the sentiment label and score for review number 241
nlp(test_review)This is how we’ll get results from the analysis pipeline
[{'label': 'LABEL_0', 'score': 0.7736574411392212}]Now, we have created an analysis Pipeline; the Next step is to Initialize the Retriever
A Retriever model is used to embed passages and queries, and it creates embeddings such that queries and passages with similar meanings are close in the vector space.
We will use a sentence-transformer model as our retriever. The model can be loaded as follows:
from sentence_transformers import SentenceTransformer
# load the model from huggingface
retriever = SentenceTransformer(
'sentence-transformers/all-MiniLM-L6-v2',
device=device
)Now let’s generate Embeddings and insert them inside LanceDB for querying
Connect LanceDB
import lancedb
db = lancedb.connect("./.lancedb")Let’s first write a helper function to generate sentiment labels and scores for a batch of reviews.
def get_sentiment(reviews):
# pass the reviews through sentiment analysis pipeline
sentiments = nlp(reviews)
# extract only the label and score from the result
l = [labels[x["label"]] for x in sentiments]
s = [x["score"] for x in sentiments]
return l, sLet’s write another helper function to convert dates to timestamps.
import dateutil.parser
# convert date to timestamp
def get_timestamp(dates):
timestamps = [dateutil.parser.parse(d).timestamp() for d in dates]
return timestampsNow generating embeddings and storing them in the table of LanceDB with their respective metadata
from tqdm.auto import tqdm
# we will use batches of 64
batch_size = 64
data = []
for i in tqdm(range(0, len(df), batch_size)):
# find end of batch
i_end = min(i+batch_size, len(df))
# extract batch
batch = df.iloc[i:i_end]
# generate embeddings for batch
emb = retriever.encode(batch["review"].tolist()).tolist()
# convert review_date to timestamp to enable period filters
timestamp = get_timestamp(batch["review_date"].tolist())
batch["timestamp"] = timestamp
# get sentiment label and score for reviews in the batch
label, score = get_sentiment(batch["review"].tolist())
batch["label"] = label
batch["score"] = score
# get metadata
meta = batch.to_dict(orient="records")
# create unique IDs
ids = [f"{idx}" for idx in range(i, i_end)]
# add all to upsert list
to_insert = list(zip(ids, emb, meta))
for id, emb, meta in to_insert:
temp = {}
temp['vector'] = emb
for k,v in meta.items():
temp[k] = v
data.append(temp)# create and insert these records to lancedb table
tbl = db.create_table("tbl", data, mode= "overwrite")We have successfully inserted all customer reviews and relevant metadata. We can move on to analyzing sentiments.
Now that we have all the customer reviews inserted, we will search for a few areas that customers usually consider when staying at a hotel and analyze the general opinion of the customers.
The LanceDB vector database makes it very flexible and faster to do this as we can easily search for any topic and get customer reviews relevant to the search query along with sentiment labels as metadata.
Let’s write another helper function to store the count of sentiment labels.
def count_sentiment(result):
# store count of sentiment labels
sentiments = {
"negative": 0,
"neutral": 0,
"positive": 0,
}
# iterate through search results
for r in result:
# extract the sentiment label and increase its count
sentiments[r["label"]] += 1
return sentimentsWe will start with a general question about the room sizes of hotels in London and return the top 100 reviews to analyze the overall customer sentiment.
Analyzing Room Size Reviews in London
query = "What is customers opinion about room sizes in London?"
# generate dense vector embeddings for the query
xq = retriever.encode(query).tolist()
# query lancedb
metadata = ["hotel_name", "label", "review", "review_date", "timestamp"]
result = tbl.search(xq).select(metadata).limit(100).to_list()
sentiment = count_sentiment(result)Plotting the results for better analysis
import seaborn as sns
# plot a barchart using seaborn
sns.barplot(x=list(sentiment.keys()), y = list(sentiment.values()))The resultant graph looks like this
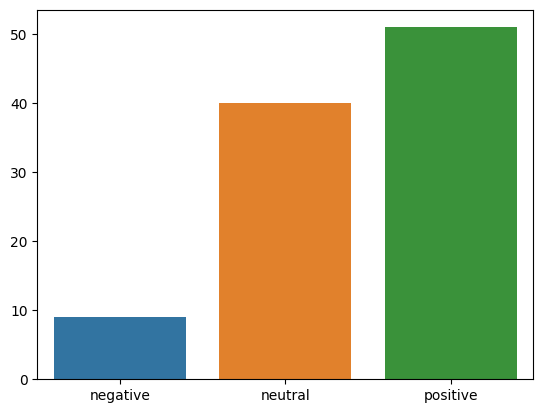
The customers are generally satisfied with the room sizes, although many are still neutral and positive.
Analyzing Room Size Reviews in a Specific Period
# generate timestamps for start and end time of the period
start_time = get_timestamp(["2015-01-01"])[0]
end_time = get_timestamp(["2017-12-31"])[0]query = "are the customers satisified with the room sizes of hotels in London?"
# generate query embeddings
xq = retriever.encode(query).tolist()
# query lancedb with query embeddings and appling prefiltering for given time period
where_filter = f"{start_time} <= timestamp <= {end_time}"
result = tbl.search(xq).where(where_filter, prefilter=True).limit(10).to_list()
# get an overall count of customer sentiment
sentiment = count_sentiment(result)
# plot a barchart using seaborn
sns.barplot(x=list(sentiment.keys()), y = list(sentiment.values()))The Resultant graph shows
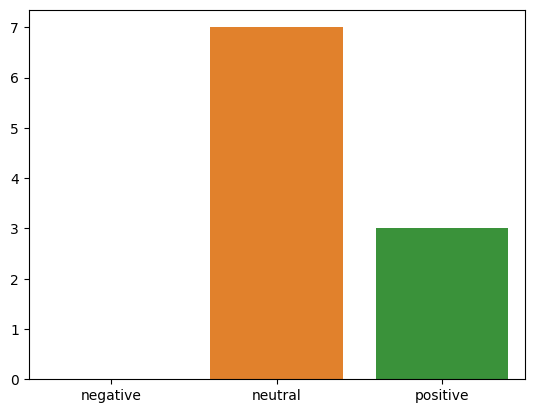
We have a slightly different result now. Almost the same number of customers had either a neutral or positive view of the room size during the selected period.
Further Basic Analysis is done in the attached Google Colab notebook at the end of this blog, which you can refer to.
Analyzing Multiple hotels at Multiple Grounds
Now Let’s multiple hotels together on multiple grounds to better understand the variation in reviews.
We have selected 5 Hotels for them we are analyzing 5 grounds which are Room Size, Cleanliness, Room Service, Food Service, and Ventilation.
#selected hotels
hotels =[
"Strand Palace Hotel",
"St James Court A Taj Hotel London",
"Grand Royale London Hyde Park",
"Hotel Da Vinci",
"Intercontinental London The O2",
]queries = {
"room size": "are customers happy with the given room sizes?",
"cleanliness": "are customers satisfied with the cleanliness of the rooms?",
"room service": "did the customers like how they were treated by the staff while room service?",
"food service": "did the customers enjoy the food and servicing?",
"ventilation": "customer opinion on the air passage and AC"
}Now, We need to iterate through all the hotels and run these queries for each hotel. This would give us customer reviews relevant to the selected hotel areas. After that, we count the sentiment labels and plot results for each hotel.
import matplotlib.pyplot as plt
import pandas as pd
hotel_sentiments = []
# iterate through the hotels
for hotel in hotels:
final_result = []
# iterate through the keys and values in the queries dict
for area, query in queries.items():
# generate query embeddings
xq = retriever.encode(query).tolist()
# query lancedb with query embeddings and appling prefiltering for hotel names
where_filter = f"hotel_name= '{hotel}'"
result = tbl.search(xq).where(where_filter, prefilter=True).limit(100).to_list()
# get an overall count of customer sentiment
sentiment = count_sentiment(result)
# sort the sentiment to show area and each value side by side
for k, v in sentiment.items():
analysis_data = {
"area": area,
"label": k,
"value": v
}
# add the data to final_result list
final_result.append(analysis_data)
#dataframe of final results
df = pd.DataFrame(final_result)
# mapping dataframe records with hotel
hotel_sentiments.append({"hotel": hotel, "df": df})We may now plot the final data to make inferences.
# create the figure and axes to plot barchart for all hotels
fig, axs = plt.subplots(nrows=1, ncols=5, figsize=(25, 4.5))
plt.subplots_adjust(hspace=0.25)
counter = 0
# iterate through each hotel in the list and plot a barchart
for d, ax in zip(hotel_sentiments, axs.ravel()):
# plot barchart for each hotel
sns.barplot(x="label", y="value", hue="area", data=d["df"], ax=ax, palette="Spectral")
# display the hotel names
ax.set_title(d["hotel"])
# remove x labels
ax.set_xlabel("")
# remove legend from all charts except for the first one
counter += 1
if counter != 1: ax.get_legend().remove()
# display the full figure
plt.show()This will plot results for all 5 hotels on all 5 grounds from which we’ll analyze it.
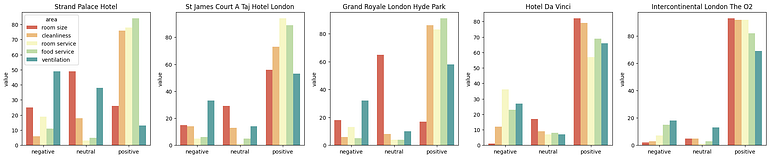
This can be better seen on Google Colab, which is attached at the end of this blog.
The following observations can be made for the hotels based on the sentiment analysis:
- Strand Palace Hotel: The majority of customers were pleased with the cleanliness, room service, and food service of the rooms, while a considerable number of them were not very satisfied with the room sizes and the ventilation in rooms.
- St James Court A Taj Hotel London: The majority of the customers were really happy with the selected five areas
- Grand Royale London Hyde Park: The majority of the customers were not satisfied with the room size, while a good number of them were pretty satisfied with the cleanliness, room service, food service, and ventilation of the rooms.
- Hotel Da Vinci: The majority of customers are happy with room sizes, cleanliness, food service, and ventilation but a considerable about of them are not satisfied with room service
- Intercontinental London The O2: the majority of the customers were really happy with the selected five areas, making this hotel the best among the selected hotels.
Although we have experimented with a few selected areas and hotels, you can get creative with your queries and get the sentiment around your area of interest with different sets of hotels immediately.
For quick and further analysis, You can try out Google Colab, which has all these codes
Some of the benefits of Hotel Review Analysis are:
- Monitor and respond to customer feedback and address any issues or complaints that may arise.
- Measure and improve the quality of their Services, Facilities, Amenities, and Staff, and Identify the areas that need more attention or improvement.
- Understand the needs and expectations of their Target market, and tailor their offerings and marketing strategies accordingly.
Conclusion
Sentiment Analysis is primarily using NLP and Deep Learning techniques. BERT is used in the Sentiment Analysis Pipeline and predicts Sentimens for reviews.
Using these two technologies, the model detects a sentiment of reviews. Harnessing the advanced vector search functionalities provided by LanceDB enhances its overall utility in analyzing the sentiments of reviews of different hotels on different grounds.